












本人负责的项目主要采用阿里云数据库 MySQL,最近频繁出现慢 SQL 告警,执行时间最长的竟然高达 5 分钟。
导出日志后分析,主要原因竟然是没有命中索引和没有分页处理。其实这是非常低级的错误,我不禁后背一凉,团队成员的技术水平亟待提高啊。
改造这些 SQL 的过程中,总结了一些经验分享给大家,如果有错误欢迎批评指正。
MySQL 性能
①最大数据量
抛开数据量和并发数,谈性能都是耍流氓。MySQL 没有限制单表最大记录数,它取决于操作系统对文件大小的限制。
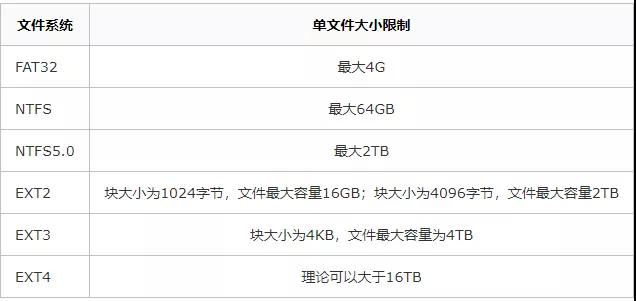
《阿里巴巴 Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB,才推荐分库分表。
性能由综合因素决定,抛开业务复杂度,影响程度依次是硬件配置、MySQL 配置、数据表设计、索引优化。500 万这个值仅供参考,并非铁律。
我曾经操作过超过 4 亿行数据的单表,分页查询最新的 20 条记录耗时 0.6 秒,SQL 语句大致是:
- select field_1,field_2 from table where id < #{prePageMinId} order by id desc limit 20
prePageMinId 是上一页数据记录的最小 ID。虽然当时查询速度还凑合,随着数据不断增长,有朝一日必定不堪重负。
分库分表是个周期长而风险高的大活儿,应该尽可能在当前结构上优化,比如升级硬件、迁移历史数据等等,实在没辙了再分。对分库分表感兴趣的同学可以阅读分库分表的基本思想。
②最大并发数
并发数是指同一时刻数据库能处理多少个请求,由 max_connections 和 max_user_connections 决定。
max_connections 是指 MySQL 实例的最大连接数,上限值是 16384,max_user_connections 是指每个数据库用户的最大连接数。
MySQL 会为每个连接提供缓冲区,意味着消耗更多的内存。如果连接数设置太高硬件吃不消,太低又不能充分利用硬件。
一般要求两者比值超过 10%,计算方法如下:
- max_used_connections / max_connections * 100% = 3/100 *100% ≈ 3%
查看最大连接数与响应最大连接数:
- show variables like '%max_connections%';
- show variables like '%max_user_connections%';
在配置文件 my.cnf 中修改最大连接数:
- [mysqld]
- max_connections = 100
- max_used_connections = 20
③查询耗时 0.5 秒
建议将单次查询耗时控制在 0.5 秒以内,0.5 秒是个经验值,源于用户体验的 3 秒原则。如果用户的操作 3 秒内没有响应,将会厌烦甚至退出。
响应时间=客户端 UI 渲染耗时+网络请求耗时+应用程序处理耗时+查询数据库耗时,0.5 秒就是留给数据库 1/6 的处理时间。
④实施原则
相比 NoSQL 数据库,MySQL 是个娇气脆弱的家伙。它就像体育课上的女同学,一点纠纷就和同学闹别扭(扩容难),跑两步就气喘吁吁(容量小并发低),常常身体不适要请假(SQL 约束太多)。
如今大家都会搞点分布式,应用程序扩容比数据库要容易得多,所以实施原则是数据库少干活,应用程序多干活:
- 充分利用但不滥用索引,须知索引也消耗磁盘和 CPU。
- 不推荐使用数据库函数格式化数据,交给应用程序处理。
- 不推荐使用外键约束,用应用程序保证数据准确性。
- 写多读少的场景,不推荐使用唯一索引,用应用程序保证唯一性。
- 适当冗余字段,尝试创建中间表,用应用程序计算中间结果,用空间换时间。
- 不允许执行极度耗时的事务,配合应用程序拆分成更小的事务。
- 预估重要数据表(比如订单表)的负载和数据增长态势,提前优化。
数据表设计
①数据类型
数据类型的选择原则,更简单或者占用空间更小:
- 如果长度能够满足,整型尽量使用 tinyint、smallint、medium_int 而非 int。
- 如果字符串长度确定,采用 char 类型。
- 如果 varchar 能够满足,不采用 text 类型。
- 精度要求较高的使用 decimal 类型,也可以使用 BIGINT,比如精确两位小数就乘以 100 后保存。
- 尽量采用 timestamp 而非 datetime。

相比 datetime,timestamp 占用更少的空间,以 UTC 的格式储存自动转换时区。
②避免空值
MySQL 中字段为 NULL 时依然占用空间,会使索引、索引统计更加复杂。从 NULL 值更新到非 NULL 无法做到原地更新,容易发生索引分裂影响性能。
因此尽可能将 NULL 值用有意义的值代替,也能避免 SQL 语句里面包含 is not null 的判断。
③Text 类型优化
由于 Text 字段储存大量数据,表容量会很早涨上去,影响其他字段的查询性能。建议抽取出来放在子表里,用业务主键关联。
索引优化
索引分类如下:
- 普通索引:最基本的索引。
- 组合索引:多个字段上建立的索引,能够加速复合查询条件的检索。
- 唯一索引:与普通索引类似,但索引列的值必须唯一,允许有空值。
- 组合唯一索引:列值的组合必须唯一。
- 主键索引:特殊的唯一索引,用于唯一标识数据表中的某一条记录,不允许有空值,一般用 primary key 约束。
- 全文索引:用于海量文本的查询,MySQL 5.6 之后的 InnoDB 和 MyISAM 均支持全文索引。由于查询精度以及扩展性不佳,更多的企业选择 Elasticsearch。
索引优化原则:
- 分页查询很重要,如果查询数据量超过 30%,MySQL 不会使用索引。
- 单表索引数不超过 5 个、单个索引字段数不超过 5 个。
- 字符串可使用前缀索引,前缀长度控制在 5-8 个字符。
- 字段唯一性太低,增加索引没有意义,如:是否删除、性别。
- 合理使用覆盖索引,如下所示:
- select login_name, nick_name from member where login_name = ?
login_name, nick_name 两个字段建立组合索引,比 login_name 简单索引要更快。
SQL 优化
①分批处理
博主小时候看到鱼塘挖开小口子放水,水面有各种漂浮物。浮萍和树叶总能顺利通过出水口,而树枝会挡住其他物体通过,有时还会卡住,需要人工清理。
MySQL 就是鱼塘,最大并发数和网络带宽就是出水口,用户 SQL 就是漂浮物。
不带分页参数的查询或者影响大量数据的 update 和 delete 操作,都是树枝,我们要把它打散分批处理,下面举例说明。
业务描述:更新用户所有已过期的优惠券为不可用状态。
SQL 语句:
- update status=0 FROM `coupon` WHERE expire_date <= #{currentDate} and status=1;
如果大量优惠券需要更新为不可用状态,执行这条 SQL 可能会堵死其他 SQL,分批处理伪代码如下:
- int pageNo = 1;
- int PAGE_SIZE = 100;
- while(true) {
- List<Integer> batchIdList = queryList('select id FROM `coupon` WHERE expire_date <= #{currentDate} and status = 1 limit #{(pageNo-1) * PAGE_SIZE},#{PAGE_SIZE}');
- if (CollectionUtils.isEmpty(batchIdList)) {
- return;
- }
- update('update status = 0 FROM `coupon` where status = 1 and id in #{batchIdList}')
- pageNo ++;
- }
②操作符 <> 优化
通常 <> 操作符无法使用索引,举例如下,查询金额不为 100 元的订单:
- select id from orders where amount != 100;
如果金额为 100 的订单极少,这种数据分布严重不均的情况下,有可能使用索引。
鉴于这种不确定性,采用 union 聚合搜索结果,改写方法如下:
- (select id from orders where amount > 100)
- union all
- (select id from orders where amount < 100 and amount > 0)
③OR 优化
在 Innodb 引擎下 OR 无法使用组合索引,比如:
- select id,product_name from orders where mobile_no = '13421800407' or user_id = 100;
OR 无法命中 mobile_no + user_id 的组合索引,可采用 union,如下所示:
- (select id,product_name from orders where mobile_no = '13421800407')
- union
- (select id,product_name from orders where user_id = 100);
此时 id 和 product_name 字段都有索引,查询才最高效。
④IN 优化
IN 适合主表大子表小,EXIST 适合主表小子表大。由于查询优化器的不断升级,很多场景这两者性能差不多一样了。
尝试改为 Join 查询,举例如下:
- select id from orders where user_id in (select id from user where level = 'VIP');
采用 Join 如下所示:
- select o.id from orders o left join user u on o.user_id = u.id where u.level = 'VIP';
⑤不做列运算
通常在查询条件列运算会导致索引失效,如下所示,查询当日订单:
- select id from order where date_format(create_time,'%Y-%m-%d') = '2019-07-01';
date_format 函数会导致这个查询无法使用索引,改写后:
- select id from order where create_time between '2019-07-01 00:00:00' and '2019-07-01 23:59:59';
⑥避免Select All
如果不查询表中所有的列,避免使用 SELECT *,它会进行全表扫描,不能有效利用索引。
⑦Like 优化
Like 用于模糊查询,举个例子(field 已建立索引):
- SELECT column FROM table WHERE field like '%keyword%';
这个查询未命中索引,换成下面的写法:
- SELECT column FROM table WHERE field like 'keyword%';
去除了前面的 % 查询将会命中索引,但是产品经理一定要前后模糊匹配呢?全文索引 fulltext 可以尝试一下,但 Elasticsearch 才是终极武器。
⑧Join 优化
Join 的实现是采用 Nested Loop Join 算法,就是通过驱动表的结果集作为基础数据,通过该结数据作为过滤条件到下一个表中循环查询数据,然后合并结果。
如果有多个 Join,则将前面的结果集作为循环数据,再次到后一个表中查询数据。
驱动表和被驱动表尽可能增加查询条件,满足 ON 的条件而少用 Where,用小结果集驱动大结果集。
被驱动表的 Join 字段上加上索引,无法建立索引的时候,设置足够的 Join Buffer Size。
禁止 Join 连接三个以上的表,尝试增加冗余字段。
⑨Limit 优化
Limit 用于分页查询时越往后翻性能越差,解决的原则:缩小扫描范围,如下所示:
- select * from orders order by id desc limit 100000,10
- 耗时0.4秒
- select * from orders order by id desc limit 1000000,10
- 耗时5.2秒
先筛选出 ID 缩小查询范围,写法如下:
- select * from orders where id > (select id from orders order by id desc limit 1000000, 1) order by id desc limit 0,10
- 耗时0.5秒
如果查询条件仅有主键 ID,写法如下:
- select id from orders where id between 1000000 and 1000010 order by id desc
- 耗时0.3秒
如果以上方案依然很慢呢?只好用游标了,感兴趣的朋友阅读 JDBC 使用游标实现分页查询的方法。
其他数据库
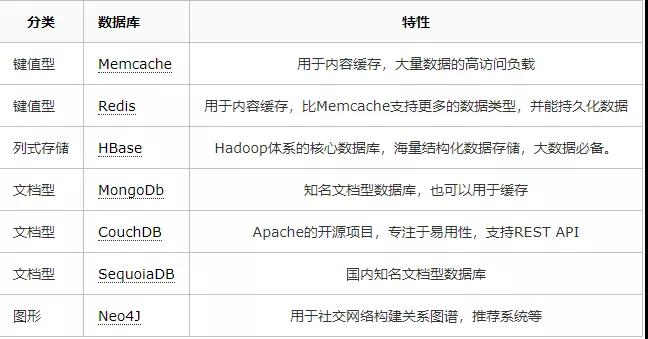
作为一名后端开发人员,务必精通作为存储核心的 MySQL 或 SQL Server,也要积极关注 NoSQL 数据库,他们已经足够成熟并被广泛采用,能解决特定场景下的性能瓶颈。
作者:编码砖家
编辑:陶家龙
出处:www.cnblogs.com/xiaoyangjia/p/11267191.html




















