作为最为流行的开源数据库,MYSQL正成为越来越多企业的选择。MySQL数据库大量应用在各种业务系统,除了在线业务逻辑的读写,还会有一些额外的数据分析需求,如BI报表、可视化大屏、大数据应用等。但受限于MySQL架构等问题,在面对数据分析场景时,其往往力不从心。
针对这种情况,业内有很多种解决方案。这里特推荐一种新的方式 — 数据湖分析,在面对低成本场景时是个不错的选择。在展开正式内容之前,对数据湖这个还较为陌生的概念做个简单介绍。
数据湖,是一种Serverless化的交互式联邦查询服务。使用标准SQL即可分析与集成对象存储(OSS)、数据库(PostgreSQL/MySQL等)、NoSQL(TableStore等)数据源的数据。
01. 方案背景
- 需求场景一
MySQL数据库大量应用在各种业务系统,除了在线业务逻辑的读写,还会有一些额外的数据分析需求,如BI报表、可视化大屏、大数据应用等。随着业务的发展,单机MySQL数据库达到一定的数据量后,直接使用MySQL做数据分析性能比较差,而且会影响在线业务的读写性能。这种情况下就需要寻求新的数据分析方案。
- 需求场景二
MySQL中的数据需要和日志数据做联合分析,这种场景下有些公司会使用开源的大数据系统(如Hive,Hadoop,Spark等)搭建数据仓库,这个方法虽然能解决问题,但它所需的人力成本和服务器等资源成本却是最高的。如何才能低成本的把MySQL与其他系统的数据做联合分析?
- 需求场景三
当MySQL中数据量超过单机性能后,为了保证在线业务性能,DBA通常会采用分库分表技术,将一个数据库中的单张表数据拆分到多个数据库的多张表中。由于一个逻辑表被拆成多张表,这时候如果要进行数据分析,将会变得十分复杂。需要新的分析方案来解决。
02. 案评估因素
MySQL分析场景中,如果要解决上述三个场景问题,主要考虑的因素有哪些?如果有多种解决方案,应该如何选择?可以参考以下几个关键因素。
1.成本因素
这里谈到的成本,是个综合的概念,不单指经济成本,还包括时间、人力、风险成本等。用户做方案选择时,要考虑综合的“性价比”。
2.能力因素
能力维度包括两个方面,即功能和性能。功能上,方案是否提供了完备的分析能力及扩展能力。性能上,是否满足用户的对时效性、并行性的要求,特别是在海量规模下。
3.可维护性
好的产品,应该是提供良好的可维护性。用户可通过很简洁的方式使用它。当出现问题的时候,也可以很容易排查解决。
4.易用性
产品自身应具有良好的易用性。用户只需要很低的门槛即可使用到数据分析服务。
03. 方案选择
针对MySQL数据的分析场景,有多种解决方案,包括直接在MySQL只读实例上分析、自建开源数据仓库和数据湖构建方案。下面让我们详细看看这些方案的优缺点。
基于MySQL只读实例分析
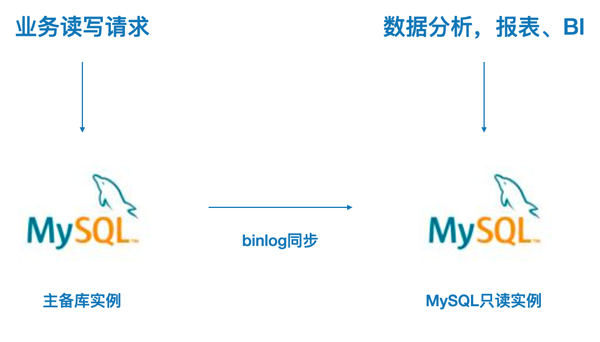
通过额外购买服务器搭建MySQL只读备库实例,然后基于只读实例做数据分析。这个方案的优缺点:
缺点:
- 功能不能无法满足需求场景二和场景三,即使针对需求场景一,当数据量增大时(参考下文TPC-H 10G SQL耗时),基于只读实例的分析性能会非常差。
- 成本较高:额外购买的只读实例成本也比较高。
优点:
- 方案简单,能防止对在线业务产生影响;易用性、兼容性好。
自建开源数据仓库
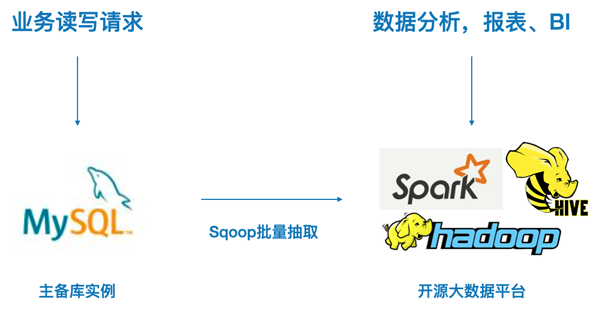
使用开源大数据系统(如Hive,Hadoop,Spark等)搭建数据仓库,然后同步MySQL数据到数据仓库,再基于Spark或Hive进行数据分析。
缺点:
- 易用性差:开源大数据系统使用门槛比较高,需要专门的大数据工程师来操作和运维;此外Sqoop同步不支持表结构变更,增加和删除列都会导致同步失败。
- 成本最高:另外还需要额外购买服务器搭建系统,增加了硬件成本,这个方案整体成本最高。
优点:
- 能解决需求场景一和二的问题,分析性能较好。
分析型数据库
使用开源或商用的分析型数据库,通过数据同步工具完成数据同步,再基于SQL进行数据分析。
缺点:
- 可维护性差,需要专门运维人员。
- 成本较高,需额外购买资源。
优点:
- 满足海量规模的数据分析
数据湖构建方案
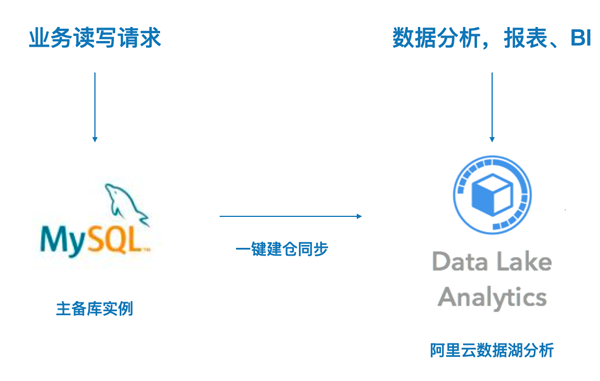
基于阿里云数据湖分析构建方案,它能完美的解决低成本分析MySQL数据的需求。
优点:
- 方便易用:使用一键建仓可以很轻松把整个数据库同步到数据湖。
- 分析能力强:数据湖分析(Data Lake Analytics)与MySQL体验完全相同,数据量增加对分析性能几乎没有影响。
- 成本极低:不需要购买服务器,按查询量计费,无查询不收费;无维护成本。
- 对源库影响:数据分析对在线业务无影响。
04. 数据湖构建方案评测数据及技术原理
接下来让我们详细看一下数据湖构建方案的评测数据和技术原理。
低成本高性能
- 低成本
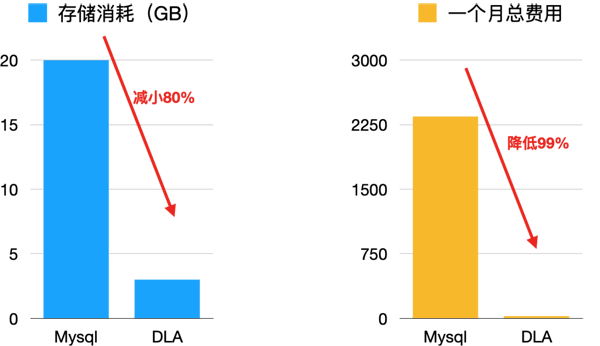
下面是成本的对比,额外购买一台高性能RDS(MySQL数据库)包月费用需2344元;以TPC-H 10G为例,如果每天执行一次TPC-H的22条SQL,使用DLA一个月的费用只需要26.64元,平均每天不到1元。只需1%的成本就能获取高性能的分析;此外DLA的列式存储消耗只需要3G,而原生Mysql的存储可能消耗约20G。
- 高性能
数据湖构建把数据从源数据库同步后,使用列式+压缩的方式存储,以TPC-H 10G的数据为例,存储在MySQL将消耗大约20G存储,但使用列式+压缩方式存储只消耗约3G存储。
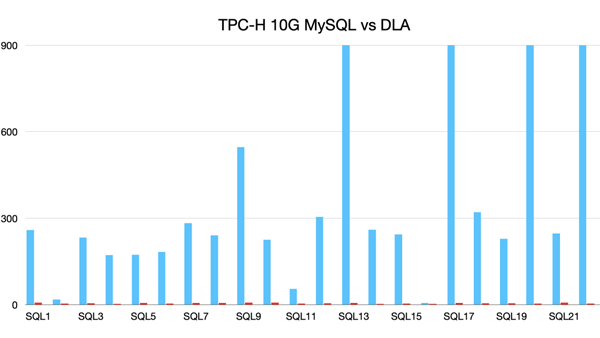
使用阿里云数据湖分析(DLA)分析,能以极低的成本获得高效的分析,再次以TPC-H 10G的数据为例,TPC-H的22条SQL在DLA执行耗时平均为5.5s,在MySQL中平均耗时为345.5s,且有4条SQL跑不出来。
下图TPC-H 10G 22条SQL在MySQL和DLA的耗时对比。
易用性
- 支持丰富数据源
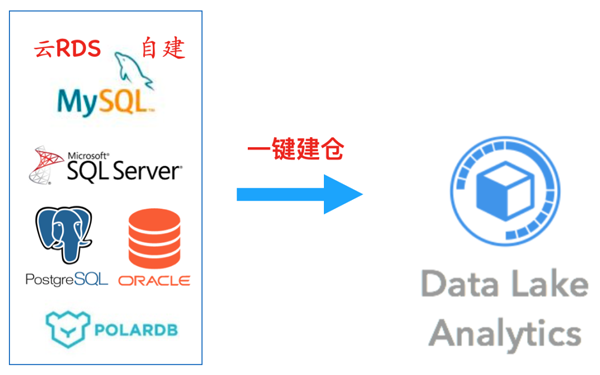
阿里云数据湖分析构建方案,支持丰富的数据源,包括自建的MySQL、SQLServer、PostgreSQL、Oracle、云数据库RDS、PolarDB、ADB等。与传统的数据仓库相比,它的设计目标是"简单",让用户通过简单的配置就能实现数据同步到DLA,真正实现"一键"建仓。
- 自动同步保持数据一致
数据湖构建支持自动同步更新的数据,也能自动同步包括创建表,删除表,新增列、修改列、删除列等元数据操作。在分库分表的场景中,数据湖构建能把一张分布在多个数据库的逻辑表合并到一张表中,实现基于一张表做数据分析。此外数据湖构建支持同步的表数量无上限限制。
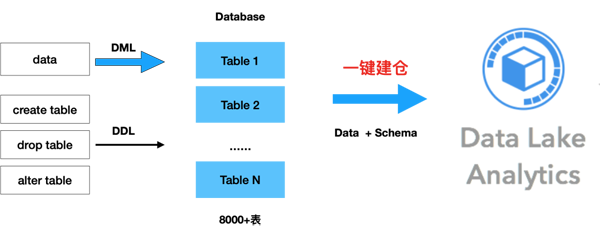
- 增量构建
数据湖分析(DLA)团队正在研发数据湖增量构建以支持增量模式同步源库数据,能完全消除对源库产生的影响;并且能大大提升数据分析的时效性。增量构建将于近期发布上线,敬请期待。
- 对源库影响
基于数据湖分析查询对源库完全无影响;在数据湖从源库同步数据时,对源库的影响也保证在10%以内。下图是数据湖构建针对不同规格源数据库的CPU消耗:随着机器规格增大,连接数会自动增加,最终源库的平均CPU消耗都在10%以内。
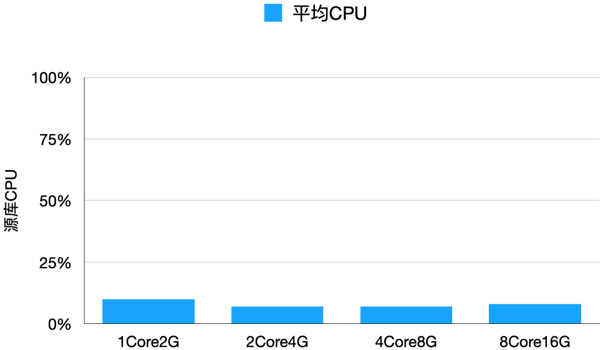
为了尽量减低同步对源数据库的影响,数据湖构建做了大量的优化。包括:
- 数据湖构建会自动根据源数据库的机器规格,动态调整连接数,能保证对源数据库的压力在10%以内。
- 在并发同步一张表时,优先选择索引列做切分,通过索引快速定位一段数据范围,减小同步对源数据库的影响。
- 数据湖构建默认选择业务低谷做数据同步,防止影响线上业务。
最终实现对源库的压力几乎可以忽略。如果用户希望加快同步速度,也可以手动增加连接数加快同步速度。
05. 阿里云数据湖实践
如果你希望试用数据湖分析构建MySQL低成本分析,只需要以下步骤即可开通试用。
1、登录Data Lake Analytics管理控制台。在页面左上角,选择DLA所在地域。(https://datalakeanalytics.console.aliyun.com)
2、在左侧导航栏单击解决方案。在解决方案页面,单击一键建仓中的进入向导。
3、根据页面提示,进行参数配置。
4、完成上述参数配置后,单击创建,就可以开始使用数据湖愉快的分析了。