当前,大数据的理论和应用正在国民经济和生活的各个领域如火如荼的进行。很多人对大数据的基本概念和特点已经有所了解,那么我们仅仅将大数据进行获取、存储、检索和共享是不够的,怎么样才能在大数据中找出未知的且有价值的信息和知识呢?
知识发现(KDD)就是从大数据中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的过程。
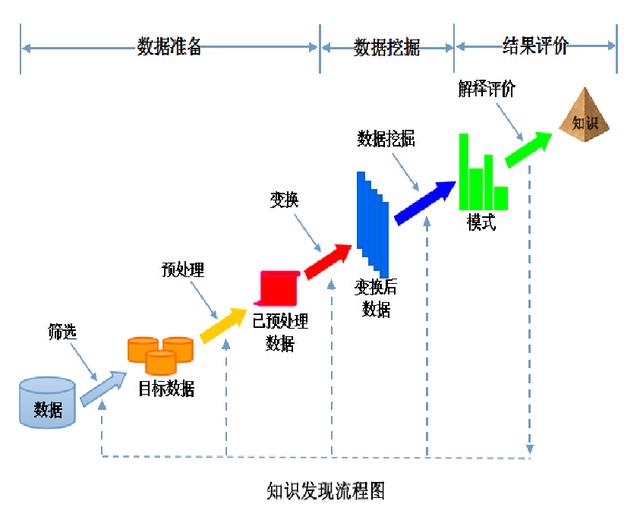
知识发现的流程图
数据挖掘是大数据知识发现(KDD)中不可缺少一部分,是大数据理论和应用中非常重要的一部分。数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但潜在的有用信息和知识的过程。大部分人是通过一个案例认识到数据挖掘:这是因为沃尔玛通过数据分析发现,男性顾客在购买婴儿尿片时,常常会顺便搭配几瓶啤酒来犒劳自己,于是尝试推出了将啤酒和尿布摆在一起的促销手段;没想到这个举措居然使尿布和啤酒的销量都大幅增加了。虽然这个故事很可能是假的, 但是确实让不少人开始接触数据挖掘。
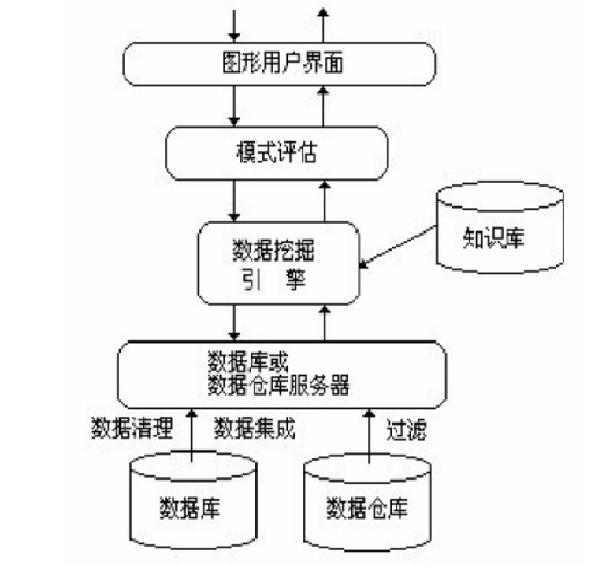
数据挖掘基本框架
数据挖掘的最常用的几种算法:
(1)预测建模:将已有数据和模型用于对未知变量的语言。
- 分类,用于预测离散的目标变量
- 回归,用于预测连续的目标变量
(2)聚类分析:发现紧密相关的观测值组群,使得与属于不同簇的观测值相比,属于同一簇的观测值相互之间尽可能类似。
(3)关联分析(又称关系模式):反映一个事物与其他事物之间的相互依存性和关联性。用来发现描述数据中强关联特征的模式。
(4)异常检测:识别其特征显著不同于其他数据的观测值。
有时也把数据挖掘分为:分类,回归,聚类,关联分析。
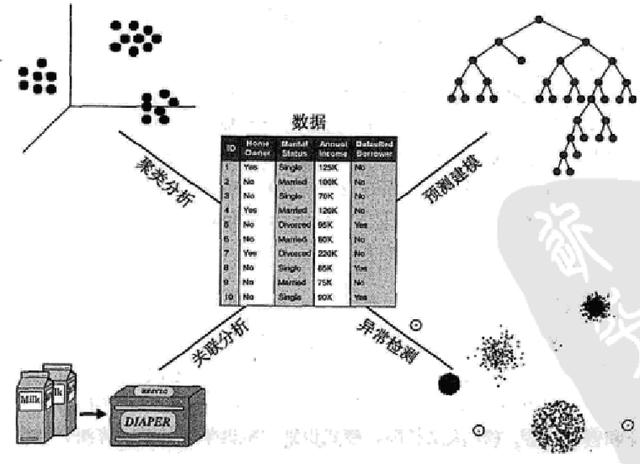
数据挖掘的四种典型算法
数据挖掘和机器学习有区别,也有关系,我们将在以后的文章中对其进行介绍。