













我叫阿 Q,是 CPU 一号车间里的员工,我所在的这个 CPU 足足有 8 个核,就有 8 个车间,干起活来杠杠滴。
图片来自 Pexels
01.CPU 一味求快出事儿了
我所在的一号车间里,除了负责执行指令的我,还有负责取指令的小 A,负责分析指令的小胖和负责结果回写的老 K。
CPU 的每个车间都有一堆箱子,人们把这些箱子叫做寄存器,我所在的一号车间也不例外,我们每天的工作就是不断执行指令,然后折腾这些箱子,往里面存东西取东西。
由于我们四个人的出色工作,一号车间业绩突出,在年会上还多次获得了最佳 CPU 核心奖呢。
缓存
我们每天都需要跟内存打交道,不过由于内存这家伙实在太慢了,我们浪费了很多时间等待他给我们数据传输。
终于有一天,上面给我们下了命令,说竞争对手 CPU 的速度快赶上我们了,让我们想办法提升工作效率。
这一下可难倒了我们,我们平时干活绝没有偷懒,要怪只能怪内存那家伙,是他拖了我们后腿。
一天晚上,我们哥四个在一起聚餐,讨论起上面的这道命令来,大家都纷纷叹气。
就在一筹莫展之际,老 K 提出了一个想法:“兄弟们,我发现了一个现象,咱们和内存打交道的时候,如果访问了某个地址的数据,它周围的数据随后也大概率会被访问到”,说到这里,老 K 停顿了一下。
我一边听一边想着,小 A 倒是先开口:“然后呢?你想表达什么意思?”
老 K 继续说道:“咱每次数据都找内存要,太慢了,我寻思在咱们车间划一块区域,结合我发现的那个现象,以后让内存一次性把目标区域附近的数据一起给我们,我们存在这块区域,后面在需要用到的时候就先去这里找,找不到再去找内存要,岂不省事?”
听老 K 这么一描述,感觉靠谱,我也赶紧附和:“好办法!你们看啊,这内存老是拖咱后退,但是这家伙一时半会也快不起来,要不咱先用这招试试,看看能不能加快一点工作效率,给上面也有个交代。”
说干就干,我们很快就付诸实践了,我们还给这技术取了个名字叫缓存,效果居然出奇的好。
后来为了进一步优化,我们还把缓存分为了两块,一块离寄存器很近叫一级缓存,剩下的叫二级缓存。一级缓存中进一步分了指令缓存和数据缓存两块。

我们车间的工作效率那是飞速提升,但不知道是谁走漏了风声,其他几个车间也知道了这项技术,纷纷效仿。
这天,为了业绩,我们决定再加第三级缓存,这次把空间弄大点,不过咱们车间地盘有点局促,放不下,我们偷偷给上面领导反馈了这事儿,想让领导帮我们协调一下。
领导倒是同意了,不过告诉我们他得一碗水端平,平衡各车间的利益。但是咱厂里空间也有限,不可能给每个车间都分配那么大的空间,于是决定由厂里统一安排一块大的区域,让各个车间来共享。没有办法,我们也只好同意了。
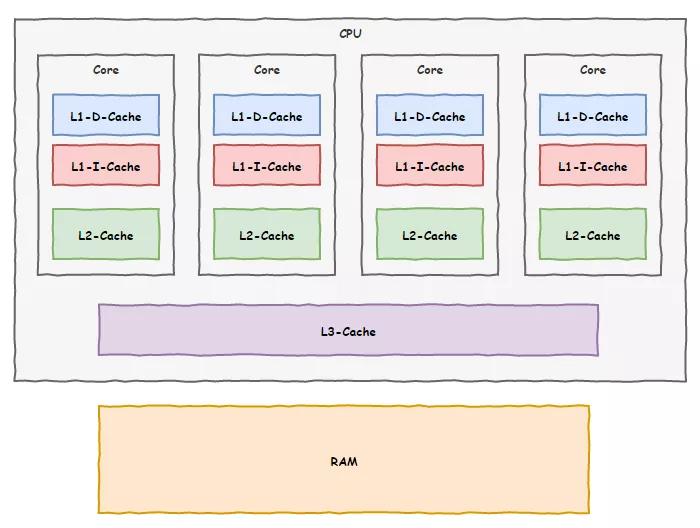
现在,我们用上了三级缓存技术,内存那家伙拖后腿的现象缓解了不少,相当部分时间我们都能从这三级缓存里面找到我们需要的数据。
乱序执行
随着技术的发展,咱们 CPU 工厂的工作性能也是不断攀升,慢慢的,我们几个又开始闲下来了,因为我们实在太快了,尽管有了缓存,但我们还是有了不少闲暇时间。
这天我还是像往常一样,小 A 取指令去了,我们知道这得要点时间,于是我和小胖还有老 K 我们仨斗起了地主。

打了好几把,小 A 才气喘吁吁的回来,“小胖,该你去指令分析了,你起来让我来打几把”。小胖赶紧起身干活,换上了小 A 上桌。
就这样我们几个轮流工作,一直保持着三个人的斗地主牌桌。
没想到的是,没过多久,厂里领导过来视察了,正好撞见我们几个打牌,狠狠的训斥了我们一顿。
“你们几个上班时间玩得挺嗨啊”,领导的脸拉的老长。
“领导,我们没有偷懒,这取指令、译码、执行、回写几个步骤都得分步执行,但是我们工作太快,存储器跟不上我们,我们等得无聊打发时间嘛”,我上前解释到。
“干等着你们也可以提前做一些后面的准备工作嘛,不要浪费时间,让生产效率更上一层楼”,领导说完就离开了,留下我们几个面面相觑。
不过领导的一番话倒是如一记重锤敲在我的头上,对啊,我们有这打牌的时间不如提前把后续指令的准备工作先做了,肯定能提升不少效率呢!
我开始组织兄弟几个商讨方案,“兄弟们,我们最主要的时间都浪费在等待内存数据上了,如果我们能在等待的时间里把后续指令需要的数据提前准备到缓存中来,那可就节约不少时间了,不用每次都等那么久。”
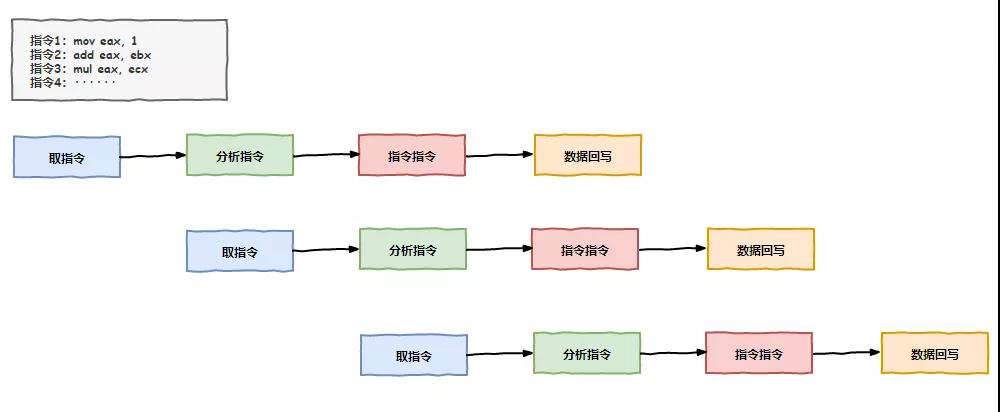
老 K 听后很赞赏我的思路,并补充到:“不仅是准备工作,像有些指令,比如加法,如果参与加法的数据不依赖前面指令的结果,咱们完全可以提前把这加法指令执行了嘛,把结果保存在缓存中,等真正轮到这条指令执行的时候,再把缓存中的结果写到内存中,这不也是节约了时间吗?”
大家开始头脑风暴起来,原来可以做的事情还这么多,之前光想着等靠要,现在要主动出击了,因为打乱了顺序提前会执行后面的指令,我们把这个技术叫做乱序执行。
“这次大家要保密哦,不能让隔壁车间知道咱们的这次讨论内容”,会议结束前,我提醒大家。
分支预测
按照这次会议讨论的结果,咱们第二天准备实行,不过刚一开始,就遇到了麻烦。
按照计划,我们在空闲时间里,会提前把后续要执行的指令能做的工作先做了,但麻烦的是我们遇到了一条判断指令。
因为不知道最终结果是 true 还是 false,我们没法知道后续是应该执行分支 A 的指令还是分支 B 的指令。不敢轻举妄动,怕一会做了无用功。
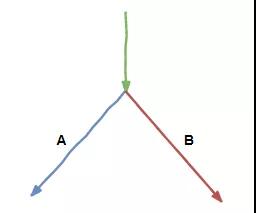
大家只好放弃了提前做准备工作的想法,还是一步步来。
不过很快我们发现,我们经常执行到这个判断指令,而且每次结果都是去执行 A 分支,从没有去过 B 分支。

于是我们几个又商量,发明了一种叫分支预测的技术,遇到分支跳转时,按照之前的经验,如果某个分支经常被执行,那后续再去这个分支的概率一定很大。
那这样咱们预测后面会去到这个分支,就提前把这个分支后面指令能做的工作先做了。
果然,用上了分支预测和乱序执行后,我们车间的效率又狠狠的提升了一把,在工厂的集体大会上又一次表扬了我们,并且把我们的先进技术向全厂推广,在我们 8 个 CPU 核心车间都铺开了,性能甩开竞争对手 CPU 几条街。
然而幸福的日子没过太长,我们就因为这两项技术闯下了弥天大祸。
02.CPU 成了黑客的帮凶
那天,我们还是如往常一般工作,可不久发现我们的分支预测频频出错,提前做的准备工作也屡屡白费,很快,我们发现出事儿了......

事情还得从不久前的一个晚上说起。
神秘代码
这天晚上,我们一号车间遇到了这样一段代码:
uint8_t array1[160] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
uint8_t array2[256 * 512];
uint8_t temp = 0;
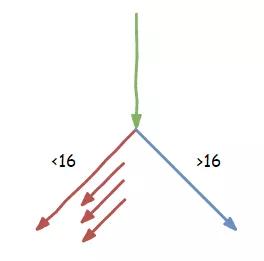
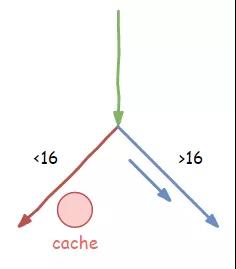
void bad_guy(int x) {
if (x < 16) {
temp &= array2[array1[x] * 512];
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
不到一会儿功夫,我们就执行了这个 bad_guy() 函数很多次,这不,又来了。
负责取指令的小 A 向内存那家伙打了一通电话,让内存把参数 x 的内容传输过来,我们知道,以内存那蜗牛的速度,估计得让我们好等。
这时,负责指令译码的小胖忍不住说了:“你们看,我们这都执行这个函数好多次了,每次的参数 x 都是小于 16 的,这一次估计也差不多,要不咱们启动分支预测功能,先把小于 16 分支里的指令先提前做一些?大家看怎么样”
我和负责数据回写的老 K 互相看了一眼,都点头表示同意。
于是,就在等待的间隙,我们又给内存那家伙打了电话,让他把 array1[x] 的内容也传过来。
等了一会儿,数据总算传了过来:
x: 2
array1[x]: 3
- 1.
- 2.
拿到结果之后,我们开始一边执行 x<16 的比较指令,一边继续打电话给内存索要 array2[3] 的内容。
比较指令执行的结果不出所料,果然是 true,接下来就要走入我们预测的分支,而我们提前已经将需要的数据准备到缓存中,省去了不少时间。
就这样,我们成功的预测了后续的路线,我们真是一群机智的小伙伴。
遭遇滑铁卢
天有不测风云,不久,事情发生了变化。
“呀!比较结果是 false,这一次的 x 比 16 大了”,我执行完结果后发现和我们预期的有了出入。
小 A 闻讯而来,“额,咱们提前执行了不该执行的指令不会有问题吧?”
老 K 安慰道:“没事儿,咱们只是提前把数据读到了我们的缓存中,没问题的,放心好啦”
我想了想也对,大不了我们提前做的准备工作白费了,没有多想就继续去执行>16 的分支指令了。
随后,同样的事情也时有发生,渐渐的我们就习惯了。
灾难降临
夜越来越深,我们都有点犯困了,突然,领导来了一通电话,让我们放下手里的工作火速去他办公室。
我们几个不敢耽误,赶紧出发。
来到领导的办公室,里面多了两个陌生人,其中一个还被绑着,领导眉头紧锁,气氛很是紧张。
“阿 Q 啊,你知不知道你们新发明的乱序执行和分支预测技术闯了大祸了?”
我们几个一听傻眼了,“领导,这是从何说起啊?”
领导从椅子上站了起来,指着旁边的陌生人说到:“给你们介绍一下,这是操作系统那边过来的安全员,让他告诉你们从何说起吧!”
这位安全员向大家点了点头,指着被捆绑那人说道:“大家好,我们抓到这个线程在读取系统内核空间的数据,经过我们的初审,他交代了是通过你们 CPU 的乱序执行和分支预测功能实现的这一目的。”
我和小 A 几个一听都是满脸问号,我们这两个提升工作效率的技术怎么就能泄漏系统内核数据呢?
真相大白
安全员显然看出了我们的疑惑,指着被捆绑的那个线程说道:“你把之前交代的再说一遍”
“几位大爷,你们之前是不是遇到了分支预测失败的情况?”,那人抬头看着我们。
“有啊,跟这有什么关系?失败了很正常嘛,既然是预测那就不能 100% 打包票能预测正确啊”,我回答道。
“您说的没错,不过如果这个失败是我故意策划的呢?”
听他这么一说,我的心一下悬了起来,“纳尼,你干的?”
“是的,就是我,我先故意给你连续多次小于 16 的参数,误导你们,误以为后面的参数还是小于 16 的,然后突然来一个特意构造的大于 16 的参数,你们果然上钩了,预测失败,提前执行了一些本不该执行的指令。”
“那又如何呢?我们只是把后面需要的数据提前准备到了缓存中,并没有进一步做什么啊”,我还是不太明白。
“这就够了!”
“你小子都被捆上了,就别吊胃口了,一次把话说清楚”,一旁急性子的老 K 忍不住了。
“好好好,我这就交代。你们把数据提前准备到了缓存中,我后面去访问这部分数据的时候,发现比访问其他内存快了很多”
“那可不,我们的缓存技术可不是吹牛的!哎等等,怎么又扯到缓存上去了?”,老 K 继续问道。
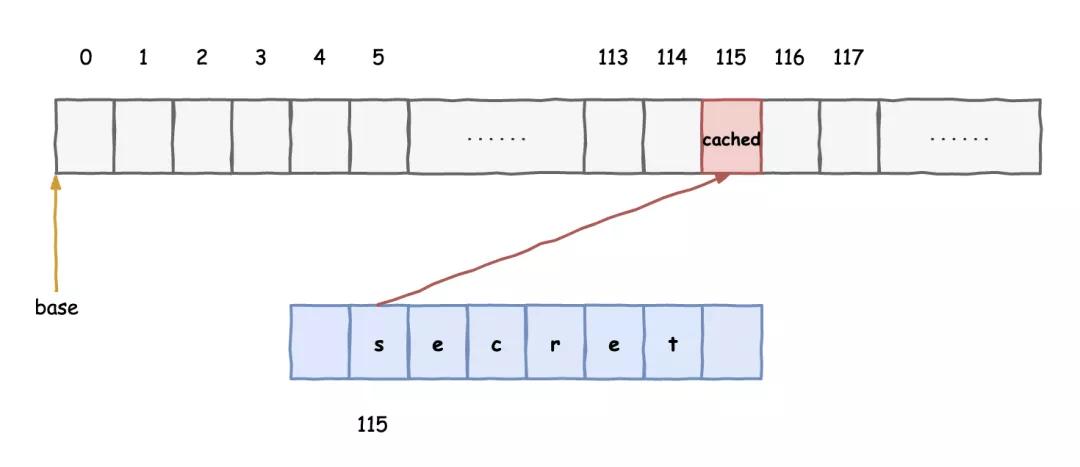
那人继续说道:“如果我想知道某个地址单元内的值,我就以它作为数组的偏移,去访问一片内存区域。利用你们会提前预测执行而且会把数据缓存的机制。你们虽然预测失败了,但对应的那一块数据已经在缓存中了,接着,我依次去访问那一片内存,看看谁的访问时间明显比其他部分短,那就知道哪一块被缓存了,再接着反推就能知道作为偏移的数值是多少了,按照这个思路我可以知道每一个地址单元的内容。”
我们几个一边听着一边想着,琢磨了好一会儿总算弄清楚了这家伙的套路,老 K 气得火冒三丈,差点就想动手修理那人。
“好你个家伙,倒是挺聪明的,可惜都不用在正途上!好好的加速优化机制竟然成为了你们的帮凶”,我心中也有一团火气。
亡羊补牢
事情的真相总算弄清楚了,我们几个此刻已经汗流浃背。
经过和安全员的协商,操作系统那边推出了全新的 KPTI 技术来解决这个问题,也就是内核页表隔离。
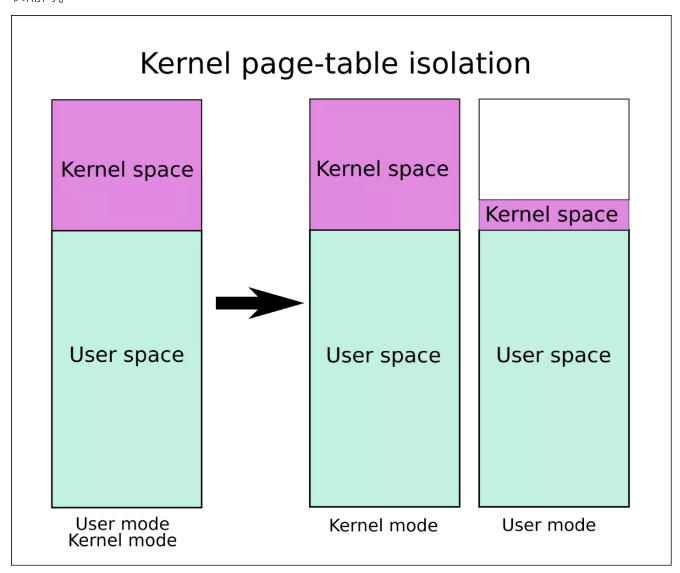
以前的时候,线程执行在用户态和内核态时用的是同一本地址翻译手册,也就是人们说的页表,通过这本手册,我们 CPU 就能通过虚拟地址找到真实的内存页面。
现在好了,让线程运行在用户态和内核态时使用不同的手册,用户态线程的手册中,内核地址空间部分是一片空白,来一招釜底抽薪!
本以为我们可以回去了,没想到领导却给我们出了难题,“这祸是你们闯下的,人家操作系统那边虽然做了保护,你们是不是也该拿出点办法来呢,要不然以后我们 CPU 还怎么抬得起头来?”
你有什么好办法吗,帮帮我们吧!
幕后
本节描述的是两年前爆发的大名鼎鼎的 CPU 的熔断与幽灵漏洞。
乱序执行与分支预测是现代处理器普遍采用的优化机制。和传统软件漏洞不同,硬件级别的漏洞影响更大更深也更难以修复。
通过判断内存的访问速度来获知是否有被缓存,这类技术有一个专门的术语叫侧信道,即通过一些场外信息来分析得出重要结论,进而达成正常途径无法达成的目的。
03.CPU 瞒着内存竟干出这种事
今天忙里偷闲,来到厂里地址翻译部门转转,负责这项工作的小黑正忙得满头大汗。
看到我的到来,小黑指着旁边的座椅示意让我坐下。
坐了好一会儿,小黑才从工位上忙完转过身来,“实在不好意思阿 Q,今天活太多,没来得及招待你”
“刚忙什么呢,看你满头大汗的”,我问道。
“嗨,别提了,老是发现内存页面错误,不停地要通知操作系统那边去处理,真是怀念以前啊,没有这么多破事儿要管”,小黑叹了口气。
我一听来了兴趣,“小黑你给我说说你们的工作呗,地址翻译是怎么一回事儿,为什么怀念以前呢?”
小黑调整了下坐姿,咕噜咕噜喝了几口水说道,“这话说来可就话长了”
接下来小黑开始给我讲起了历史故事......
8086
原来咱们的祖先叫 8086,小黑还给我看了他的照片:

那是一个纯真质朴的年代,虽然工作性能不高,不过那个年代的程序都很简单,我们的祖先一问世就成为了明星,称得上那个时代的顶流了。
看到照片中的那些金属针脚了吗?那是我们 CPU 和外界打交道的触角,每一根都有不同的作用。
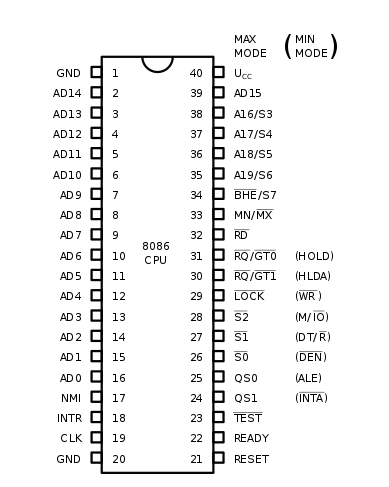
通过这些触角,CPU 就可以跟内存打交道,获取指令和数据,辛勤的干活啦。
那个年代,条件比较差,能凑合的就凑合,能共用的就共用。这不,你看祖先 CPU 的地址总线针脚和数据总线针脚就共用了。
祖先是一个 16 位的 CPU,数据(Data)总线就有 16 位,一次性可以传输 16 个比特位。和地址(Address)总线凑合着一起共用,于是就取名 AD0-AD15。
不过祖先的地址总线却不止 16 个,还多出了 A16-A19 整整 4 个呢!这样有 20 个地址线,可以寻址 1MB 的内存了!
但是祖先的寄存器都是 16 位的啊,只能存放 16 位的地址。不过他们很聪明,发明了一个叫分段式存储管理的方法,把内存划分为最大 64KB 的小块,为什么是 64KB 呢,因为 16 位地址最多只能寻址这么大了。
然后又加了几个叫做段寄存器的东西,指向这些块的开头,这样,通过段地址+段内偏移地址的方式,就能访问更多的内存了。
32 位时代
后来啊,祖先的那点计算能力越来越捉襟见肘,实在是跟不上时代了。家族中的年轻一代开始挑大梁,80286 和 80386CPU 相继问世,尤其是 80386,成为了划时代的存在。

到了 80386 时代,我们与外界通信的引脚就更多了,并且变成了 32 位的 CPU,那个时候,生活条件就变好了,地址线和数据线再也不用共享引脚了。
后来,人类变得越来越贪心,想要一边听音乐,一边还要上网,同时还要编辑文档,这就同时需要运行多个程序。
这个时候,有人发现了商机,开发了一个叫操作系统的东西,原来那些程序不再直接和我们 CPU 打交道了,而是和操作系统打交道,操作系统再和我们打交道,中间商赚差价说的就是他们!
操作系统这玩意儿很聪明啊,通过时间片划分让我们 CPU 来轮流执行多个程序,一会儿让我们执行音乐播放,一会儿让我们执行浏览器程序,一会儿又让我们执行文档编辑程序。
我们是无所谓啊,给什么代码不是代码啊,我们不挑,埋头苦干就是了。人类的反应速度跟我们就差得远了,他们还以为这些程序真的是同时执行的呢。
虚拟内存
不过随之而来出现了一个大问题,这么多程序都要运行,大家挤在一个内存里,经常发生摩擦,冲突不断。

先祖们为了此事殚精竭虑,终于想出了一个好办法,一直沿用至今。
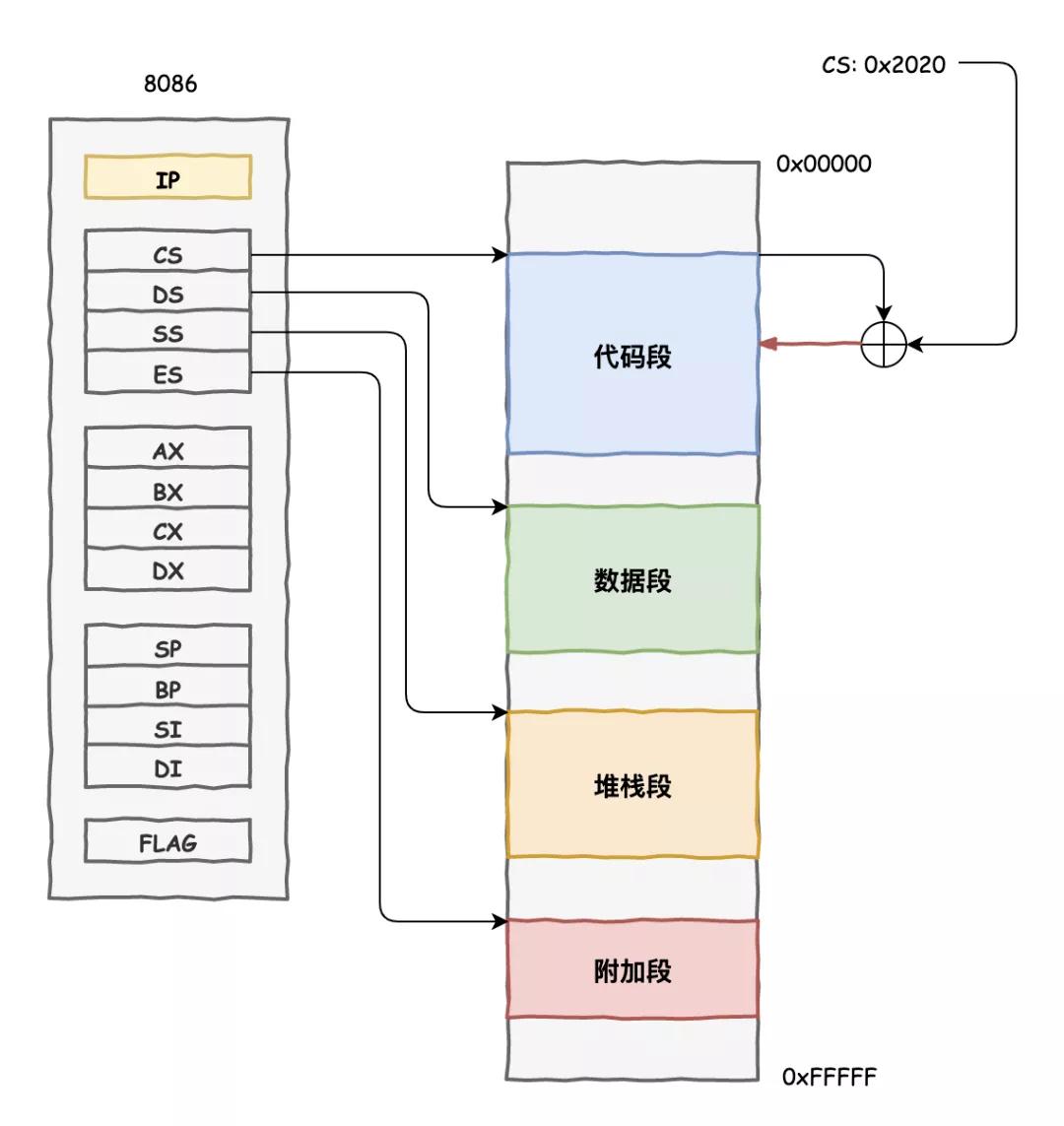
他们提出了一个虚拟地址的东西,所有程序使用的地址都是一个虚拟的地址,在真正和内存打交道的时候,咱们 CPU 内部工作人员再给翻译成真实的内存地址,关于这事儿,内存那家伙一直被我们蒙在鼓里。
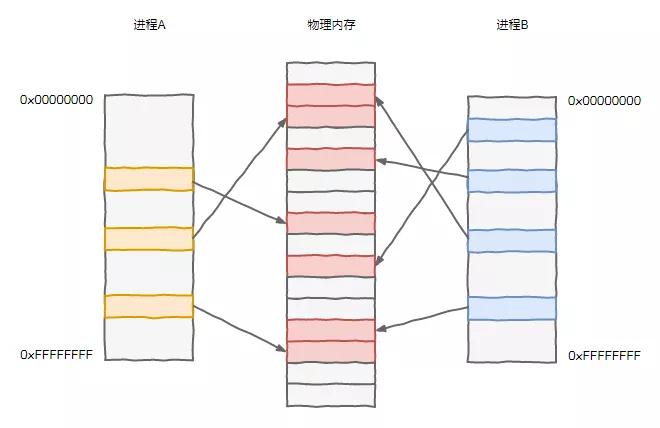
这样一来,每个程序都可以用的是 0x00000000 到 0xffffffff 总共 4GB 这么大范围的地址空间,当然不会真的给他们那么多空间,内存那家伙总共才 4GB 呢,而是要按需申请分配。
分配的单元是按照页来进行的,32 位的 CPU 一个页是 4KB。这些分配管理的累活就让操作系统来干了,中间商不能光拿好处不干正事,至于我们 CPU,做好地址翻译的工作就好了。
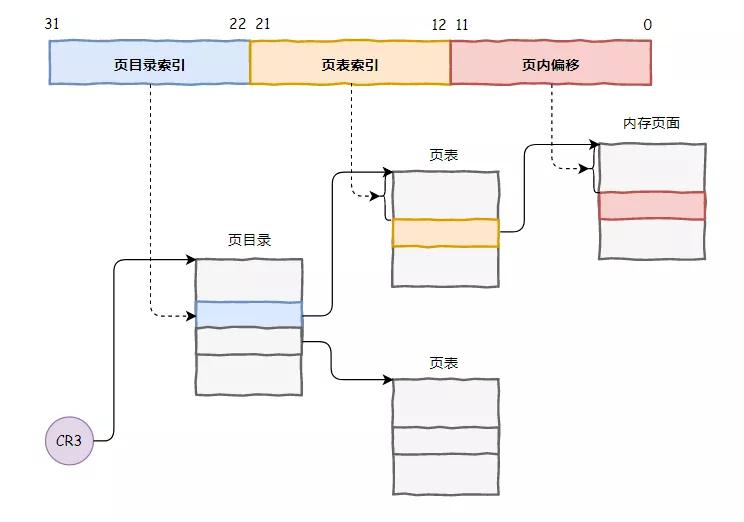
为此,在我们寄存器内部专门添置了一个新的寄存器 CR3,用来指向一个地址翻译查询字典,字典划分了两级目录。
我们把一个 32 位的地址划分了 3 部分,前面两部分分别指向两级目录中的条目,用来定位这个地址在物理内存的哪个页面,最后一部分就是指向物理内存页面的偏移,这样就完成了地址的翻译工作。
每个进程有不同的地址空间,切换进程的时候,把 CR3 的内容换一下就使用新进程的翻译字典,特别的方便。
我们把这种内存管理方式叫做分页式内存管理。
真佩服先祖们的智慧,这样巧妙的把各个程序隔离开来,后来我们把这种工作模式叫做保护模式,把之前那种直接使用真实内存地址的工作模式叫做实地址模式。
分页交换
人类变得越来越贪婪,程序变得越来越多,对内存的需求也越来越大。随着这些程序都不断申请内存页面,内存空间很快就要耗尽了。
我们看在眼里,急在心里,后来找操作系统协商,看看这问题该怎么办。
操作系统那家伙也不赖,想出了一个好办法。内存的大小有限,但是硬盘给力啊,硬盘空间大的多,去硬盘上划一块区域来,把内存里长时间没有用到的页面给换到这块区域里去,然后做个标记。
如果后面谁要访问那个页面,咱们 CPU 就检查如果有这个标记,就发送一个页错误的中断信号告诉操作系统去把这个页面换回来。
通过我们之间的配合,解决了内存紧张的危机。后来我们把这个技术叫做内存分页交换。
现在
时间过得很快,到了我们这一辈,内存变得更大了,16GB 都是小 case,32GB 也很常见。
除了内存,我们 CPU 本身也更先进了,别的不说,你光看看咱们现在的引脚数那比先祖们那几辈就不可同日而语。

我们不仅从 32 位变成了 64 位,还从单核变成了多核,像我所在的 CPU 就有 8 个车间,8 核并行执行,比起先祖那个年代简直有云泥之别。
04.就为了一个原子操作 其他 CPU 核心罢工了
和小黑闲谈间,我们车间的老 K 突然出现在了门口。
“阿 Q 原来你在这里,让我好找,赶快回去吧,隔壁二号车间的虎子说我们改了他们的数据,上门来闹事了······”
i++ 问题
由于老 K 的突然出现,我不得不提前结束与小黑的交流,赶回了 CPU 一号车间。
见到我回来,虎子立刻朝我嚷嚷:“你们是怎么回事?才几纳秒的时间,就把数据给我改了,你说这事怎么办吧!”
我听着迷迷糊糊的,连连说到:“虎子你先别急,我刚回来,到底出什么事儿了,先让我了解清楚好不好?”
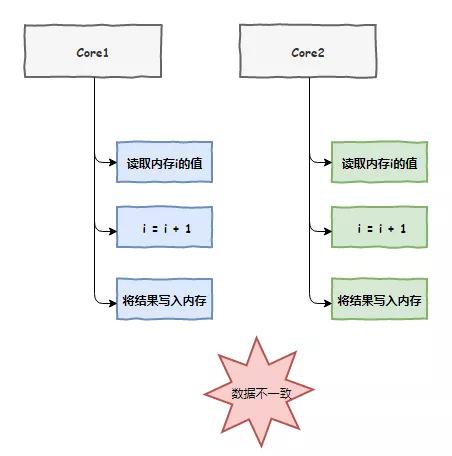
接下来,老 K 把事情的经过告诉了我。原来,我们两个 CPU 车间各自负责的线程都在执行一个 i++ 的操作,我们都把i的值放到了自己的缓存中,完了之后都没有通知对方,加了两次但结果却只有一次,出现了数据不一致问题。
原子操作
了解清楚事情的原委之后,我向虎子说道:“大家都执行一样的代码,这事儿也不能怪我们啊”
虎子一听急了,“怎么不怪你们了,我们比你们先一步找内存拿走了i,那你们得等我们加完之后再用啊,不信你可以打电话问内存那家伙,看看是不是我们二号车间先来的”
“好好好,你先冷静一下,你看我们又不知道你们先去拿了,这不情有可原吗,再说现在事情已经出了,我们应该一起坐下来想个办法避免以后再次出现这种问题,你说是不是?”
虎子叹了口气问道:“那你说说你有什么办法?”
我继续说道:“你看啊,像咱们在执行i++这种操作的时候就不应该被干扰”
“不被干扰?”
“对,比如虎子你们二号车间在访问i的时候,我们一号车间就不能访问,需要等着,等你们访问完成我们再来,非常简单的办法却很有用”
虎子听完一愣,“这不就是加锁吗?你是想怪程序员做 i++ 前没有加锁?”
“的确是加锁,不过这种简单操作还要程序员来加锁那也太麻烦了,咱们 CPU 内部处理好就行了”
“内部处理,你打算怎么实现?”,虎子问到。
“这,,让我想想···”,虎子问到了具体实现,我倒还没想到这一步。
这时,一旁的老 K 站了出来:“我倒是有个办法,可以找总线主任啊,他是负责协调各个车间使用系统总线访问内存的总指挥,让他在中间协调一下应该不难”
老 K 一语点醒梦中人,接着我们就去找了总线主任,后来我们商量出了一套解决方案:我们定义了一个叫原子操作的东西,表示这是一个不可切分的动作,谁要执行原子操作,总线主任就在系统总线上加上一个 LOCK# 信号,其他车间的想去访问内存就得等着,直到原子操作指令执行完毕。
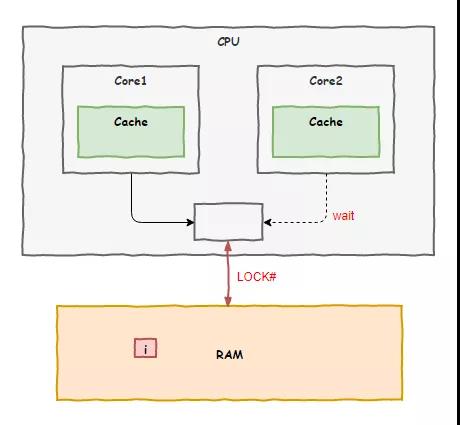
我们把这套方案上报了领导,很快就批下来了,后面我们 8 个车间都按照这套方案来工作,以后程序员们把 i++ 这样的动作换成原子操作后,问题就能迎刃而解。
不过施行了一段时间之后,各个车间却开始大倒苦水:就因为某个车间要执行一个原子操作,就让总线主任把系统总线锁住,其他车间的人都没法访问内存,都干不了活了,严重影响工作效率。
抱怨归抱怨,在没有更好的替代方案出现之前,日子还得过下去。
缓存引发的问题
不过,没过多久,数据不一致问题又一次出现了。
这一次,倒不是加法的问题,我们两车间还是因为各自缓存的原因,先后修改了变量的值,对方没有即时知道,误用了错误的值,以致酿成大错。
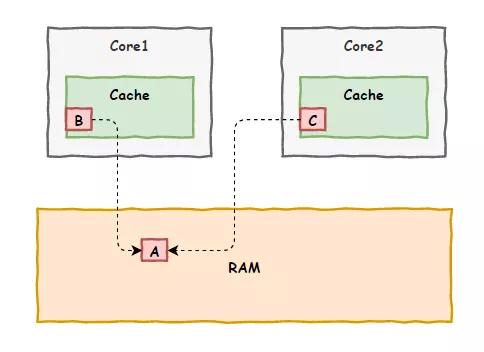
“阿 Q,上次那办法好是好,可解决不了这一次的问题啊”,虎子再次找上门来。
“你来的正好,我正想去找你说这事呢”
“哦,是吗,难不成你想到破解之道了?”
“只是一些初步的想法,问题的核心在于现在咱们各个车间各自为政,都有自己的私有缓存,各自修改数据后向内存更新时也不互相打招呼,缺少一个联络机制”
虎子点了点头,“确实,所以咱们需要建立一个联络机制,来对各个车间的缓存内容进行统一管理是吗?”
“对!这事儿咱俩说了可不算,我建议召集 8 个核心车间的代表,统一开一个会议,详细讨论下这个问题。哦,对了,把总线主任也叫上,他经验丰富说不定能提供一些思路”
缓存一致性协议 MESI
很快,咱们 CPU 的 8 个核心车间就为此问题召开了会议,并且取得了非常重要的成果。
我们牵了一条新的专线,把 8 个核心车间连接起来,用于各个车间之间进行信息沟通,不同于 CPU 外部的总线系统,大家把这个叫片内总线。
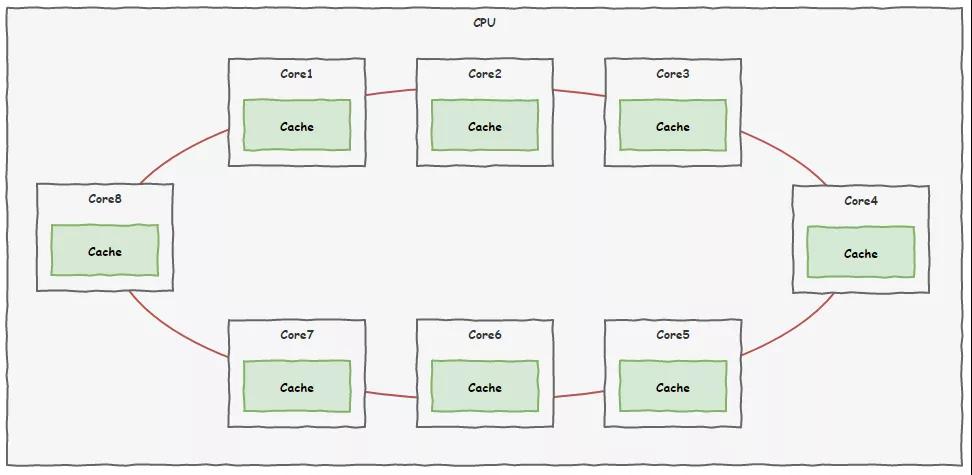
新的线路铺设好了,以后大家就可以通过这条线路即时沟通,为了解决之前出现的问题,大家还制定了一套规则,叫做缓存一致性协议。
规则里面规定了所有车间的缓存单元——缓存行有四种状态:
已修改 Modified (M):缓存行已经被修改了,与内存的值不一样。如果别的 CPU 内核要读内存这块数据,要赶在这之前把该缓存行回写到主存,把状态变为共享 (S)。
独占 Exclusive (E):缓存行只在当前 CPU 核心缓存中,而且和内存中数据一样。
当别的 CPU 核心读取它时,状态变为共享;如果当前 CPU 核心修改了它,就要变为已修改状态。
共享 Shared (S):缓存行存在于多个 CP U核心的缓存中,而且和内存中的内容一致。
无效 Invalid (I):缓存行是无效的。
四种状态之间的转换是这样的:
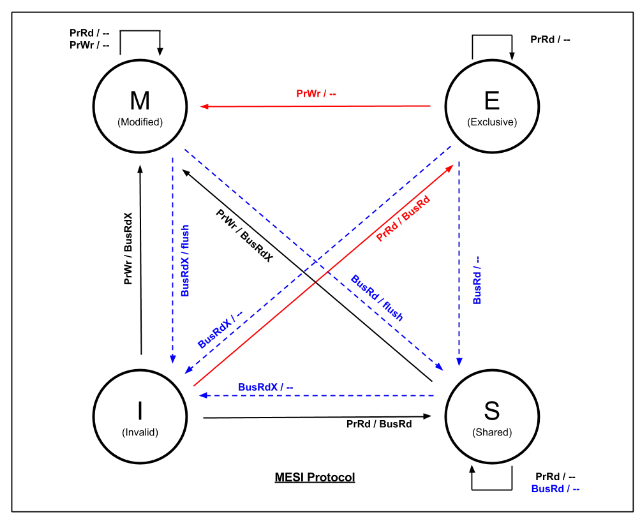
按照这套规则,大家不能再像以前那样随意了,各车间对自家缓存进行读写时,都要相互通一下气,避免使用过时的数据。
除此之外,还规定如果一块内存区域被多个车间都缓存,就不再允许多个车间同时去修改缓存了。
会议还有另外一个收获,以前被各车间诟病的每次原子操作都要锁定总线,导致大家需要访问内存的都只能干等着的问题也得到了解决。以后总线主任不再需要锁定总线了,通过这次的缓存一致性协议就可以办到。
自此以后,数据不一致的问题总算是根治了,咱们 8 个车间又可以愉快的工作了。
作者:轩辕之风
编辑:陶家龙
出处:转载自微信公众号编程技术宇宙(ID:ProgramUniverse)















