













备注:本文根据演讲者视频语音速记整理而成,如有图文不妥,请以视频为准。
很高兴能有机会跟大家一起来交流一下 CMDB 的建设。屏幕前的各位应该都是运维的伙伴,那么大家对于 CMDB 应该都很有了解,我相信有10个人里面有9个人对 CMDB 的理解是不同的,在平日里跟其他同事、同仁交流时,我们都会说 CMDB 可能就是应用关系的一个记录,一个应用关系的库;还有就是CMDB ,Configuration Management 就是一个配置管理,那配置到底包含什么关系?是不是需要包含一个全链路的东西,比如层应用,应用、数据库、交换机是不是一个配置?还有物理机、虚拟机等我们是不是把它录进来。
也有朋友可能会很诧异,现在都已经上云了,云上有这么多的资源管理控制台,可以在生产虚拟机为这个instant去打标签,在我们需要用到它的时候,可以通过标签来搜索和定位应用在哪个服务器上,这些我相信大家说的都是正确的,但随着业务规模越来越大,CMDB的维度也是越来越多。CMDB可以是一个简单二维的统计表,也可以是一个多维立体覆盖的模型,如果一开始没有一个好的规划,那做到后面 CMDB 是承受不了这样的复杂性的。
不知道大家有没有这样的感觉,CMDB 刚开始的时候建的非常的顺利,不管是从云上,我们把数据拉回来存在本地,还是我们自己拿一些 agent 去采一些虚拟机的数据。但随着业务规模的不断增加,随着不断把一些模型,比如说把一些关系加到 CMDB 里面去,到了这时会发现,我们的模型非常的复杂,而且根本就没有办法维护,这时 CMDB 就变成了一个垃圾场。
今天要跟大家分享的是如何快速的打造一个能够持久使用的 CMDB。相信听过今天的三部曲之后,大家会有一个新的认识。
首先我们还是回到概念上来,CMDB 是什么,为什么一定要建 CMDB?大家都知道工具是为了解决同一个反复的问题或反复的场景减少重复劳动提高生产效率的产物,那么 CMDB 也是这样。
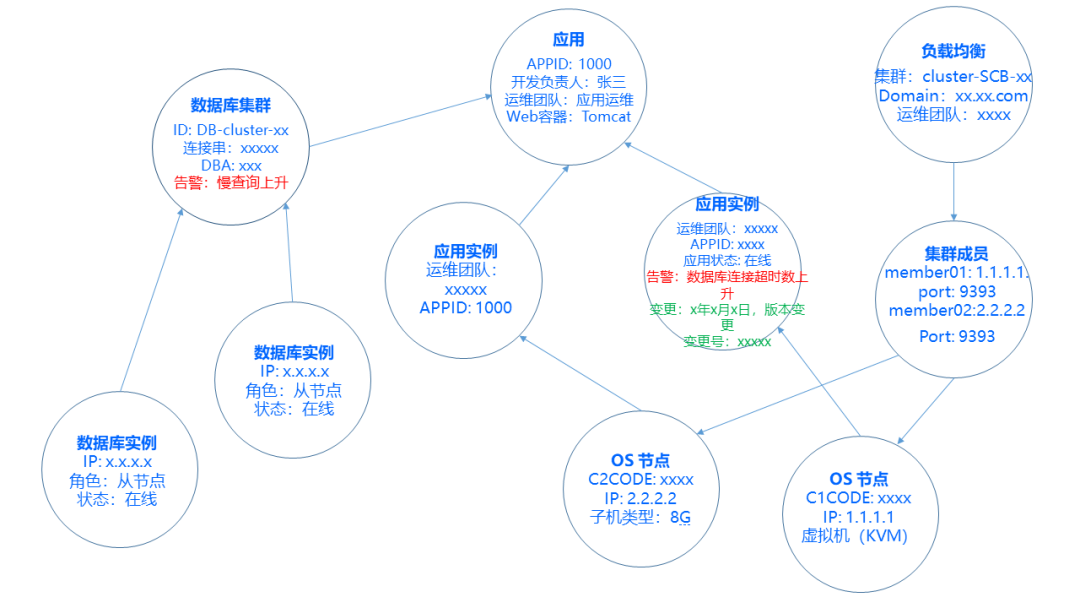
我们来看一张图,这张图是我们现在的排障图,因为银行有一些规定,没办法直接把行内的截图发出来,所以跟大家手绘一张。
首先从左上角开始,左上角是负载均衡的集群,这也是一个模型,这个负载均衡里面有写集群的ID、域名以及运维团队相关负责人,负载均衡下面是集群Member,这里面是集群成员,有端口号、IP,这个 Member 会指到两个OS节点上,两个OS就是系统节点,这个节点的数据就记录着系统IP地址,虚拟化的版本等系统级别的信息。
系统信息级别的上层是应用实例,应用实例会有应用APPID,我们每一个应用都会有独立的ID,这个ID代表了这个应用的画像,这个ID是什么容器,是什么外部容器,它的语言、发布版本周期、发布变更窗口等等都是围绕应用的。
这一层就是我们的应用了,应用的上面,在这个地方就是APPID的模型,针对应用产生两个实例,它们带有独立的IP属性,这个应用就是我们的应用画像。
接着这个应用右边是数据库集群,在CMDB里面我们作为一个服务对象承载,应用使用服务,这是我们数据库服务。数据库服务里面会有集群的ID,数据库的类型,数据库的库名以及维护的团队DBA,这个集群下挂了两个数据库实例,这两个实例它们的区别是在于有一主一从,如果是MySQL的话,那么它们角色就是主从关系。
在这样的排障图情况下,假设今天有一个报警,红色的地方报了数据库集群,报了一个警,说这个数据库集群有一个慢查询,然后数据库实例在组节点上面发现了DB的Session异常升高了,与此同时在我们OS的节点上,我们发现主机的 TIME_WAIT 数有增加,那在我们应用实例里面,我们现在通过CAT埋点,我们可以拿到在代码执行过程当中互相调用链的SLA的响应时长,对对方的SLA,在这个地方有一个报警,到现在有调用数据库TIMEOUT,这是一个告警,告警最底层蓝色的字体是CMDB源数据,我们把告警覆盖上去,今天出来的告警覆盖到这张图上面,然后我们与此同时把变更的记录覆上去,变更记录是绿色的这边,我给大家读一下,变更信息:某年某月某日某个版本发生了变更,变更号。
如果排障的时候如果把这张图放在外面的话,我们其实是很容易能判定出哪个应用受到了什么影响,并且影响范围是什么,可能是因为有什么变更导致的。这个就是CMDB典型的场景。CMDB的数据远远不止这些,可以通过学习,通过分析,所有的数据都是覆盖在CMDB之上的,所以CMDB源数据是一个非常重要的基础数据,那如果说我们今天没有CMDB,这些东西全部都在脑子里面,我知道某一个应用它下面有几台机器,然后这个机器前面挂了一个F5,我知道它连着数据库是什么,那如果说你所知道的这个东西扩展到一千倍,你还会记得吗?可能你的当时脑子里是这个样子的。
一、建模阶段
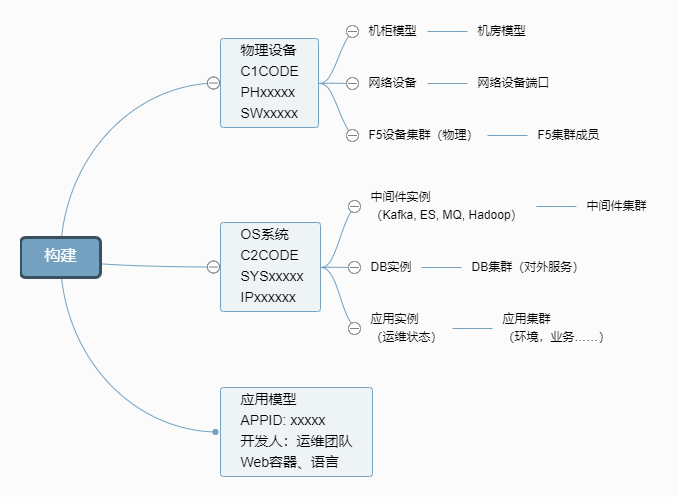
我相信刚刚这张图已经足以让大家知道我们的 CMDB 有多大的用途。接下来我来告诉大家说一下CMDB的建设,CMDB的建设分三个阶段,第一个阶段是建模阶段,我们来看一下这个模型,首先我们要确定一下,这个模型相对来说是一个比较简单的模型,这个有物理设备、OS、应用模型,各自这边会有物理模型、机柜、机房还有物理设备,网络接口、网络设备到物理设备,还有我们F5的集群,集群成员,物理的集群,到网络设备。
我们刚刚看到这些集群里面,其实并不是所有的信息我们CMDB都会需要,哪些CMDB我们需要,首先第一个我们平时用得到,我们排障用得到的管理信息、状态信息这部分是不可少,今天有一个报警必须找到,对不对?刚才说到管理信息,状态信息这个东西也是不可少,因为CMDB本身就是管理配置的生命周期,你所有的主机节点是不是上线、在维护中、带部署了、在使用中,这些都需要有,是一个虚拟机的生命周期。不单单是虚拟机需要生命周期,包括我们的实例,包括我们的 DB,都可能拉入、拉出、维护或者是带部署等等状态,那这些状态信息用来干什么?是用来告警抑制的时候或者是自动上架,然后还没有对外提供服务能力的时候,我们可以把这些告警给抑制掉,包括你今天正常计划的拉入、拉出,这些原本是不需要发出告警的,所以我们要可以通过状态的变化来把告警浸没。
然后第二个就是我们是按照一个领域来划分,我们在看一下这张图,其实每一条线都是一个领域,所谓的领域就是相对来说,因为这个领域跟我们组织架构有点关系,比如说设备组,它负责的领域就是机房机柜、物理设备;
网络组负责网络交换机、防火墙、代理、VPN等等网络设备,所以它的领域网络设备和网络设备的端口,我们ADC的团队主要负责F5的,那么F5的领域包括物理集群、逻辑集群、member,这些都关联到物理设备上。
下面是系统节点,系统节点也出现很多领域,比如说中间件的,Hadoop、ES、Kafka,主要是一些指Member等等这些,还有我们DB,DB实例、DB的集群、DB的实体,
最下面是我们的应用,应用运维,有负责应用领域,也有应用实例、应用集群、应用画像。
大家有没有看到数据模型领域很多,但是彼此领域之间是没有交际的,有没有看到?领域和领域之间不会建立模型不会建立关系,它们的关系永远都是对应到一个相对集中点,物理设备的,设备组所有领域信息都是归结到物理设备上,网络归结到物理设备上,F5也是归结到物理设备。
有人问F5的集群里面的Member是主机又不是物理设备,像主机节点我们全部关联到节点OS上,尽量我们把领域跟领域之间不作为互相交互,他们只关联具体的三个大的模型上,这个有一个什么好处?我们在刚开始的时候建数据的时候,可能数据量不是很多,服务器数量不是很多,那如果我上报一个虚拟机,我还要把应用关系,还要把F5关系全部报给你可以吗?可以,但是时间长了,闭环会越来越重,就是越来越吃闭环,如果今天哪个流程出现问题的时候,你的数据就乱了,你根本没有办法去治理它,所以保证上传的数据只是在这个领域内部去做三层的结构。
怎么理解内部做三层结构?我们举个例子,我们拿网络来举例,网络的是有一个网络设备端口,网络的设备端口一定是属于某一个网络设备的,那这个网络设备和这个网络设备端口是一个1比多对应的集群关系,网络只需要维护好自己的这一份数据,确保集群每个端口都会对应一个集群,一个集群下就一定会有48个口,交换机48个口,它只要把这层数据关系关联好,把网络设备关联到我们某一个物理设备上,因为这当中是有CI号,每个设备都会有CI号,这是唯一的,所以一定不会关联错,这个时候全都上报到CMDB,那CMDB接下来就可以做很多关系,只要有这一份关系,就可以透过这层关系帮你建出你的拓扑。
就是我们刚刚看到这张图,这张图片所有的数据关系都是CMDB建出来的,所以在采集数据的时候,它们彼此之间其实是不知道关系的,明白吗?只有自己的领域之间集群和Member这个之间是自己有关系,但是它不知道对应的应用是什么,F5不知道应用是谁?刚不会知道下面数据库关系是什么。
这个就是我们说的建模,为了要增大你数据灵活性和拓展性,所以我们必须要把模型变得更简单,关系变得更简单,把复杂的逻辑,复杂的数据关系带到CMDB,这是一个大忌。
二、闭环
第二阶段我们建完模之后要先做闭环,我们的闭环数据是非常重要,在CMDB里面没有闭环这个数据就是不可信的,闭环是保证数据准确性的基础,闭环的方式可以通过强留层驱动,可以通过服务目录或者流程引擎。
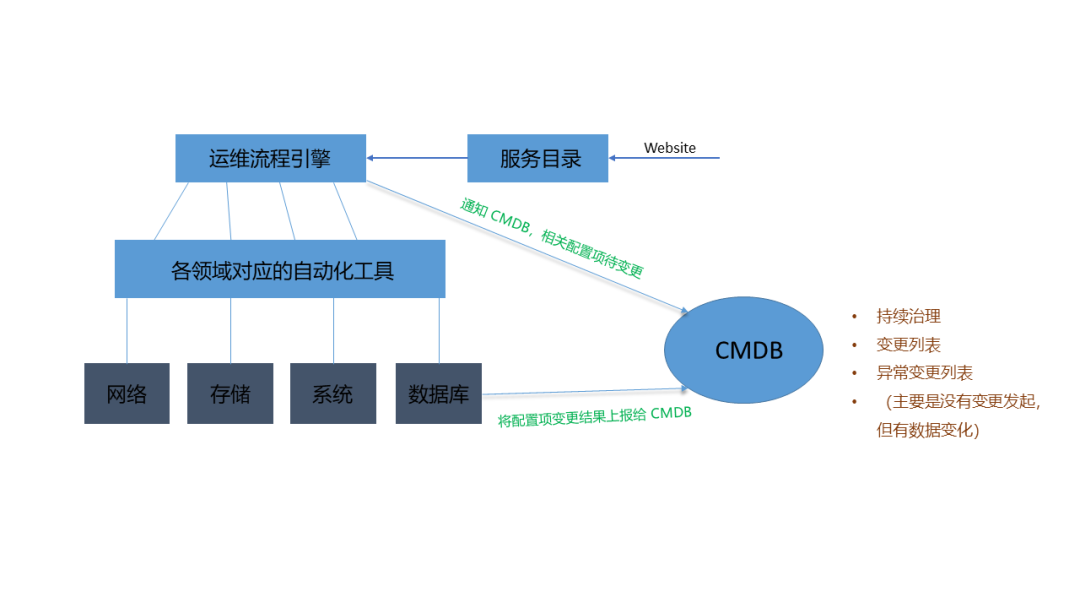
那我们这边简单说一下流程引擎的思想,一个用户在访问我们服务目录的时候,会去访问运维的流程引擎,那之后运维流程引擎下发所有任务让自动化工具系统去执行,执行完了之后这些工具系统会告诉自己的领域,因为这些工具都是领域内部的自动化工具,自己的领域都会收到相关的一些信息,比如说今天要做一个扩容,虚拟机扩容从2扩变成4扩,那这个流程下去之后就会下发到系统的领域,系统的领域知道我现在某一个虚拟机变成4扩,它记录数据并且上报,将增量的部分上报给CMDB,告诉CMDB现在我有一台虚拟机,从2扩变成了4扩了,那么CMDB收到这部分数据的时候,它能不能信?
CMDB 不能随便的去更改我们库里面的源数据,必须要有强流程的驱动,所以在流程引擎在执行的时候,会放给CMDB一条信息,告诉CMDB说接下来会有一个什么机器的,它的2扩要变成4扩,这个是通常我们说到CMDB B表,那领域上报就是一个C表,B表跟C表一参照,匹配上就是一个正常变更,我允许你变更数据,如果没有匹配上,它上报的这条数据将会列入到异常上报数据,这个时候我们可以反过来去推行,说为什么今天2扩会变成4扩,是因为没有任何的变更驱动来做这个事情了,这样就形成了一个闭环。
我们先把这种闭环建立起来再去录入CMDB数据,今天也许有些伙伴说,我今天只是想搜集一下服务器的数据,在云上可能我的拿一个API就把全量的数据拿过来,但是我们有没有想过你今天拿全量的数据拿过来,接下来你在产一台机器的时候,你的数据怎样进来?可能你需要定期不断去拿API,不断拿全量的数据,永远去覆盖掉你的CMDB完整数据,那我觉得CMDB不应该这样做,它应该去保留说你的所有变更记录,CMDB里面的数据每一条变更记录都是需要被保留审计的。
所以今天在云上面创立主机的时候,你要先想要你今天在创建这个主机的时候,怎么样让CMDB先知道这条信息,然后你在通过API的方式去拿到这台消息上报的时候,那CMDB会对你已经告诉它要更改的数据做一个修改,这个就是闭环。
闭环没有建立起来,所有的数据都是不可信的,这是我们第二阶段的闭环。
三、解决存量
第三阶段是解决我们的存量,存量让我们要改变一些思维的方式,首先,我们要相信领域,我们刚刚说这些搜集的数据,今天我们说按照组织架构,有网络组,网络组可以提供权威的领域数据,如果今天团队规模比较小,没有,那也没有关系,我们就把它单独看作是一个领域上报,这里有一个思维要转变一下,我们尽量不要CMDB去下探,去拿它的东西,而是作为一个上报的过程,有什么好处?
第一个,你今天下探去拿东西的时候,你未必拿的全,第二个你的拿回来的东西,如果是CMDB去拿,你可能直接就进库了,如果是上报的方式,你把一个网络领域单独独立出来,你可以对它整个生命周期做管理,因为你第一次拿和第二次拿都在你网络领域里面已经感知到了,它不会撞了CMDB的数据,哪些东西需要上报到CMDB,是哪些有变化有增量的东西会上报到CMDB里面去,所以这样的话CMDB就可以做到有一个更简单、可追溯、可校验的过程。所有的CMDB变更记录一定要把它给记录起来,每一条记录的变更,谁来变更这些都是一个之后可回溯的关键方法。
那么解决存量我们还有一个问题要解决,我的分布是什么,我怎么知道你这个领域里面应该有多少个机器,因为领域上报过来,你作为一个CMDB你接受领域上报的所有数据,你相信它是权威,我相信你的数据,但是我也要帮你做一个交叉比较,那怎么做交叉比较其实很简单,我们可以放一台机器,拿一个主机来说,可以在某一个网段放一个机器,去全网扫,整个C端里面去扫所有的端口,去通过端口的特征来判断它是一个什么样的主机,是一个什么样的设备,这是一种方式,还有一种方式我们自建IDC的,我们可以拿到整个交换机 ARP 表,我们银行现在主要是做TOP的架构,柜顶一个,一行柜,然后会有一个汇聚,多个汇聚形成一个核心,所以我们在每个柜顶上都可以找到ARP表,有了这些ARP表我就知道现在整个生产环境的分布有多大,这是一种探测的方法,不能单单靠我们领域上报过来的数据,我们还需要有自己帮助领域去加强去准确它上报数据的覆盖度。
那么接下来我们要说一个逻辑的交叉比对,是怎么样子的?比如说我们今天上报物理机的过程当中,现在有5台物理机,这5台物理机都是属于EXS的系统,那么我要保证这5台EXS的系统都能被我们虚拟机关联上,我们云团队会把所有虚拟机报上来,那所有的虚拟机是不是都落在这5台上,如果都落在这5台上没有问题,如果没有落上,我们看一看有某些物理机没有被关联上是因为它没有在使用中还是它漏报了,这是一种交叉比对的方式,不管是ARP表的比对还是交叉比对,乃至于今天到生产上找一台机器,去用 TCPdump 找出上下游的关系,这也是一种方法。
可以找到在生产上所有活跃的IP,这些IP是不是所有活跃在CMDB当中都被落到某一个对象里面去,这样的方式就可以持续去做,需要有一个报表的体系去推动数据的治理,因为我们都知道 CMDB 这个东西数据准确率是非常重要的一项,如果今天的数据准确率不按照这个报表体系,每天每周去跟进去处理的话,当然你后面还要去建立一些像SLA处理及时率这些东西,来考核每个领域数据的准确性,只有这样我们的CMDB才能够持续稳健成长。
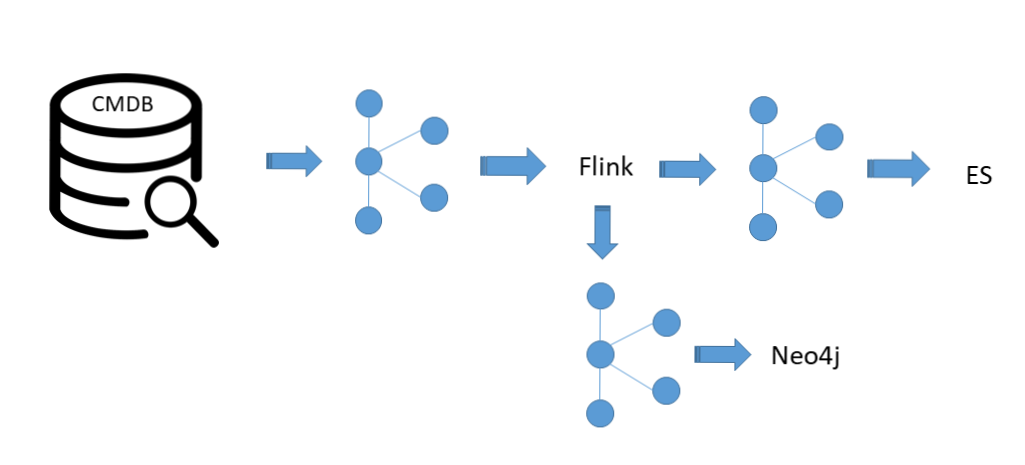
那接下来我们要说在我们完成三阶段,我们把CMDB建设起来了,但是我们最重要的环节就是刚刚说到,我们把CMDB的数据弄进来之后,只能解决这个每一层的关系,现在还不具备通过一个机柜能够知道DB相关信息,整天链都不知道。
那么接下来就是另外一个,当我们完成 CMDB 构建的时候,接下来要做关系了,如何构建一个复杂的关系实现一个快速的检索,我们看一下这套架构图,这个是我么CMDB,我们的源数据在这里,所有变更事件会推到 Kafka 队列,所有变更事件,比如说今天进来一条数据,这条数据产生变化,会把这些变化推到Kafka,Flink 会经过一段流程处理,然后加工,可以不加工,加工是业务需求,然后在这个当成主要做一些格式,为了更好去检索使用,然后就推到ES去了。
上面这条路能实现什么,上面这条路能够实现快速模糊查询,我们可以输入一个IP,可以输入一个APPID,可以输入一个CICODE,乃至于我今天输入一个联系人,我都可以去找到所有相关的信息,它虽然说还无法完成这个图,但是至少可以有类似于百度的一些信息,你百度一个模糊查询,我搜索一个人名,我是不是可以搜索到相关的管理员是他所有的模型记录,在ES里面这个不难做到。
现在 CMDB 的模型大概是在30个左右,导到ES里面也是30张独立的表,大概的字段是在700接近800个,全面索引,目前这个数据量在二三十万条记录这样子,压力也没有压力,ES集群也是用的虚拟机做的,也没有什么特别厉害,因为ES就擅长做这件事情。
要实现这张图,我们还需要借助于优秀的东西叫做NEO4J,NEO4J 这个数据库最近也是炒得比较火,我们从 Flink 拿一条数据进入到NEO4J,原生的进去,之前是什么关系我还是什么关系进去,不加任何关联关系,直接把这层的关系直接导入到 NEO4J 通过数据库去变例出来,去能实现这样的一张条,这样蓝色部分所有都是NEO4J可以搞定的事情,然后接下来我在把变更记录往NEO4J里面导,把告警记录往NEO4J里面导,所做出来就是一层一层带着告警带着源数据,带着变更日志的信息了。
NEO4J 它的处理能力是比较高,处理十多个亿这样的关系节点也是非常的高效,我们的使用来说还是比较小的,也就几十万节点而已,大概在30万关系左右进入NEO4J。
总结
因为时间有限,没办法每个地方都展开精细的说明,再回顾一下今天的内容,CMDB首先要有三个阶段,第一个阶段要建模,建的模型一定要够简单,它的关系只关联到 OS就够了,领域跟领域之间不要做额外的关联,关联 NEO4J 会帮我们轻松的搞定。
第二,要解决闭环的问题,因为闭环是 CMDB 的基础,必须先要有闭环然后才能得到增量,负责天天全量不行。
第三,是解决存量的问题,解决存量问题的时候,我们要记得一定要交叉比对,要对上报的数据持有怀疑,虽然说它是领域是权威数据,但是 CMDB 一定要对上报数据有怀疑,去发现,去想办法去探测等等手段去帮助领域上报的数据做到更全、更准。
有了这三步之后我们要持续做报表,将有问题的数据及时的抛出来,因为时间长了之后对数据的治理难度很高,比如你今天做了一个变更,这个变更可能没有及时更新上 CMDB,CMDB 第二天发现了,如果不报出来,过了三五天之后,这个数据的这条变更没有人记得,也许它就在我们记录变更表当中,但是很难去找到它,大家可能想不到,所以要及时去处理,想尽一切办法去推动这个数据的整改和治理,CMDB建完之后可以通过ES来做检索,可以通过NEO4J来做拓扑,当中只需要 Kafka 把变更的数据持续往ES里面更新,CMDB进ES的数据,可以原封不动,一张模型一张表这样导进去,进NEO4J的时候可以把 CMDB 的数据一个一个,原来的模型是怎样就导进去,不需要增加新的模型,NEO4J会为我们处理拓扑模型。
道家有个说法叫做万变不离其宗,不管上层的逻辑做的多复杂,CMDB 永远保存住最原始的关系,这是最好的,这样能保存它的扩展和复杂度永远维持在一个相对稳定的水平线上,那《道德经》当中也有一句话也是说过,万物之始,大道至简,衍化至繁,咱们CMDB 也是如此。




















