Kubernetes(以下简写为K8s)的对象模型是K8s又一精巧的设计。我们知道,K8s所建立的容器化生态是复杂且多变的,而对象模型就是将一系列的资源实体抽象成K8s中所能识别的对象。为了方便大家更全面的了解K8s的设计思想,本文对K8s的对象模型进行了梳理,同时在文章末尾增加了常见面试题问题汇总,章节内容分配如下:
- K8s对象模型概述-我们为什么要了解对象模型
- K8s常见对象模型介绍-哪些对象模型可以为我们所用
- K8s对象模型的组织形式及yaml创建方法-我们该如何使用对象
- 总结
K8s对象模型概述-我们为什么要了解对象模型
这问题还用想?存在即合理呗。那咱们就先来看看他为什么存在。
在官方文档中,对K8s的对象模型有这样的定义:
“在 Kubernetes 系统中,Kubernetes 对象是持久化的实体。Kubernetes 使用这些实体去表示整个集群的状态。特别地,它们描述了如下信息:
- 哪些容器化应用在运行(以及在哪个 Node 上)
- 可以被应用使用的资源
- 关于应用运行时表现的策略,比如重启策略、升级策略,以及容错策略”
简单说来,对象模型主要有两点目标:
1.服务于K8s集群
对象模型一个功能是用以抽象化描述K8s集群状态,实体及实体间关联。此类的代表就是Label,它建立集群对象之间的灵活、松耦合的多维关联关系,我们可以用通过lable selector 查询和筛选建立对象间的关系的。
2.服务于用户。
K8s提供多种抽象对象便于用户部署自己的应用到集群中,这些抽象对象为用户屏蔽了复杂的底层逻辑,让用户更专注于如何去使用。此类的例子就比较多,比如Pod,Node,Deployment等。举个例子来说,比如我们要部署应用在8s集群内,首先要我们的应用需要转换为K8s所能管理的实体对象如Pod;对于多副本应用,我们需要考虑进行统一的管理,可以考虑如Deployment;进一步考虑副本间的负载均衡和服务发现,我们又可以考虑采用Service来实现,用户无需关注其内部实现,从而更专注于自身的应用。
K8s常见对象模型-哪些对象模型可以为我们所用
既然把K8s对象模型吹得这么神,那得看看他是不是真有这么神。下面来一起看看K8s常见的对象。
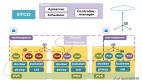
这里再用一幅图来更形象地介绍各个对象在K8s中的所处位置。
Workload类对象
Pod
位置:位于图中标有Pod标记的位置
说明:Pod是集群中可以创建和部署的最小且最简单的Kubernetes对象的单元,其表示单个 容器 或少量紧密耦合并共享资源的容器集合。
抽象与封装:Pod封装了应用容器,存储资源、独立的网络IP以及容器运行的策略选项。目前Docker 是 Kubernetes Pod 中最常用的容器运行时,因此在本文中所提到的容器均值docker容器。目前Docker 是 Kubernetes Pod 中最常用的容器运行时,因此在本文中所提到的容器均指docker容器。
在K8s中,每个pod中预置了一个Pause容器,其namespace、IPC资源、网络和存储资源被pod内其它容器共享。Pod中的所有容器紧密协作,并且作为一个整体被管理、调度和运行。
Controllers
位置:位于图中Master中的Controller-Manager位置。
说明:Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理。他们的职责是保证集群中各种资源的状态和用户定义(yaml)的状态一致, 每个controller通过API Server提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”。例如,当某个Node意外宕机时,Node Controller会及时发现并执行自动化修复流程,确保Node始终处于预期的工作状态。下图列出了部分controller的图例:
抽象与封装:从逻辑上讲,每个控制器都是一个单独的进程,他们为用户封装了针对于资源对象的管理逻辑。用户在创建资源对象后,controller会帮助用户实时监控整个集群的每个资源对象的当前状态,自动化地确保资源对象始终处于预期的工作状态。此外。K8s支持用户自定义扩展controller。
Deployment/Statefulset/Daemonset/Job
位置:Deployment位于图中④位置,Statefulset位于图中⑤位置,Daemonset/Job位于图中绿色Pod位置。
说明:这一类资源对象为Pod提供了一个声明式定义(declarative)方法,但同时他们又各自负责处理不同的使用场景。Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController 来方便的管理应用,主要是针对是 Kubernetes 中用于处理无状态服务的资源。典型的应用场景包括:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
StatefulSet 是用于支持有状态服务的资源,典型的应用场景是Zookeeper、Kafka。它可以保证部署和 scale 的顺序。其应用场景包括:
- 稳定的持久化存储。
- 稳定的网络标志。
- 有序部署和扩展。
- 有序收缩和删除。
DaemonSet不同于上两个方式,它解决的场景是在集群中所有节点上同时提供基础服务和守护进程。DaemonSet 可以保证集群中所有的或者部分的节点都能够运行同一份 Pod 副本,如kube-router、flannel等都是以DaemonSet部署。
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束,可应用的场景如采集数据等。可能会用人希望能自动化的定时执行任务,就像crontab一样,别急,K8s同样针对定时任务提供了cronjob资源对象,能够支持类似crontab一样的定时功能。
Discovery&Loadbalance类对象
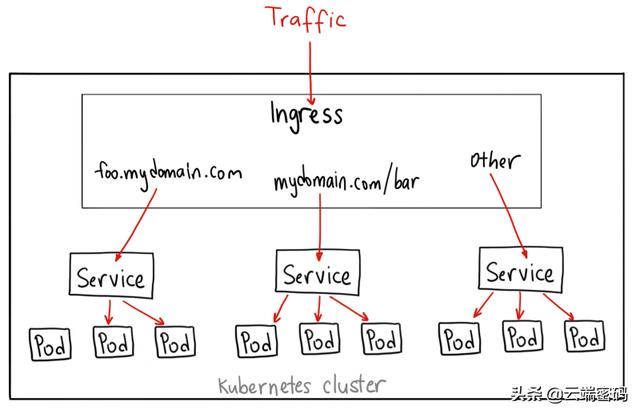
Service/Endpoints/Ingress
位置:Service在图中①,②位置处。Ingress在图中③处。
说明:Kubernetes Service 是对一个个Pod 的逻辑分组的抽象,它提供了一种可以访问它们的策略,通常称为微服务。
K8s通过抽象出Service概念,为后端绑定的pod服务提供服务发现和负载均衡功能,为一组具有相同功能的容器应用提供一个统一的入口地址,并将请求进行负载分发到后端的各个容器应用上的控制器。这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector实现的。
Endpoint是K8s集群中的一个资源对象,存储在etcd中,用来记录一个Service对应的所有pod的访问地址。Service配置selector,endpoint controller才会自动创建对应的endpoint对象;否则,不会生成Endpoint对象。
Ingress同样是与Service相关的资源对象,它授权入站连接到达集群服务的规则集合。我们可以给Ingress配置提供外部可访问的URL、负载均衡、SSL、基于名称的虚拟主机等。用户通过POST Ingress资源到API server的方式来请求ingress。 偷个懒,借用一张网络上的图来解释一下三者关系(图中的Pod可以理解为是EndPoints):
Config&Storage类对象
Configmap/ Secret/ Volume/ PersistentVolume
位置:Configmap、Secret位于图中标有Configmap、Secret的位置。PersistentVolume 则位于图中PV1,PV2,PV3。
说明:在K8s中,定义了volume来解决容器的存储问题,称之为Volume。不仅能够解决 Container 中文件的临时性问题,也能够让同一个 Pod 中的多个 Container 共享文件。这里提到的卷(Volume)其实是一个比较特定的概念,它并不是一个持久化存储,可能会随着 Pod 的删除而删除,常见的卷就包括 EmptyDir、HostPath、ConfigMap 和 Secret,这些卷与所属的 Pod 具有相同的生命周期。与Volume相对应的,是持久卷概念,即PersistentVolume,他提供了持久化存储的方案,将Pod与卷的声明周期分离。
抽象与封装:Volume和PersistentVolume为用户屏蔽了集群中容器存储的底层逻辑,集群中的每一个卷在被 Pod 使用时都会经历两个操作,也就是挂载(Mount)、卸载(Unmount),有些如Configmap、Secret还会经历附着(Attach)、分离(Detach)操作,但这些操作用户都不需要关心,只需要在yaml中设置数据源和挂载路径就可以。同时,存储对象的管理也是有对象自动进行的,创建和删除存储资源,对于用户来说只需要简单的create和delete,但实际上对于存储资源的分配,回收也都有K8s自动完成。
Cluster类对象
Node/Namespace/Role/ClusterRole
位置:Node位于图中黄色块并标有Node的位置。Namespace是位于图中标有Namespace的框,。Role是图中位于盾牌位置, ClusterRole是图中盾牌的全集。
说明:Cluster对象在K8s中代表着某些全局性的资源对象。Node不必多说,是K8s存在的物理基础。Namespace类似编程语言中的作用域,K8s支持通过Namespace在一个物理集群中划分出多个虚拟集群,这些虚拟集群使用单独的命名空间。各个Namespace之间容器是不透明的,也便于用户进行更细粒度的权限控制。
Role和ClusterRole负责为用户提供集群内的权限管理。Role对象用于授予对某一单一命名空间中资源的访问权限,而整个Kubernetes集群范围内有效的角色则通过ClusterRole对象实现。在使用中,我们可以对以下几种资源赋予权限:
- 集群范围资源(如node)
- 非资源类型endpoint
- 跨命名空间的资源(例如跨namespace的pod)
抽象与封装:Cluster类型的对象为用户屏蔽了对于集群的管理逻辑。整个集群被抽象成一种扁平化的结构。我们可以把集群比作一个象棋棋盘,Pod(棋子)优先会部署在各自的区域(namespace),有些Pod(棋子)只能在各自区域操作,有些Pod(棋子)则可以跨区域操作。用户只需要学会使用这些Pod(棋子),而具体的规则和执行逻辑由K8s制定。
K8s对象模型的组织形式及yaml创建方法-我们该如何使用对象
在K8s中,提供给用户的组织和创建对象的方式是通过yaml文件进行的,对于一个编写好的yaml文件,可以采用以下指令来创建对象资源
kubectl create/apply -f ***.yaml
- 1.
通过下列指令就可以看到一个Pod对象的组织方式。
kubectl describe pod *** -n <namespace>
- 1.
下面,本节针对对象yaml的各个字段及各资源创建方式进行详细解析。首先,我们需要建立一个概念,yaml文件是对对象描述的一种形象化,即描述对象的概念映射到yaml上就是一个个kv字段。在描述K8s对象时,有两个嵌套字段是必须的,它们负责管理对象的配置:spec 和 status。spec必须提供,它描述了对象的期望状态——希望对象所具有的特征。status 描述了对象的实际状态,它是由 K8s系统提供和更新。在任何时刻,K8s管理模块一直处于活跃状态,管理着对象的实际状态以与我们所期望的状态相匹配。
例如:

可以看到Deployment对象的Spec和Status描述结构。
再说yaml,对于不同的对象而言,yaml配置的内容有所不同,但以下几项是必选:
apiVersion # 创建该对象所使用的 Kubernetes API 的版本
kind # 想要创建的对象的类型
metadata # 识别对象唯一性的数据,包括一个 name 字符串、UID 和可选的 namespace
- 1.
- 2.
- 3.
- 4.
- 5.
spec 字段,spec不是强制,但用户使用时是有必要提供该字段内容的。也是由于各对象的差异,所以spec 的精确格式对每个 Kubernetes 对象来说是不同的,包含了特定于该对象的嵌套字段。详细的字段内容可参考K8s API(
https://kubernetes.io/docs/api/)。下面我们对各资源的创建方式进行举例:
Workload类对象
Pod类资源我们使用经典案例——busybox的创建模板进行简述:

这则模板中首先指定了yaml的三要素,apiVersion、kind、metadata。在Pod特有的spec中指定了所需的镜像busybox,并简单设置了镜像拉取和容器重启的策略。在使用过程中我们会发现,简单的配置后,因镜像拉取或容器重启带来的异常管理问题,K8s都会帮你自动完成,也就是之前提到的对象的实际状态以与我们所期望的状态相匹配。
再举一个例子,经典的nginx模板用例:

Deployment用以描述一类Pod集合,因此这里指定了副本数,并设置了selector来简历Pod与Deployment的关系。
Discovery&Loadbalance类对象
这一类资源代表具备网络特性的对象,其中的代表对象就是Service,这里我们也列举一个Service的经典用例加以说明。

Service对象的yaml模板里,我们可以指定一个或一组Pod的通信端口及通信协议,并制定服务的暴露方式。
Config&Storage类对象
Configmap作为非持久化存储的代表,我们先举一个例子来说明:

Configmap的部署用例没有spec域,直接指定了数据的内容。除了以上使用yaml方式创建外,当我们将 ConfigMap 或者 Secret 包装成卷并挂载到某个目录时,我们其实是在创建 Volume,这些 Volume 并不是 Kubernetes 中的对象,它们只存在于当前 Pod 中,随着 Pod 的删除而删除,但是需要注意的是这些临时的Volume的删除并不会导致相关 ConfigMap 或者 Secret 对象的删除。
我们再举持久化存储的例子。

持久化存储的创建用例和Pod对象有些类似,需要制定存储的预期状态,这里设置了一个容量为1G,以可读可写方式挂载到多个节点,并使用nfs挂载的PV存储。这样在创建完成后,就可以使用PVC在Pod进行存储绑定了。
Cluster类对象
Cluster类对象多数属于集群集群资源对象,默认可不需要用户自己使用yaml创建,比如namespace就可以直接使用命令 kubectl create ns **** 来创建。这里我们举一个ClusterRole的yaml例子。

在这个例子中,我们定义了一个ClusterRole的对象,它可以授予对secrets资源对象的get,watch,list权限。接来下我们就是用ClusterRoleBinding来使用它。ClusterRoleBinding可以将角色中定义的权限授予用户或用户组,ClusterRoleBinding包含一组权限列表(subjects),权限列表中包含有不同形式的待授予权限资源类型(如USER,GROUP,SERVICEACCOUNT),ClusterRoleBinding适用于集群范围内的授权,与之相对应的RoleBinding适用于某个命名空间内授权。举例说明:

在这个用例中,我们将secret这个ClusterRole绑定到了dazhuang这个用户上,授权用户dazhuang只能访问myspace中的secret。
总结
K8s的对象模型是 K8s中非常重要的一部分,也是K8s构建的基础。K8s中各个对象为使用者屏蔽了复杂的底层细节,并通过不断获取集群的运行状态与期望状态进行对比,来帮助使用者确保对象能在预期的状态下运行,希望这篇文章能帮助各位读者更全面的理解K8s的对象模型。