本文以UPSQL Proxy 2.4.0中关键的报文流式处理为例,介绍MySQL通信协议,以及与客户端的关系。
MySQL通信协议协议介绍
在执行MySQL查询,如“selecet * from test”时,MySQL的应答包被称为ResultSet,其为一组逻辑包(协议包),如图1所示包含两个部分:
- 1. 元数据,包含如下数据包:
- - Field_Count:列的个数
- - Field:列的描述,一般为多个
- - Eof:在列信息描述,或数据发送完毕时候,用以标记一段数据的发送结束。在较高版中,该数据包被取消。
- 2. 行数据,包含:
- - Row:一行数据的内容,多行时会出现多个
- - Err:描述错误,出现错误时,为最后一个逻辑包
- 或
- - OK:在较高版本协议中,用以替换Eof包,用以传输更多信息
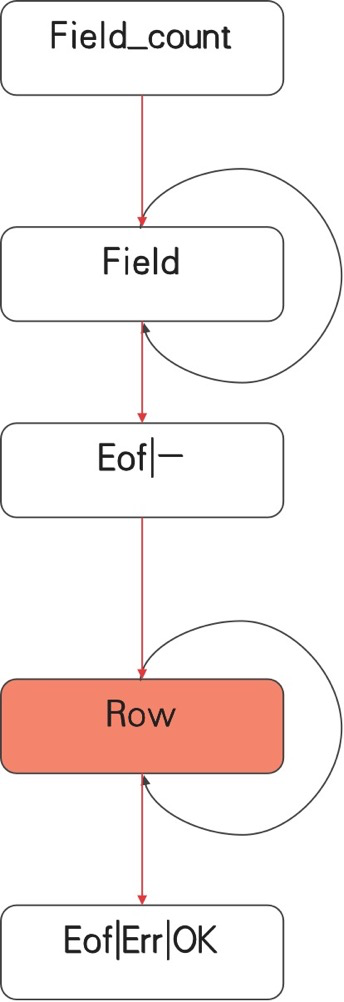
图1 MySQL结果集报文结构
客户端库接口介绍
由此MySQL CAPI中提供了两套函数接口:
- - mysql_store_result/mysql_stmt_store_result
- - mysql_use_result
- 一般而言,这两套接口的区别是:
- - mysql_store_result/mysql_stmt_store_result: 将结果存储在应用内存
- - mysql_use_result: 数据保存在tcp buffer或数据库server端
但从通信过程的角度来看:
- - mysql_store_result/mysql_stmt_store_result: 需要等待所有数据传输完毕,并且客户端解析完毕
- - mysql_use_result: 简单而言只要得到row数据包,就可以向上层api返回数据
- 所以,我们内部将mysql_use_result称为流式处理,流式处理有2大优点:
- - 应用层响应速度更快,因为不需要等待收齐结果集
- - 内存管理更可控,可以避免客户端内存不足
在mysql客户端以及mysqldump命令中,有如下参数:
- - --quik/-q,即使用mysql_use_result,进行流式处理,可以避免mysqldump大数据量下oom
JDBC在设计上封装性更高,一般而言其逻辑与CAPI的
- mysql_store_result/mysql_stmt_store_result处理逻辑一样,但有2个方法可以将其转换为流式处理模式:
- - 代码层面:prepareStatement第2、3个参数设置为ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY
- - JDBC URL设置(不修改代码):增加参数useCursorFetch=true&defaultFetchSize=-2147483648 (该方法在不同版本的jdbc驱动上表现有区别,不建议采用)
API与协议解析的关系图2所示:
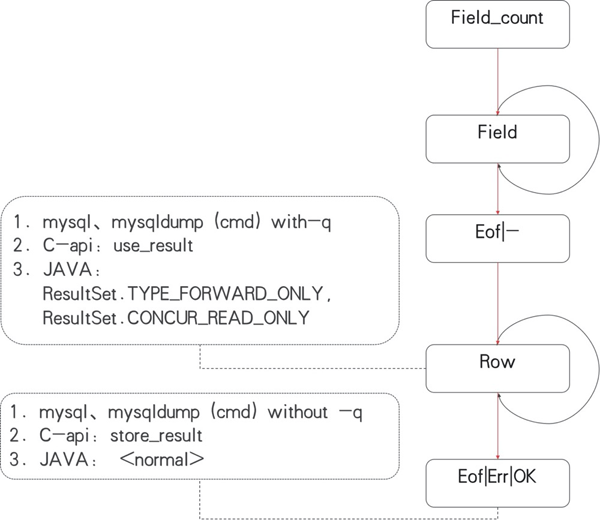
▲ 图2 API与协议解析
UPSQL Proxy中间件设计
在UPSQL Proxy 2.4.0以前使用的是阻塞模式,即往多个后端收齐结果集后,再向用户应答,这样有2个缺点:-
- 响应时延延长
- Proxy层内存控制,导致生产环境不支持大于分库下10w行以上数据量返回
UPSQL Proxy 2.4.0实现了流式处理,简单而言就是,将行信息尽快以流的形式发给客户端而不是等中间件收齐后发送,逻辑如图3所示:
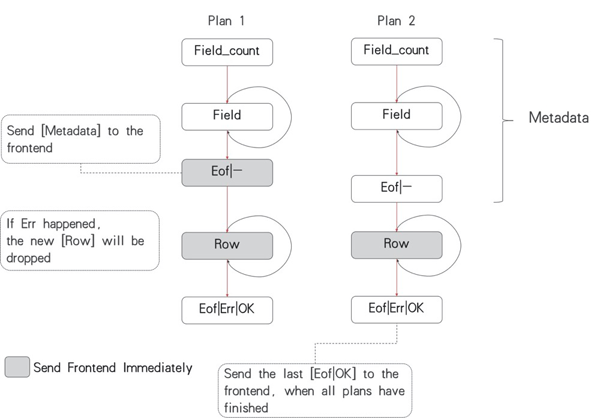
▲ 图3 UPSQL Proxy的流式处理
即在分库场景下,会并发访问各个数据节点,当得到一个完整的元数据后,就可以立刻返回给请求方,之后接收到行数据后,都可以及时的返回给请求方,以此降低中间件的内存需求,同时提高客户端的相应速度。
总结
本文介绍了银联自研中间件UPSQL Proxy早前的一次关键功能迭代,希望能让大家感受到MySQL协议的魅力。
福利时间(目前投递会有作者的内推机会哦 🙌🏻🙌🏻🙌🏻):
中国银联云计算中心社会招聘岗位正在火热招录中,目前开放投递的岗位如下:
1、运营服务
2、系统运维
3、操作系统开发
4、数据库开发(云计算方向)
5、开源组件
6、综合文秘
有意向者可打开链接【可复制到浏览器或者点击阅读原文】 https://join.unionpay.com 选择“社会招聘”分类进行投递。【注:内推请填写 周家晶及工号:01362912为推荐人】