它们彼此之间非常不同,所有数据科学家都必须了解原因和方式!
> Source: Inspired by a diagram from SAS Institute
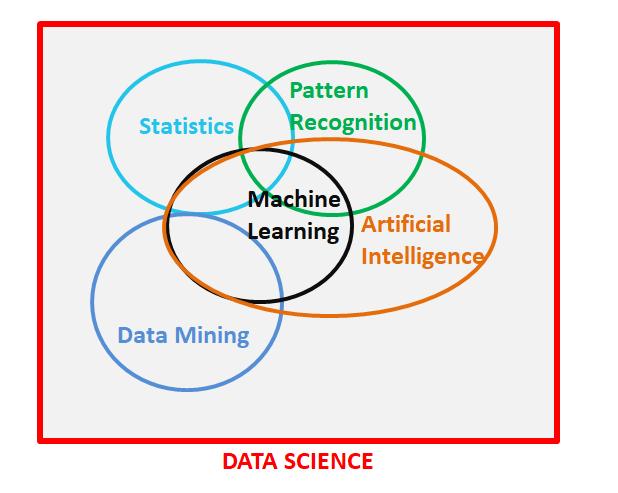
这篇文章提出了一个非常重要的区别,我们应该将其理解为数据科学领域的活跃部分。 上面的维恩图最初是由SAS Institute发布的,但是它们的图显示统计和机器学习之间没有重叠,据我所知,这是一个疏忽。 我已尽我所能和理解,重新创建了该图。 该维恩图非常恰当地提出了数据科学所有分支的区别和重叠。
我想相信数据科学现在是总称,其他所有术语都可以描述为数据科学的分支,每个分支都是不同的,但与其他分支却是如此相似!
机器学习与统计建模:这是一个古老的问题,每个数据科学家/机器学习工程师或任何在这些领域开始工作的人都会遇到。 在研究这些领域时,有时机器学习感觉与统计建模息息相关,这使我们想知道如何区分两者,或者哪种标签最适合哪种模型。 当然,如今机器学习已成为流行语,但这并不意味着我们开始将统计模型标记为机器学习模型,因为与流行的看法相反,它们是不同的! 让我们详细了解差异。
这篇文章的流程将是:
- 机器学习和统计建模的定义
- 机器学习与统计建模之间的差异
- 什么时候使用?

定义
机器学习
在不依赖于基于规则的编程的情况下,对将数据转换为智能动作的计算机算法开发感兴趣的研究领域称为机器学习。
统计建模
通常将统计模型指定为一个或多个随机变量与其他非随机变量之间的数学关系。 因此,统计模型是"理论的形式表示"。
现在,无聊的冗长的定义已不复存在,让我们更深入地了解这两个域之间的区别。
机器学习与统计建模之间的差异
1.历史和学术相关性
在1950年代左右,机器学习开始出现之前,统计建模就已经出现了。1950年代,第一个机器学习程序—塞缪尔(Samuel)的检查程序引入了。
世界各地的所有大学现在都在启动其机器学习和AI计划,但并没有关闭其统计部门。
机器学习与计算机科学系和独立的AI系协同教学,它们处理构建预测算法,这些算法能够通过学习从数据中"学习"而无需任何预先指定的规则,从而能够自行"智能化"。 上面ML的定义。
鉴于
统计建模与数学系共同教授,其重点是建立模型,该模型可以首先找到不同变量之间的关系,然后可以预测可以描述为其他自变量的函数的事件。
2.不确定度容限
这是两个域之间重要的区别点。
在统计建模中,我们要注意许多不确定性估计(例如置信区间,假设检验),并且必须考虑到所有假设都必须满足,才能信任特定算法的结果。 因此,它们具有较低的不确定性容限。
例如:如果我们建立了线性回归模型,则在使用该模型的结果之前,必须检查是否满足以下假设:
- 因变量和自变量之间的线性关系
- 错误项的独立性
- 错误项(残差)需要正态分布
- 平均独立
- 无多重共线性
- 需要方差
相反,如果我们建立了逻辑模型,则必须考虑以下假设:
- 二元逻辑回归要求因变量为二进制,而序数逻辑回归要求因变量为序。
- 观察结果必须彼此独立。
- 无多重共线性
- 自变量和对数奇数的线性
鉴于
在机器学习算法中,几乎没有或不需要假设。 ML算法对统计线性,残差的正态分布等没有严格要求,因此比统计模型灵活得多。因此,它们具有较高的不确定性容限。
3.数据需求与方法
统计模型无法在非常大的数据集上进行操作,它们需要属性较少且观测值数量可观的可管理数据集。 在统计模型中,属性的数量绝不会超过10–12,因为它们极易过拟合(在训练数据集上表现出色,但在看不见的数据上表现差强人意,因为它确实非常接近训练数据集,这是不希望出现的情况)
此外,大多数统计模型都遵循参数化方法(例如:线性回归,逻辑回归)
鉴于
机器学习算法是学习者算法,要学习它们需要大量数据。 因此,他们需要具有大量属性和观察结果的数据。 越大越好! ML算法在某种程度上需要大数据。
此外,大多数机器学习模型都遵循非参数方法(K最近邻,决策树,随机森林,梯度提升方法,SVM等)。
什么时候使用?
这主要取决于以下说明的因素。 我们将讲解理论上的要点,并举例说明。
在以下情况下,统计模型应该是您的首选:
- 不确定性很低,因为当您开始构建模型时,大多数假设都已满足
- 数据大小不是很大
- 如果要隔离少量变量的影响
- 总体预测中的不确定性/边际误差是可以的
- 各种自变量之间的相互作用相对较少,可以预先指定
- 需要高解释性
机器学习可能是更好的选择
- 当要预测的结果没有很强的随机性时; 例如,在视觉模式识别中,对象必须是E或不是E
- 可以对无限数量的精确重复进行训练(例如,每个字母重复1000次或将某个单词翻译成德语)来训练学习算法
- 当以整体预测为目标时,无法描述任何一个自变量的影响或变量之间的关系
- 人们对估计预测中的不确定性或所选预测器的影响不是很感兴趣
- 数据量巨大
- 一个不需要隔离任何特殊变量的影响
- 低可解释性,模型成为"黑匣子"是可以的
例如:如果您与一家信用卡公司合作,并且他们想建立一个跟踪客户流失的模型,那么他们很可能更喜欢一个统计模型,该模型将具有10–12个预测变量,他们可以根据自己的业务领域知识进行解释和否决 ,在这种情况下,他们将不会喜欢黑盒算法,因为对可解释性的需求比预测的准确性更高。
另一方面,如果您正在为想要构建强大的推荐引擎的Netflix和Amazon之类的客户工作,那么在这种情况下,结果准确性的要求高于模型的可解释性,因此,机器学习模型将 在这里就足够了。
有了这个,我们到这篇文章的结尾。
您可以在以下文章中了解有关数据挖掘和机器学习之间的区别以及前4个机器学习算法的完整详细信息:
- 明确解释:机器学习与数据挖掘有何不同
- 定义,混淆,区别-全部说明
- 明确解释:4种机器学习算法
- 定义,目的,流行算法和用例-全部说明
观看此空间,以获取有关机器学习,数据科学和统计学的更多信息!
学习愉快:)