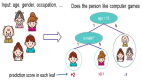
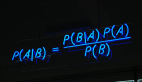【51CTO.com快译】
这个问题没有简单明了的答案。答案取决于许多因素,比如问题陈述、预期的输出类型、数据的类型和大小、可用的计算时间、特征数量以及数据中的观测点等。
选择算法时,有几个重要因素要考虑。
1. 训练数据的大小
通常建议收集大量数据以获得可靠的预测。但很多时候,数据的可用性是个约束。因此,如果训练数据较小,或者数据集的观测点数量较少,而遗传或文本数据等特征数量较多,应选择具有高偏差/低方差的算法,比如线性回归、朴素贝叶斯或线性SVM。
如果训练数据足够大,观测点数量比特征数量多,可以采用低偏差/高方差算法,比如KNN、决策树或内核SVM。
2. 输出的准确性及/或可解释性
模型的准确性意味着函数可预测特定观测点的响应值,该响应值接近该观测点的真实响应值。一种高度可解释的算法(诸如线性回归等限制性模型)意味着,人们可以轻松理解任何单个预测变量与响应有怎样的关联,而灵活的模型以低可解释性换取更高的准确性。

图1. 使用不同的统计学习方法来表示准确性和可解释性之间的取舍。
一些算法名为“限制性”算法,因为它们会生成小范围的映射函数形状。比如说,线性回归是一种限制性方法,因为它只能生成线性函数,例如直线。
一些算法被称为灵活算法,因为它们可以生成更广泛范围的映射函数形状。比如说,k = 1的KNN有高度灵活性,因为它会考虑每个输入数据点以生成映射输出函数。下图显示了灵活算法和限制性算法之间的取舍。
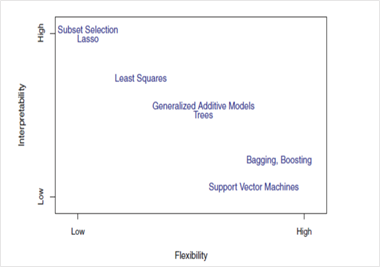
图2. 使用不同的统计学习方法来表示灵活性和可解释性之间的取舍。
现在,使用哪种算法取决于业务问题的目标。如果推理是目标,那么限制性模型更好,因为它们极容易解释。如果更高的准确度是目标,灵活模型更好。随着方法的灵活性提高,可解释性通常随之下降。
3. 速度或训练时间
更高的准确度通常意味着更长的训练时间。而且,算法需要更多时间来训练庞大的训练数据。在实际应用中,算法的选择主要取决于这两个因素。
朴素贝叶斯和线性与逻辑回归等算法易于实现且运行迅速。像需要调整参数的SVM、收敛时间长的神经网络和随机森林这些算法需要大量时间来训练数据。
4.线性度
许多算法都基于这一假设:类可以用直线(或其高维模拟)来分隔。例子包括逻辑回归和支持向量机。线性回归算法假设数据趋势遵循一条直线。如果数据是线性的,则这些算法执行起来效果很好。
然而,数据并非总是线性的,因此我们需要其他能够处理高维和复杂数据结构的算法。例子包括内核SVM、随机森林和神经网络。
找出线性度的最佳方法是拟合线性线,或者运行逻辑回归或SVM以检查残差。较高的误差意味着数据不是线性的,需要复杂的算法才能拟合。
5. 特征数量
数据集可能有大量的特征,这些特征可能并非全部相关且重要。对于某个类型的数据,比如遗传或文本数据,特征的数量与数据点的数量相比可能非常大。
大量特征可能会使一些学习算法陷入困境,从而导致训练时间过长。SVM更适合数据有庞大特征空间且观测点较少的情况。应该使用PCA和特征选择方法来减少维度,并选择重要特征。
下面这个方便的速查表详细介绍了可用于解决不同类型的机器学习问题的算法。
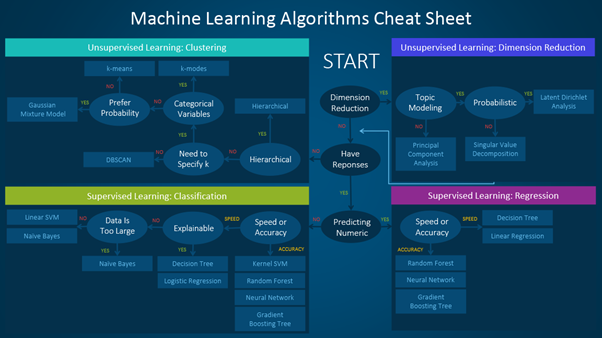
机器学习算法可以分为监督学习、无监督学习和强化学习。本文介绍如何使用该速查表的过程。
速查表主要分为两种学习类型:
- 在训练数据拥有与输入变量相对应的输出变量的情况下,采用监督学习算法。该算法分析输入数据并学习函数,以映射输入变量和输出变量之间的关系。
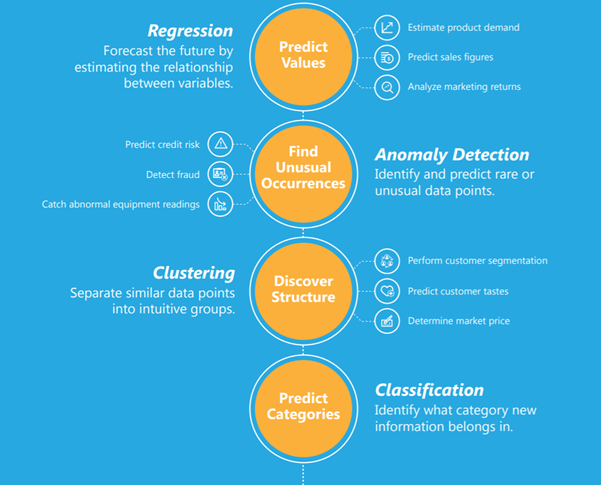
监督学习可以进一步分为回归、分类、预测和异常检测。
- 训练数据没有响应变量时,使用无监督学习算法。这类算法试图找到数据中的固有模式和隐藏结构。聚类和降维算法是无监督学习算法的两种类型。
以下信息图只解释了回归、分类、异常检测和聚类,以及可以运用这每一种方法的例子。
试图解决新问题时要考虑的主要点是:
- 定义问题。问题的目的是什么?
- 探究数据并熟悉数据。
- 从基本模型入手以构建一个基准模型,然后尝试更复杂的方法。
话虽如此,请记住:“更好的数据常常胜过更好的算法”。同样重要的是设计良好的特征。尝试一堆算法,并比较其性能,以选择最适合您特定任务的算法。另外,请尝试集成(ensemble)方法,因为它们通常提供极高的准确性。
原文标题:An easy guide to choose the right Machine Learning algorithm,作者:Yogita Kinha
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】