












图片来自 Pexels
【51CTO.com原创稿件】随着苏宁业务的高速发展,大数据平台对海量的业务数据分析越来越具有挑战,尤其是在精确去重、复杂 JOIN 场景下,如用户画像、UV、新老买家、留存、流失用户等。
苏宁大数据平台目前 OLAP 分析的总体架构是将时序化的数据采用 Druid+ClickHouse、非时序化采用 PostGreSQL、固化场景采用 Hbase+phoenix、明细数据采用 Elasticsearch 分析。
基于 Druid 我们有 HyperLogLog 非精确去重算法,具有非常优异的空间复杂度 O(m log2log2N),空间的占用随着基数的增长变化不大,但统计存在一定的偏差。
基于其他引擎我们常用的精确去重算法一般是 GROUP BY 后 count distinct 操作,GROUP BY 会带来大量的 shuffle 操作,占用大量的磁盘和 IO,其性能较为低下。
下面将为大家揭开苏宁如何整合 RoaringBitmap 进行高效精确去重架构方案的神秘面纱。
RoaringBitmap 在苏宁的应用实践
为何选择 RoaringBitmap
首先简单为大家介绍下 RoaringBitmap,32 位的 RoaringBitmap 的是由高 16 位的 Key 和低 16 位的 Value 组成,Key 和 Value 通过下标一一对应。
Key 数组保持有序存储在 roaring_array_t 中,方便二分查找。低 16 位的 Value 存储在 Container 中,Container 共有三种。
RoaringBitmap 对创建何种 Container 有自己的优化策略,在默认创建或元素个数小于 4096 的时候创建的是 Array Container。
它是动态扩容的数组,适合存放稀疏数据,超过最大容量 4096 时,会自动转换为 Bitmap Container。
当元素超过 4096 时 Array Container 的大小占用是会线性增长,但是 Bitmap Container 的内存空间并不会增长,始终还是占用 8 K。
还有一种是 Run Container,只有在调用 runOptimize() 方法才会触发,会和 ArrayContainer、BitmapContainer 比较空间占用大小,然后选择是否转换。
Run Container 占用的存储大小看数据的连续性,上下限范围 [4 Bytes, 128 KB]。
近年来,大数据技术得到了快速的发展,各种开源技术给大数据开发人员带来了很大的便利,在众多的技术中之所以选择 RoaringBitmap,是因为它的存储空间低和运算效率高。
RoaringBitmap 的存储是通过 bit 来标识状态,经过压缩后存储,据估算苏宁 6 亿会员如果是常规的数组来存储占用空间约为 2.2G,而 RoaringBitmap 存储仅需要 66MB,大大降低的存储的空间,降低企业的成本。
RoaringBitmap 是通过位运算(如 AND、OR、ANDNOT 等)进行的,在计算能力上也相当惊人。
我们在基于 PostGresql+Citus 做过与 count distinct 的对比测试,发现 RoaringBitmap 的统计耗时是 count distinct 的近 1/50。
原生的 RoaringBitmap 只存储整形数据,32 位的 RoaringBitmap 最大的数据存储量是 2147483647。
对于会员之类的可以采用,像订单、流量这样的数据量可以采用 64 位的 RoaringBitmap,在性能上 32 位的效率在同等条件下要优于 64 位。
苏宁拥有海量的业务数据,每天都有大量的离线和实时计算任务,采用 RoaringBitmap 技术不仅大大节约了存储的成本,计算的效率也得到了显著的改善。
应用场景
①会员相关指标计算
RoaringBitmap 在会员相关指标的分析中有着许多重要的应用场景,比如会员的新、老买家、留存、复购、活跃这些指标均要用到精确去重的统计方式。
苏宁目前有 6 亿会员,像新、老买家这样的指标计算都是拿当前的买家与全量的历史买家进行比对,如何快速的精确的分析出计算结果,在没有引入 RoaringBitmap 之前是一个较大的挑战。
②精确营销
给目标用户群推送优惠的商品提高公司的销售额已经是电商公司采用普遍的精准营销手段。
但是如何在海量的用户行为日志中第一时间进行人群构建、客群洞察、再到精准地广告投放是有一定难度的。
如果采用离线计算方案其时效性不能保障,可能在这期间就丢失了目标客户,在此场景下,高效、精确的计算出目标人群尤为重要。
在引入 RoaringBitmap 后,在海量的数据中对受众人群进行全面深入的画像,精准投放广告,最终帮助企业构建了完整的数字化营销闭环。
基于 PostgreSQL 实现的 RoaringBitmap
苏宁在对非时序化的海量数据进行分析的场景,采用的是分布式 HTAP 数据库 PostgreSQL+Citus 的架构方案。
我们将 RoaringBitmap 与 Citus 做了整合,将 RoaringBitmap 融合进了 Citus 集群,而具体的体现就是表中的一个 bitmap 列,如下图所示:
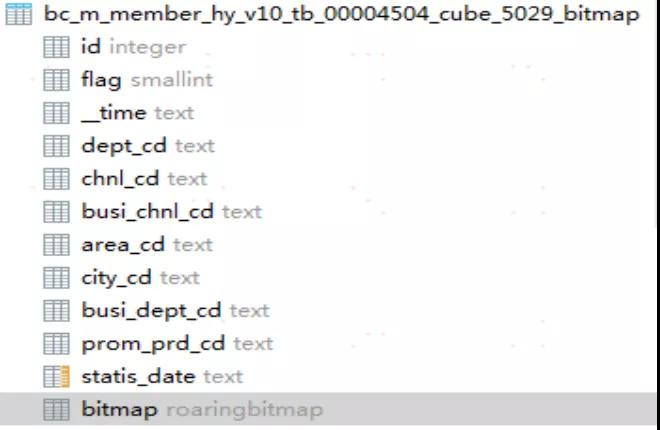
下面简单介绍下以 PostgreSQL+Citus +RoaringBitmap 的技术架构方案来实现会员新、老买家的场景。
数据字典
在进行 RoaringBitmap 的存储和计算的之前,我们首先要构建一个全局字典表,此表就是将要转化的维度维值跟 int 或 long 进行一个映射关系。
将这个映射关系存储在全局字典表中,RoaringBitmap 的 32 位和 64 位选择根据实际的数据量进行抉择。
流程设计
整体的设计流程可分为三步:
- 模型创建
- 数据摄入
- 数据分析
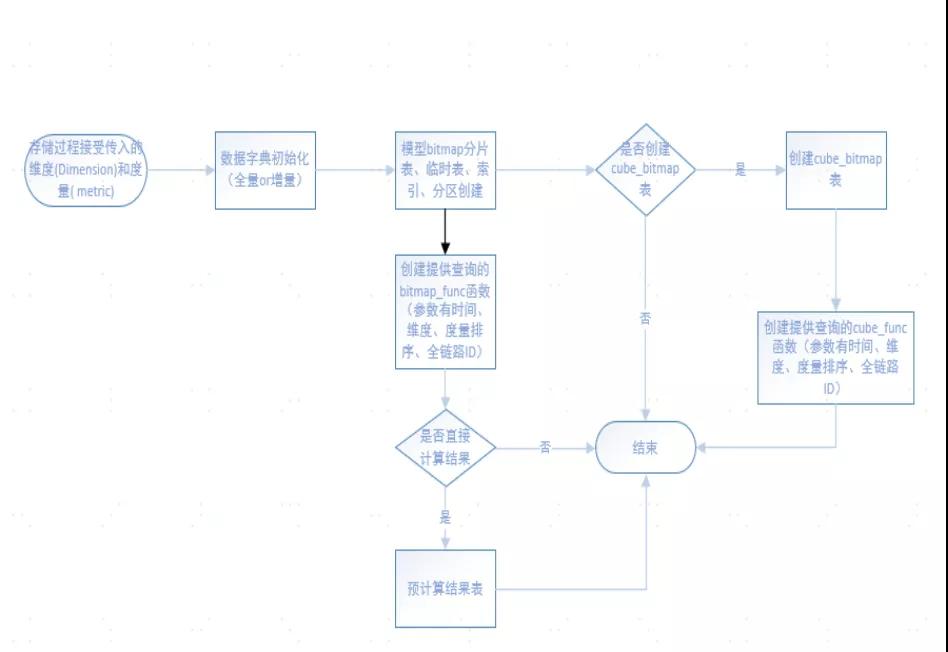
数据模型创建流程图
模型创建流程如上图:
①模型的创建、数据初始化、以及查询我们采用的基于 Citus 的存储过程实现方式,经测试基于存储过程的方式比常用的 SQL 方式在性能方面有所提升。
②分片表设计:模型中的元素是有维度、指标、bitmap 组成,Citus 目前支持三种类型的表,分别为本地表、参考表以及分片表,分别应用在不同的场景。
Citus 支持 Hash 和 Append 的方式进行分片,以新老买家为例,我们以会员的 member_id 进行 Hash 分片。
分片表设计的不仅解决了 T 级别的数据存储问题,也可以根据分片进行并行计算最后再汇总,提高计算效率。
③Cube_bitmap 表的创建是基于模型的,在后台我们有收集用户的查询方式,根据采集的样本数据我们会根据 Cost 自动的创建 Cube 用于加速。
④数据分析的数据源我们会根据 Cost 计算从预计算结果、Cube_bitmap 或模型 bitmap 表中获取。
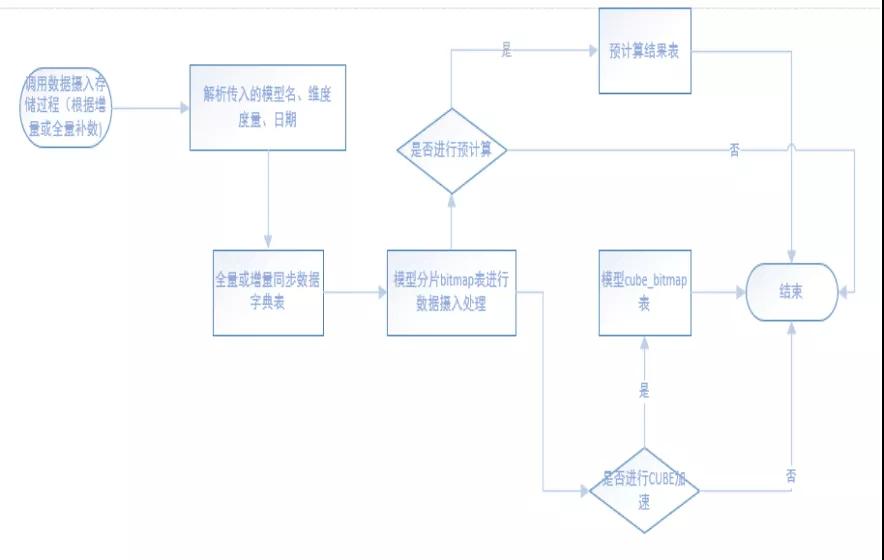
数据摄入流程图
数据摄入流程如上图:
①数据字典同步:全量和增量的模型摄入时候需要同步更新全局字典表。
②模型 bitmap 表逻辑处理(以会员为例):
第一步:模型表和字典表通过设置的业务主键 Key 进行关联。
第二步:获取模型增量维度对应的会员 bitmap 数据信息,可根据 rb_or_agg(rb_build(ARRAY [b.id :: INT])) 获取 。
第三步:将模型 bitmap 表里当天的 (flag=1) 和前一天 (flag=2) 统计的 bitmap 数据进行 rb_or_agg(bitmap) 操作,数据整合后作为当天的 flag=2 数据插入到 bitmap 表中。
第四步:日全量统计表只有 flag+statis_date+bitmap 字段,主要统计当天的用户和历史用户 bitmap 情况,统计 flag=1 的当天 bitmap 数据。
模型 bitmap 表与会员表进行关联 bitmap 取 rb_or_agg(rb_build(ARRAY[b.id :: INT]))。
第五步:日全量统计表统计 flag=2 的当天 bitmap 数据,从自身表中获取当天 flag=1 和昨天统计的 flag=2 的数据然后做 rb_or_agg(bitmap)。
③Cube_bitmap、预聚合结果表的源来自于数据模型表,在此基础上做加速处理。
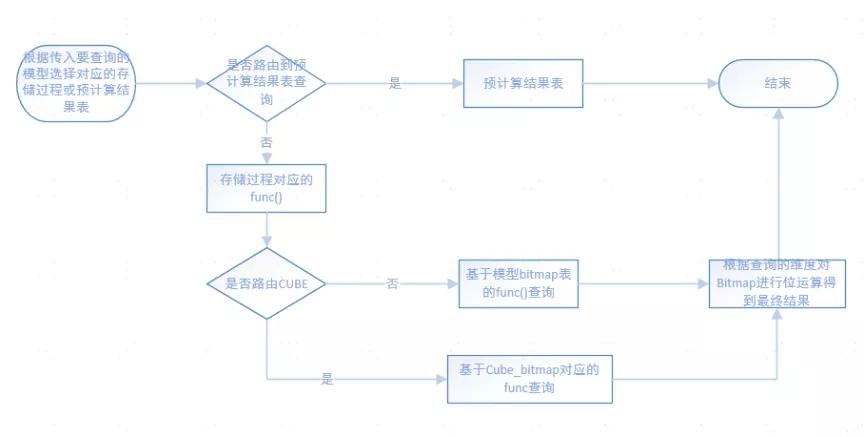
数据查询流程图
数据分析如上图:
①根据要查询的维度进行 Cost 分析判断,最终路由到预计算结果表、Cube_bitmap 表、模型表进行数据分析。
②从模型 bitmap 表或 cube_bitmap 表获取 bitmap_cur 和 bitmap_sum,从全量 bitmap 表中获取 bitmap_all 数据(flag=2 并且日期是查询日期的前一天)。
后续的 bitmap 位运算可在 bitmap_cur、bitmap_sum 和 bitmap_all 中进行。
应用举例
①业务场景
业务场景如下图:
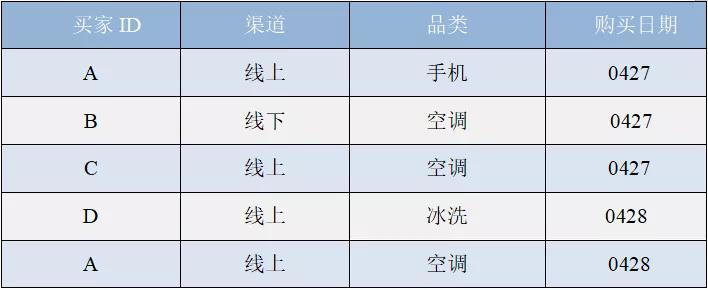
②设计方案
第一步:将买家的 ID 作为数据字典的信息,与对应的 int 或 long 形成关系映射存入全局字典表。
第二步:统计每天的线上、线下的新老买家,统计维度根据渠道(线上和线下)+tag(1 当天 2 历史)+日期。
每天有两条统计信息,一个是当天的用户买家 bitmap 集合,一个是历史的用户买家 bitmap 集合。
第二天统计基于第一天统计的集合和当天的集合做 rb_or_agg,形成一个新的当天历史 bitmap 集合(结果存储在 Bitmap_Table_A)。
第三步:基于统计维度(品类+渠道)+tag+日期来统计新老买家情况,每天也会有两条统计信息,一个是当天的一个是历史的,当天统计的是所有的品类和渠道做的 group by 统计,统计 bitmap 集合打上标签为 flag=1,历史 flag=2 是基于前一天历史加上当天统计的集合做 rb_or_agg,形成一个新的当天历史 bitmap 集合(结果存储在 Bitmap_Table_B)。
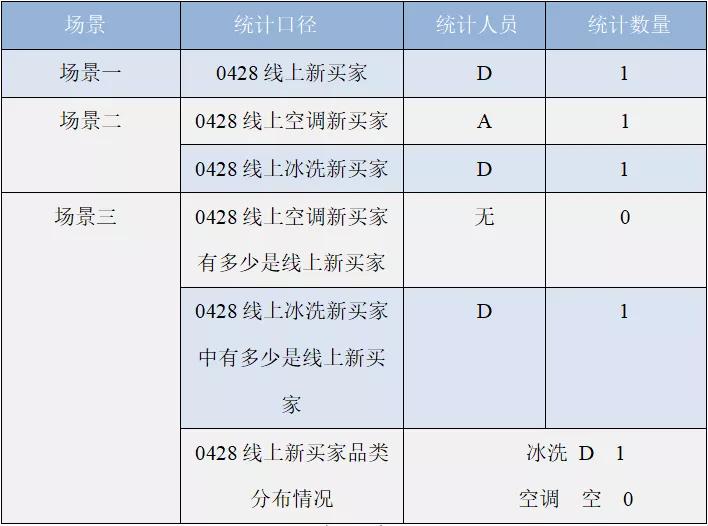
③场景分析
场景一:0428 线上新买家
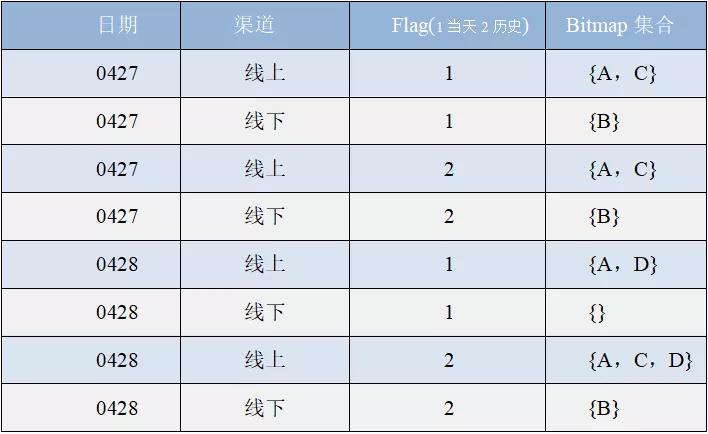
统计 0428 线上新买家实则就是 bitmap 集合 {A,D} 和 bitmap 集合 {A,C} 进行 rb_andnot_cardinality 位运算,结果为 {D},新买家的数量为 1。
场景二:0428 线上空调新买家
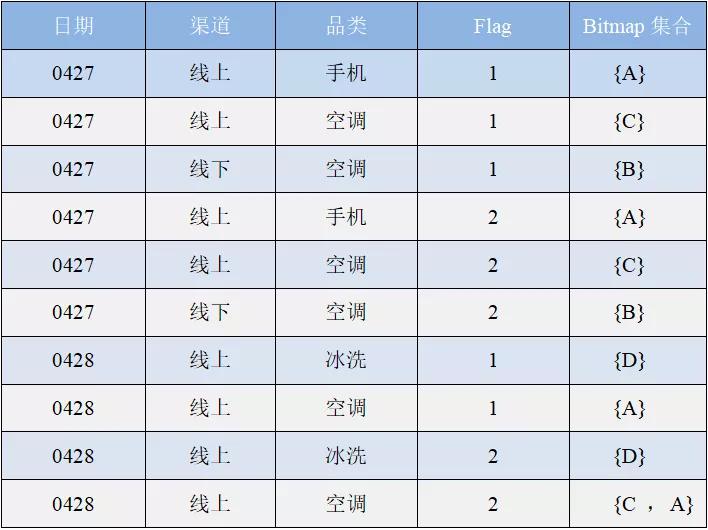
统计 0428 线上空调新买家则就是 bitmap 集合 {C ,A} 和 bitmap 集合 {C} 进行 rb_andnot_cardinality 位运算,结果为 {A},新买家的数量为 1。
0428 线上冰洗新买家则是 bitmap 集合 {D} 和 bitmap 空集合做 rb_andnot_cardinality 位运算,结果为 {D},数量为 1。
场景三:0428 线上空调新买家中有多少是线上新买家
统计则根据和 Bitmap_Table_A 和 Bitmap_Table_B 做 rb_and_cardinality 操作,则拿 bitmap 集合 {A} 和 bitmap 集合 {{A,C}} 进行 rb_andnot_cardinality 位运算,结果为空集,数量为 0。
0428 线上冰洗新买家则根据 bitmap 集合 {D} 和 bitmap 集合 {A,C} 进行 rb_andnot_cardinality 位运算,运算结果 bitmap 集合为 {D},数量为 1。
0428 线上新买家品类分布即为:基于 Bitmap_Table_B 表,0428 线上品类有冰洗 {D} 和空调 {A},基于 Bitmap_Table_A 表统计线上历史买家为 {A,C}。
线上新买家冰洗则拿 {D} 和 {A,C} 做 rb_andnot_cardinality 后的集合为 {D},数量为 1。
线上新买家空调则是拿 {A} 和 {A,C} 做 rb_andnot_cardinality 后的集合为空集,数量为 0。
不足与挑战
基于 PostgreSQL+Citus 的 RoaringBitmap 技术方案,bitmap 集合之间的位运算性能表现的较为卓越,但在很多业务场景需要高基数的 bitmap 集合进行位运算。
基于 Citus 我们分析发现,在位运算的时候 CPU 利用率处于低位,后期我们也针对基于 Citus 做了优化。
如 bitmap 下压到 Work 运算降低 CN 运算量,创建 cube 降低基数,在一定的程度了提高了效率,然在 Ctius 下的 CPU 始终没有得到充分利用。
ClickHouse 的并发 MPP+SMP 这种执行方式可以很充分地利用机器的集成资源,但当时看了 ClickHouse 还没有提供 bitmap 相关的接口,不能直接加以应用,如何将 RoaringBitmap 融合到 ClickHouse 是一个挑战。
RoaringBitmap 与 ClickHouse 的整合
在计算引擎中 ClickHouse 算是后起之秀,是一个列导向数据库,原生的向量化执行引擎,其存储是采用 Wired Tiger 的 LSM 引擎。
目前苏宁的大数据已将 ClickHouse 引入并改造,开发了相关的 RoaringBitmap 接口, 用来支撑业务交互式查询。
基于 ClickHouse 的 RoaringBitmap 方案计算过程大幅简化,查询时候的 IO、CPU、MEM、网络资源都显著降低,并且不随着数据规模而现行增加。
基于 ClickHouse 我们开发了 RoaringBitmap 相关的接口,其支持的 Function 函数有:
- bitmapBuild
- bitmapToArray
- bitmapMax
- bitmapMin
- bitmapAnd
- bitmapOr
- bitmapXor
- bitmapAndnot
- bitmapCardinality
- bitmapAndCardinality
- bitmapOrCardinality
- bitmapAndnotCardinality 等
它们用于支撑各种场景的运算,其相关的接口开发还在不断的完善中。
未来展望
为了将基于 ClickHouse 的 RoaringBitmap 方案推广到公司的更多业务和场景中,我们在做不断优化和完善。
目前正着手于以下的尝试:
- ClickHouse 目前不支持 64 位的 bitmap,正在尝试按 hash 值进行分区,每个分区单独计算,可轻易将分区进行横向叠加支持到 long 长度。
- 全局字典表在高基数下构建成本较大,占用较多资源也耗时较大,后续可根据业务场景将数据字典表最大程度复用,同时考虑在无需跨 segment 聚合时候,适用这个列的 segment 字典替代。
- 全链路监控的完善,可根据 query_id 进行各个环节的耗时分析,便于优化和问题的定位。
作者:范东
简介:苏宁科技集团大数据中心架构师,在 OLAP、OLTP 领域有着深刻的技术积累。目前主要负责数据中台和数据工具平台的架构及性能调优工作,在数据中台、数据集成开发工具、数据资产、数据质量和数据治理等方面拥有丰富的实战经验。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】















