












机器学习是一个伟大的工具,它正在改变我们的世界。在许多优秀的应用中,机器学习(尤其是深度学习)比传统方法优越得多。从用于图像分类的Alex-Net到用于图像分割的U-Net,人们看到了计算机视觉和医学图像处理领域的巨大成功。
近日,机器学习专家Andreas Maier在一篇文章中列出了人们会犯的关于机器学习的七个常见错误。
这些问题很严重,可能导致错误的结论,甚至机器学习专家在工作时也会犯这样的错误。即使是专家,也很难发现其中的许多错误,因为这需要详细查看代码和实验设置才能弄清楚。只有当你完全确定自己没有落入这些谬误中的任何一个时,你才应该继续前进或公开你的成果。
错误1:数据和模型滥用
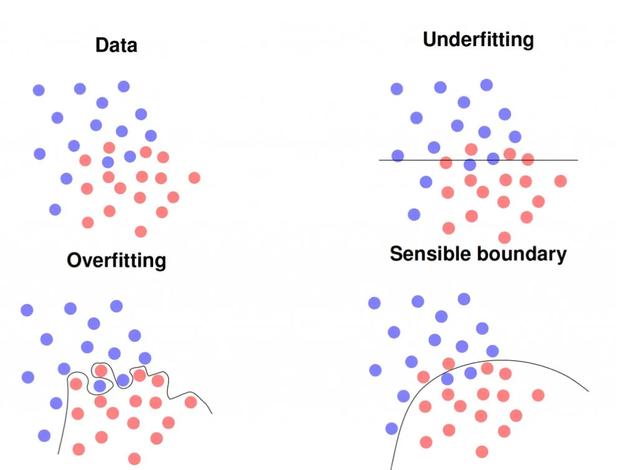
初学者常常会犯数据和模型滥用这个错误。在常见的情况下,实验设计存在缺陷,例如训练数据用作测试数据。使用简单的分类器,这导致大多数问题的识别率达到100%。在更复杂,更深入的模型中,精度可能不是100%,而是98–99%。
因此,如果在第一张照片中获得了如此高的识别率,则应仔细检查实验设置。但是,如果使用新数据,模型将完全崩溃,甚至可能产生比随机猜测更糟糕的结果,即准确度低于1 / K,其中K是类别数,例如两类问题的比例不到50%。
在同一行中,还可以通过增加参数的数量来轻松过拟合模型,从而完全记住训练数据集。另一个变体是使用过小的训练集,它不能代表您的应用程序。所有这些模型都可能会破坏新数据,即在实际应用场景中使用时。
错误2:不公平的比较
即使是机器学习方面的专家也会犯这种错误。如果想要证明你的新方法比最先进的方法更好,它通常会被提交。特别是研究论文往往会屈服于这一点,以说服评审者他们的方法具有优越性。
在最简单的情况下,从某个公共存储库下载一个模型,并使用这个模型,而不需要对模型进行微调或适当的超参数搜索,这个模型是针对当前的问题开发的,你可以调整所有参数以获得优质的测试数据性能。
关于这个错误,最近的一个例子是Isensee等人在论文中证明了原始的U-net几乎胜过所有自2015年以来针对十个不同问题提出的对该方法的改进。
因此,在应用于新建议的方法时,应该始终对比较新的模型执行相同数量的参数调优。
错误3:微不足道的进步
在做了所有的实验之后,你最终找到了一个比最先进的模型产生更好结果的模型。然而,即使在这一点上,你也没有完成。机器学习中的所有内容都是不精确的。
此外,由于学习过程的概率性,你的实验受到许多随机因素的影响。为了考虑这种随机性,需要执行统计测试。
这通常是通过使用不同的随机种子多次运行实验来执行的。
这样,你可以报告所有实验的平均性能和标准偏差。使用显著性检验,如t检验,你现在可以观察到的改善仅仅是与机会有关的概率。
为了使您的结果有意义,此概率应至少低于5%或1%。为此,你不必是统计专家。
有在线工具可以计算它们,例如识别率比较或相关比较。如果进行重复实验,请确保应用Bonferroni校正,即你所需的显著性水平除以相同数据上的实验重复次数。
错误4:混淆和错误的数据
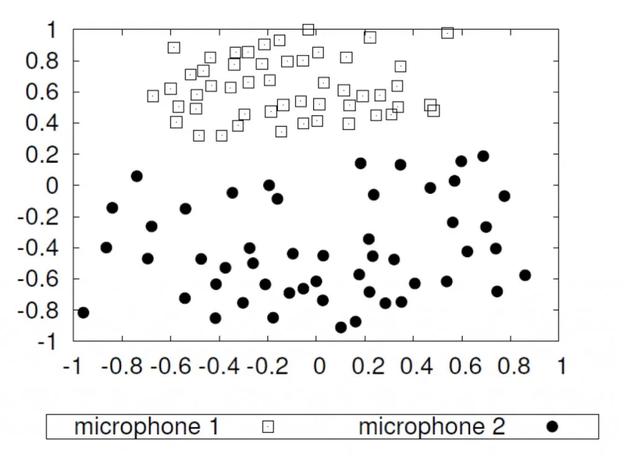
数据质量是机器学习的较大陷阱之一。它可能会导致严重的偏见,甚至导致AI存在种族主义倾向。但是,问题不在于训练算法,而在于数据本身。
错误5:不恰当的标签
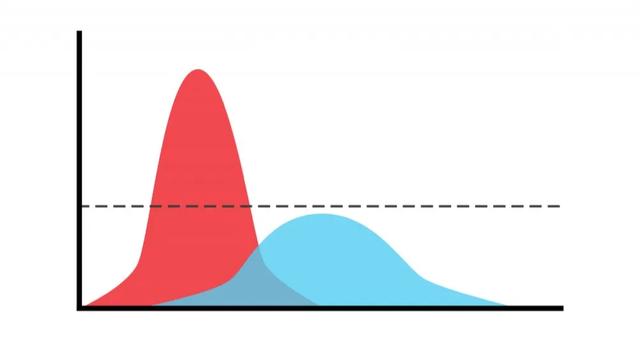
Protagoras曾说过:“一切事物的尺度是人。”这也适用于许多分类问题的标签或基本事实。
我们训练机器学习模型来反映人为类别。在许多问题中,我们认为在定义类的时候类就已经很清楚了。但查看数据时,就会发现它经常包含一些模棱两可的情况。
错误6:交叉验证混乱
这与错误1几乎是相同的,但它是变相的错误。
因此,即使是专家也可能会犯此类错误。典型的设置是第一步需要选择模型,体系结构或特征。因为只有几个数据样本,所以你决定使用交叉验证来评估每个步骤。
因此,你可以将数据拆分为N折,选择具有N-1折的特征/模型,并在第N折上求值。重复此N次后,可以计算平均性能并选择性能优秀的功能。
现在,您知道什么是很好的功能,然后继续使用交叉验证为机器学习模型选择最好的参数。这似乎是正确的,但这是有缺陷的,因为你已经在第一步中看到了所有测试数据并平均了所有观察值。
这样,所有数据中的信息都会传递到下一步,您甚至可以从完全随机的数据中获得良好的结果。
为了避免这种情况,你需要遵循一个嵌套过程,将第一步嵌套在第二个交叉验证循环中。当然,这非常昂贵,并且会产生大量实验运行。请注意,仅由于对相同数据进行大量实验,在这种情况下,仅由于偶然原因,你也会产生良好的结果。
因此,统计测试和Bonferroni校正同样是强制性的(参见错误三)。我通常会尽量避免进行大型的交叉验证实验,并尝试获取更多数据,以便进行训练/验证/测试拆分。
错误7:对结果的过度解释
除了所有先前的过失之外,我认为在当前阶段,我们在机器学习中经常犯的比较大的过错是,过度解释和夸大了自己的结果。
当然,每个人都对通过机器学习创建的方案感到满意,并且你也有权为此感到自豪。但是,应该避免将结果推断在看不见的数据或状态上。
你应该小心说话,每个主张都应基于事实。
你可以在讨论中清楚地表明推测的基础上假设该方法的普遍适用性,但要真正声明这一点,必须提供实验或理论证据。现在,很难让你的方法具有应有的可见性,尽管提出重要的观点有助于推广自己的方法,但我还是建议你踏实低调并坚持事实。















