WordCloud是一种很好的展现数据的方式,网上也有不少小工具和在线网页。
但是有些不支持中文,有些安装复杂,所以决定用Python实现。
主要参考官网,通过官网的例子,讲一下WordCloud的制作。
主要流程
- 获取内容的路径
- 如果是一段文字,系统自动算频次
- 你也可以直接导入统计好的频次
- 设置字体
- 一般字体路径在C:\Windows\Fonts,你可以选自己喜欢的中文或者英文字体
- 切割中文字符
- 英文字符就不用切割了
- 输入WordCloud的参数
- 背景色
- 字号
- 生成的形状
- 颜色
- 字体大小
- 字体旋转等等
- 生成WordCloud
- 用matplotlib显示图片
效果图





安装库
老规矩,首先,你要安装库。
最基本的两个:
pip install wordcloud #这是WordCloud的库
pip install matplotlib #显示图像
- 1.
- 2.
- 3.
一个单词构造WordCloud
在这个代码中,我们需要安装一个numpy库
(大部分小伙伴应该都装过,就不用再装了)
pip install numpy
- 1.
这里用这个库,主要是想用数学坐标生成一个简单的背景图案,比如圆形、方形

基本步骤
- 输入单词
- 用numpy 生成一个形状,下面生成了一个圆形mask
- 输入WordCloud的参数(包括背景色、是否重复、图案形状)
- 用matplotlib显示图片
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = "square" #输入你要的单词
x, y = np.ogrid[:300, :300] #快速产生一对数组
# 产生一个以(150,150)为圆心,半径为130的圆形mask
mask = (x - 150) ** 2 + (y - 150) ** 2 > 130 ** 2 #此时mask是bool型
mask = 255 * mask.astype(int) #变量类型转换为int型
wc = WordCloud(
background_color="white", #背景颜色为“白色”
repeat=True, #单词可以重复
mask=mask #指定形状,就是刚刚生成的圆形
)
wc.generate(text) #从文本生成wordcloud
plt.axis("off") #把作图的坐标轴关掉
plt.imshow(wc, interpolation="bilinear")
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
生成WordCloud
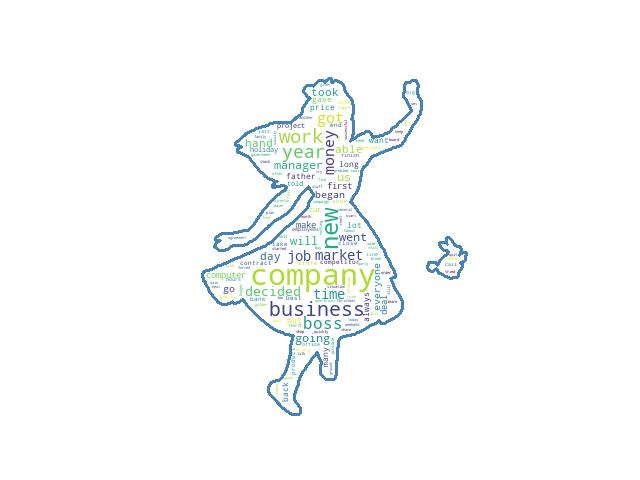
最简单的生成方式,文本内容都是英文,直接用系统默认的形状(一个长方形)
我这边是导入了一个商务英语的txt,所以可以看到,出现次数最多的单词是company,然后是business、new、work等单词,我还看到了money,哈哈~
基本步骤
- 获取内容txt的路径
- 输入WordCloud的参数(包括背景色、字号等)
- 生成WordCloud
- 用matplotlib显示图片
*WordCloud有很多参数,如果你不写,都是默认的。比如背景色默认黑色。
import os
from os import path
from wordcloud import WordCloud
from matplotlib import pyplot as plt
# 获取当前文件路径
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# 获取文本txt的路径(txt和代码在一个路径下面)
text = open(path.join(d,'BusinessEnglish.txt')).read()
# 生成词云
wc = WordCloud(
scale=2,
max_font_size=100, #最大字号
background_color='white' #设置背景颜色
)
wc.generate(text) # 从文本生成wordcloud
# wc.generate_from_text(text) #用这种表达方式也可以
# 显示图像
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.tight_layout()
wc.to_file('标签云效果图.png') # 储存图像
#plt.savefig('标签云效果图.png',dpi=200) #用这个可以指定像素
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
设置WordCloud形状
都是长方形、圆形、正方形这种,好像不够炫酷
为了炫酷,我们可以给它设置不同的形状,比如云朵、爱心等等
下面我们用Alice的小裙子做个实例
这个图片长这样

我们生成的图片是这样的,可以看到,完整保留了上图的轮廓

基本步骤
和之前基本都是一致的,就是多了一步,导入指定图片,获取图片轮廓
- 获取内容txt的路径
- 输入WordCloud的参数(包括背景色、字号等),指定了生成的形状
- 生成WordCloud
- 用matplotlib显示图片
*代码中增加了一个stopwords,有些你觉得没意义的单词,不想显示在图片上,你就可以放在这里
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import os
from wordcloud import WordCloud, STOPWORDS
# 获取当前文件路径
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# 获取文本txt的路径(txt和代码在一个路径下面)
text = open(path.join(d, 'BusinessEnglish.txt')).read()
# 读取mask的图像(图像和代码在一个路径下面)
alice_mask = np.array(Image.open(path.join(d, "alice_mask.png")))
# 设置不显示单词,比如said、in、on、is这种单词
stopwords = set(STOPWORDS)
stopwords.add("said")
# 设置词云参数
wc = WordCloud(background_color="white",
max_words=2000,
mask=alice_mask,
stopwords=stopwords,
contour_width=3, #设置轮廓宽度
contour_color='steelblue') #设置轮廓颜色
# 从文本生成wordcloud
wc.generate(text)
# 保存到文件
wc.to_file(path.join(d, "alice.png"))
# 显示图片
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.figure() #新建一个图片,把mask也显示出来
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
根据图片调整颜色
原图是这样的

如果我们直接根据上一步,获取图片轮廓,可以得到下图

我们进一步,根据原图,调整颜色

其实就是获取了图片颜色,也是一行代码
image_colors = ImageColorGenerator(alice_coloring)
- 1.
完整代码
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import os
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 获取当前文件路径
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# 获取文本txt的路径(txt和代码在一个路径下面)
text = open(path.join(d, 'BusinessEnglish.txt')).read()
# 读取我要的图片文件
alice_coloring = np.array(Image.open(path.join(d, "alice_color.png")))
# 设置不显示的单词
stopwords = set(STOPWORDS)
stopwords.add("said")
# 设置词云参数
wc = WordCloud(background_color="white",
max_words=2000,
mask=alice_coloring,
stopwords=stopwords,
max_font_size=40,
random_state=42)
# 从文本生成wordcloud
wc.generate(text)
# 根据图片,创建颜色
image_colors = ImageColorGenerator(alice_coloring)
# 把图片分成3份
fig, axes = plt.subplots(1, 3)
axes[0].imshow(wc, interpolation="bilinear")
# recolor wordcloud and show
# we could also give color_func=image_colors directly in the constructor
axes[1].imshow(wc.recolor(color_func=image_colors), interpolation="bilinear")
axes[2].imshow(alice_coloring, cmap=plt.cm.gray, interpolation="bilinear")
for ax in axes:
ax.set_axis_off()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
# 单独显示图片
# plt.figure()
# plt.imshow(wc, interpolation="bilinear")
# plt.axis("off")
# plt.figure()
# plt.imshow(wc.recolor(color_func=image_colors), interpolation="bilinear")
# plt.axis("off")
# plt.figure()
# plt.imshow(alice_coloring, cmap=plt.cm.gray, interpolation="bilinear")
# plt.axis("off")
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
用频率绘制WordCloud
上面是直接把一个txt输进去,系统自动给你算出现次数的
但是实际过程中,我们有时候,是知道单词出现次数的,我们就想根据已知的次数显示
这一步,其实就改了一行代码,
原来是这样的
wc.generate(text) # 这里的text是一段文字
- 1.
现在是这样的
wc.generate_from_frequencies(text)
# 这里的text是一个字典
# 'ken': 1, 'was': 47, 'hot': 2, 'water': 2
- 1.
- 2.
- 3.
- 4.
- 5.
如果你已经有一个字典,直接代进去就好了
这里给大家详细看一下,如果假设我没有这个字典
我还是一段文字,我想先生成这个字典,再代入进去
这里,你需要安装一个库multidict,创建一键多值字典
pip install multidict
- 1.
用multidict这个库,我可以把文本变成一个字典
通过上图就可以看到,这个字典有1105个组合,每一个单词,都统计了出现次数
import multidict as multidict
import numpy as np
import os
import re
from PIL import Image
from os import path
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def getFrequencyDictForText(sentence):
fullTermsDict = multidict.MultiDict()
tmpDict = {}
# making dict for counting frequencies
for text in sentence.split(" "):
if re.match("a|the|an|the|to|in|for|of|or|by|with|is|on|that|be", text):
continue
val = tmpDict.get(text, 0)
tmpDict[text.lower()] = val + 1
for key in tmpDict:
fullTermsDict.add(key, tmpDict[key])
return fullTermsDict
def makeImage(text):
alice_mask = np.array(Image.open("alice_mask.png"))
wc = WordCloud(
background_color="white",
max_words=1000,
mask=alice_mask
)
# generate word cloud
wc.generate_from_frequencies(text)
# show
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
wc.to_file('frequency.png') # 储存图像
plt.show()
# 获取当前文件路径
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# 获取文本txt的路径(txt和代码在一个路径下面)
text = open(path.join(d, 'BusinessEnglish.txt'), encoding='utf-8')
text = text.read()
makeImage(getFrequencyDictForText(text))
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
生成中英文WordCloud
生成一个中英文混搭的WordCloud
如果你的txt全是中文,那就是全中文的
基本步骤
和之前基本也都一样,就是中文字符,需要增加一个中文词语切割
这就需要添加一个库
pip install jieba # 中文切割
- 1.
- 获取内容txt的路径
- 设置字体
- 切割中文字符
- 输入WordCloud的参数(包括背景色、字号等),指定了生成的形状
- 生成WordCloud
- 用matplotlib显示图片
import os
from os import path
from wordcloud import WordCloud
from matplotlib import pyplot as plt
import jieba
# 获取当前文件路径
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# 获取文本txt
text = open(path.join(d,'商务英语.txt'),encoding='utf-8').read()
# 设置中文字体
font_path = 'C:\Windows\Fonts\\simfang.ttf' # 字体路径
# 精确切割中文字符
text = ' '.join(jieba.cut(text, cut_all = False))
# 生成词云
wc = WordCloud(
font_path = font_path, #字体路径
scale=2,
max_words = 100, #最多词个数
max_font_size=100, #最大字号
background_color='white' #背景色
)
wc.generate(text)
# 显示图像
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.tight_layout()
# 储存图像
#wc.to_file('标签云效果图.png')
#plt.savefig('标签云效果图.png',dpi=200)
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.