展现在您眼前的这幅图像中的人物并非自真实存在,其实她是由一个机器学习模型创造出来的虚拟人物。图片取自 维基百科的 GAN 条目,画面细节丰富、色彩逼真,让人印象深刻。
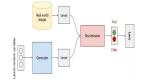
生成对抗网络(GAN)是一种生成式机器学习模型,它被广泛应用于广告、游戏、娱乐、媒体、制药等行业,可以用来创造虚构的人物、场景,模拟人脸老化,图像风格变换,以及产生化学分子式等等。下面两张图片,分别展示了图片到图片转换的效果,以及基于语义布局合成景物的效果。


本文将引领读者,从工程实践角度出发,借助 AWS 机器学习相关云计算服务,基于 PyTorch 机器学习框架,构建第一个生成对抗网络,开启全新的、有趣的机器学习和人工智能体验。
还等什么,让我们马上开始吧!
主要内容
- 课题及方案概览
- 模型的开发环境
- 生成对抗网络模型
- 模型的训练和验证
- 结论与总结
课题及方案概览
下面显示的两组手写体数字图片,您是否能从中够辨认出由计算机生成的『手写』字体是其中哪一组?


本文的课题是用机器学习方法『模仿手写字体』,为了完成这个课题,您将亲手体验生成对抗网络的设计和实现。『模仿手写字体』与人像生成的基本原理和工程流程基本是一致的,虽然它们的复杂性和精度要求有一定差距,但是通过解决『模仿手写字体』问题,可以为生成对抗网络的原理和工程实践打下基础,进而可以逐步尝试和探索更加复杂先进的网络架构和应用场景。
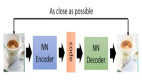
《生成对抗网络》(GAN)由 Ian Goodfellow 等人在 2014年提出,它是一种深度神经网络架构,由一个生成网络和一个判别网络组成。生成网络产生『假』数据,并试图欺骗判别网络;判别网络对生成数据进行真伪鉴别,试图正确识别所有『假』数据。在训练迭代的过程中,两个网络持续地进化和对抗,直到达到平衡状态(参考:纳什均衡),判别网络无法再识别『假』数据,训练结束。
2016年,Alec Radford 等发表的论文 《深度卷积生成对抗网络》(DCGAN)中,开创性地将卷积神经网络应用到生成对抗网络的模型算法设计当中,替代了全链接层,提高了图片场景里训练的稳定性。
Amazon SageMaker 是 AWS 完全托管的机器学习服务,数据处理和机器学习训练工作可以通过 Amazon SageMaker 快速、轻松地完成,训练好的模型可以直接部署到全托管的生产环境中。Amazon SageMaker 提供了托管的 Jupyter Notebook 实例,通过 SageMaker SDK 与 AWS 的多种云服务集成,方便您访问数据源,进行探索和分析。SageMaker SDK 是一套开放源代码的 Amazon SageMaker 的开发包,可以协助您很好的使用 Amazon SageMaker 提供的托管容器镜像,以及 AWS 的其他云服务,如计算和存储资源。
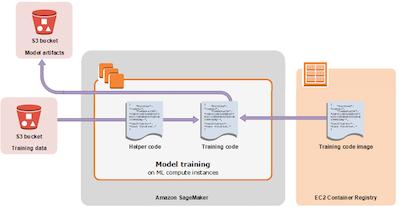
如上图所示,训练用数据将来自 Amazon S3 的存储桶;训练用的框架和托管算法以容器镜像的形式提供服务,在训练时与代码结合;模型代码运行在 Amazon SageMaker 托管的计算实例中,在训练时与数据结合;训练输出物将进入 Amazon S3 专门的存储桶里。后面的讲解中,我们会了解到如何通过 SageMaker SDK 使用这些资源。
我们将用到 Amazon SageMaker、Amazon S3 、Amazon EC2 等 AWS 服务,会产生一定的云资源使用费用。
模型的开发环境
创建Notebook实例
请打开 Amazon SageMaker 的仪表板(点击打开 北京区域 | 宁夏区域 ),请点击Notebook instances 按钮进入笔记本实例列表。
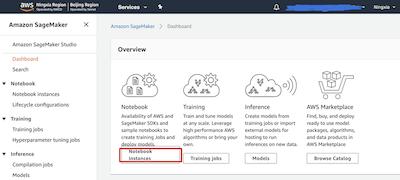
如果您是第一次使用Amazon SageMaker,您的 Notebook instances 列表将显示为空列表,此时您需点击 Create notebook instance 按钮来创建全新 Jupyter Notebook 实例。
进入 Create notebook instance 页面后,请在 Notebook instance name 字段里输入实例名字,本文将使用 MySageMakerInstance 作为实例名,您可以选用您认为合适的名字。本文将使用默认的实例类型,因此 Notebook instance type 选项将保持为 *ml.t2.medium*。如果您是第一次使用Amazon SageMaker,您需要创建一个 IAM role,以便笔记本实例能够访问 Amazon S3 服务。请在 IAM role 选项点击为 Create a new role。Amazon SageMaker 将创建一个具有必要权限的角色,并将这个角色分配给正在创建的实例。另外,根据您的实际情况,您也可以选择一个已经存在的角色。
在 Create an IAM role 弹出窗口里,您可以选择 *Any S3 bucket*,这样笔记本实例将能够访问您账户里的所有桶。另外,根据您的需要,您还可以选择 Specific S3 buckets并输入桶名。点击 Create role 按钮,这个新角色将被创建。
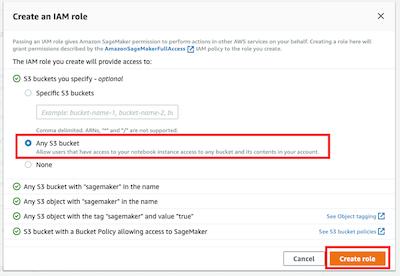
此时,可以看到 Amazon SageMaker 为您创建了一个名字类似 *
AmazonSageMaker-ExecutionRole-**** 的角色。对于其他字段,您可以使用默认值,请点击 Create notebook instance 按钮,创建实例。
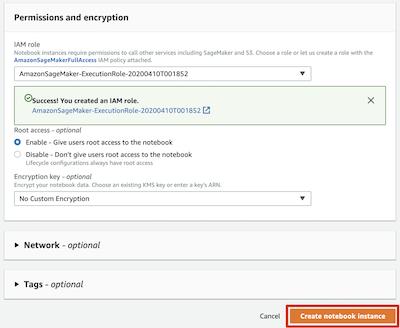
回到 Notebook instances 页面,您会看到 MySageMakerInstance 笔记本实例显示为 Pending 状态,这个将持续2分钟左右,直到转为 InService 状态。

编写第一行代码
点击 Open JupyterLab 链接,在新的页面里,您将看到熟悉的 Jupyter Notebook 加载界面。本文默认以 JupyterLab 笔记本作为工程环境,根据您的需要,可以选择使用传统的 Jupyter 笔记本。
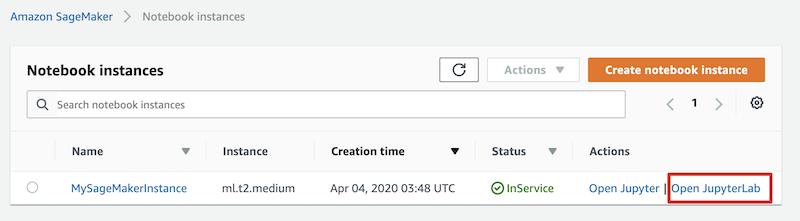
您将通过点击 conda_pytorch_p36, 笔记本图标来创建一个叫做 Untitled.ipynb 的笔记本,您可以稍后更改它的名字。另外,您也可以通过 File > New > Notebook 菜单路径,并选择 conda_pytorch_p36 作为 Kernel 来创建这个笔记本。
在新建的 Untitled.ipynb 笔记本里,我们将输入第一行指令如下,
import torch
print(f"Hello PyTorch {torch.__version__}")
- 1.
- 2.
- 3.
源代码下载
请在笔记本中输入如下指令,下载代码到实例本地文件系统。
下载完成后,您可以通过 File browser 浏览源代码结构。
本文涉及到的代码和笔记本均通过 Amazon SageMaker 托管的 Python 3.6、PyTorch 1.4 和 JupyterLab 验证。本文涉及到的代码和笔记本可以通过 这里获取。
生成对抗网络模型
算法原理
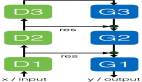
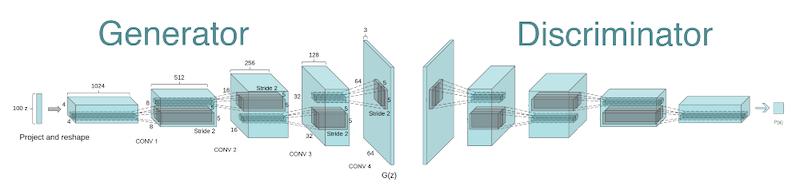
DCGAN模型的生成网络包含10层,它使用跨步转置卷积层来提高张量的分辨率,输入形状为 (batchsize, 100) ,输出形状为 (batchsize, 64, 64, 3)。换句话说,生成网络接受噪声向量,然后经过不断变换,直到生成最终的图像。
判别网络也包含10层,它接收 (64, 64, 3) 格式的图片,使用2D卷积层进行下采样,最后传递给全链接层进行分类,分类结果是 1 或 0,即真与假。
DCGAN 模型的训练过程大致可以分为三个子过程。
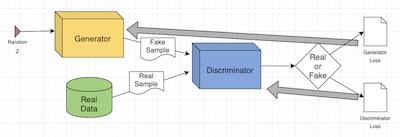
首先, Generator 网络以一个随机数作为输入,生成一张『假』图片;接下来,分别用『真』图片和『假』图片训练 Discriminator 网络,更新参数;最后,更新 Generator 网络参数。
代码分析
项目目录 byos-pytorch-gan 的文件结构如下,
文件 model.py 中包含 3 个类,分别是 生成网络 Generator 和 判别网络 Discriminator。
class Generator(nn.Module):
...
class Discriminator(nn.Module):
...
class DCGAN(object):
"""
A wrapper class for Generator and Discriminator,
'train_step' method is for single batch training.
"""
...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
文件 train.py 用于 Generator 和 Discriminator 两个神经网络的训练,主要包含以下几个方法,
def parse_args():
...
def get_datasets(dataset_name, ...):
...
def train(dataloader, hps, ...):
...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
模型的调试
开发和调试阶段,可以从 Linux 命令行直接运行 train.py 脚本。超参数、输入数据通道、模型和其他训练产出物存放目录都可以通过命令行参数指定。
python dcgan/train.py --dataset qmnist \
--model-dir '/home/myhome/byom-pytorch-gan/model' \
--output-dir '/home/myhome/byom-pytorch-gan/tmp' \
--data-dir '/home/myhome/byom-pytorch-gan/data' \
--hps '{"beta1":0.5,"dataset":"qmnist","epochs":15,"learning-rate":0.0002,"log-interval":64,"nc":1,"nz":100,"sample-interval":100}'
- 1.
- 2.
- 3.
- 4.
- 5.
这样的训练脚本参数设计,既提供了很好的调试方法,又是与 SageMaker Container 集成的规约和必要条件,很好的兼顾了模型开发的自由度和训练环境的可移植性。
模型的训练和验证
请查找并打开名为 dcgan.ipynb 的笔记本文件,训练过程将由这个笔记本介绍并执行,本节内容代码部分从略,请以笔记本代码为准。
互联网环境里有很多公开的数据集,对于机器学习的工程和科研很有帮助,比如算法学习和效果评价。我们将使用 QMNIST 这个手写字体数据集训练模型,最终生成逼真的『手写』字体效果图样。
数据准备
PyTorch 框架的 torchvision.datasets 包提供了QMNIST 数据集,您可以通过如下指令下载 QMNIST 数据集到本地备用。
from torchvision import datasets
dataroot = './data'
trainset = datasets.QMNIST(root=dataroot, train=True, download=True)
testset = datasets.QMNIST(root=dataroot, train=False, download=True)
- 1.
- 2.
- 3.
- 4.
- 5.
Amazon SageMaker 为您创建了一个默认的 Amazon S3 桶,用来存取机器学习工作流程中可能需要的各种文件和数据。 我们可以通过 SageMaker SDK 中 sagemaker.session.Session 类的 default_bucket 方法获得这个桶的名字。
from sagemaker.session import Session
sess = Session()
# S3 bucket for saving code and model artifacts.
# Feel free to specify a different bucket here if you wish.
bucket = sess.default_bucket()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
SageMaker SDK 提供了操作 Amazon S3 服务的包和类,其中 S3Downloader 类用于访问或下载 S3 里的对象,而 S3Uploader 则用于将本地文件上传至 S3。您将已经下载的数据上传至 Amazon S3,供模型训练使用。模型训练过程不要从互联网下载数据,避免通过互联网获取训练数据的产生的网络延迟,同时也规避了因直接访问互联网对模型训练可能产生的安全风险。
from sagemaker.s3 import S3Uploader as s3up
s3_data_location = s3up.upload(f"{dataroot}/QMNIST", f"s3://{bucket}/data/qmnist")
- 1.
- 2.
- 3.
训练执行
通过
sagemaker.getexecutionrole() 方法,当前笔记本可以得到预先分配给笔记本实例的角色,这个角色将被用来获取训练用的资源,比如下载训练用框架镜像、分配 Amazon EC2 计算资源等等。
训练模型用的超参数可以在笔记本里定义,实现与算法代码的分离,在创建训练任务时传入超参数,与训练任务动态结合。
hps = {
"learning-rate": 0.0002,
"epochs": 15,
"dataset": "qmnist",
"beta1": 0.5,
"sample-interval": 200,
"log-interval": 64
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
sagemaker.pytorch 包里的 PyTorch 类是基于 PyTorch 框架的模型拟合器,可以用来创建、执行训练任务,还可以对训练完的模型进行部署。参数列表中, train_instance_type 用来指定CPU或者GPU实例类型,训练脚本和包括模型代码所在的目录通过 source_dir 指定,训练脚本文件名必须通过 entry_point 明确定义。这些参数将和其余参数一起被传递给训练任务,他们决定了训练任务的运行环境和模型训练时参数。
from sagemaker.pytorch import PyTorch
estimator = PyTorch(role=role,
entry_point='train.py',
source_dir='dcgan',
output_path=s3_model_artifacts_location,
code_location=s3_custom_code_upload_location,
train_instance_count=1,
train_instance_type='ml.c5.xlarge',
train_use_spot_instances=True,
train_max_wait=86400,
framework_version='1.4.0',
py_version='py3',
hyperparameters=hps)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
请特别注意 train_use_spot_instances 参数,True 值代表您希望优先使用 SPOT 实例。由于机器学习训练工作通常需要大量计算资源长时间运行,善用 SPOT 可以帮助您实现有效的成本控制,SPOT 实例价格可能是按需实例价格的 20% 到 60%,依据选择实例类型、区域、时间不同实际价格有所不同。
您已经创建了 PyTorch 对象,下面可以用它来拟合预先存在 Amazon S3 上的数据了。下面的指令将执行训练任务,训练数据将以名为 QMNIST 的输入通道的方式导入训练环境。训练开始执行过程中,Amazon S3 上的训练数据将被下载到模型训练环境的本地文件系统,训练脚本 train.py 将从本地磁盘加载数据进行训练。
# Start training
estimator.fit({'QMNIST': s3_data_location}, wait=False)
- 1.
- 2.
根据您选择的训练实例不同,训练过程中可能持续几十分钟到几个小时不等。建议设置 wait 参数为 False ,这个选项将使笔记本与训练任务分离,在训练时间长、训练日志多的场景下,可以避免笔记本上下文因为网络中断或者会话超时而丢失。训练任务脱离笔记本后,输出将暂时不可见,可以执行如下代码,笔记本将获取并载入此前的训练回话,
%%time
from sagemaker.estimator import Estimator
# Attaching previous training session
training_job_name = estimator.latest_training_job.name
attached_estimator = Estimator.attach(training_job_name)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
由于的模型设计考虑到了GPU对训练加速的能力,所以用GPU实例训练会比CPU实例快一些,例如,p3.2xlarge 实例大概需要15分钟左右,而 c5.xlarge 实例则可能需要6小时以上。目前模型不支持分布、并行训练,所以多实例、多CPU/GPU并不会带来更多的训练速度提升。
训练完成后,模型将被上传到 Amazon S3 里,上传位置由创建 PyTorch 对象时提供的 output_path 参数指定。
模型的验证
您将从 Amazon S3 下载经过训练的模型到笔记本所在实例的本地文件系统,下面的代码将载入模型,然后输入一个随机数,获得推理结果,以图片形式展现出来。执行如下指令加载训练好的模型,并通过这个模型产生一组『手写』数字字体。
from helper import *
import matplotlib.pyplot as plt
import numpy as np
import torch
from dcgan.model import Generator
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
params = {'nz': nz, 'nc': nc, 'ngf': ngf}
model = load_model(Generator, params, "./model/generator_state.pth", device=device)
img = generate_fake_handwriting(model, batch_size=batch_size, nz=nz, device=device)
plt.imshow(np.asarray(img))
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.

结论与总结
近些年成长快速的 PyTorch 框架正在得到广泛的认可和应用,越来越多的新模型采用 PyTorch 框架,也有模型被迁移到 PyTorch 上,或者基于 PyTorch 被完整再实现。生态环境持续丰富,应用领域不断拓展,PyTorch 已成为事实上的主流框架之一。Amazon SageMaker 与多种 AWS 服务紧密集成,比如,各种类型和尺寸的 Amazon EC2 计算实例、Amazon S3、Amazon ECR 等等,为机器学习工程实践提供了端到端的、一致的体验。Amazon SageMaker 持续支持主流机器学习框架,PyTorch 是这其中之一。用 PyTorch 开发的机器学习算法和模型,可以轻松移植到 Amazon SageMaker 的工程和服务环境里,进而利用 Amazon SageMaker 全托管的 Jupyter Notebook、训练容器镜像、服务容器镜像、训练任务管理、部署环境托管等功能,简化机器学习工程复杂度,提高生产效率,降低运维成本。
DCGAN 是生成对抗网络领域中具里程碑意义的一个,是现今很多复杂生成对抗网络的基石。文首提到的 StyleGAN,用文本合成图像的 StackGAN,从草图生成图像的Pix2pix,以及互联网上争议不断的 DeepFakes 等等,都有DCGAN的影子。相信通过本文的介绍和工程实践,对您了解生成对抗网络的原理和工程方法会有所帮助。