回表的概念
先得出结论,根据下面的实验。如果我要获得['liu','25']这条记录。需要什么步骤。
- 1.先通过['liu']记录对应到普通索引index(name),获取到主键id:4.
- 2.再通过clustered index,定位到行记录。也就是上面说的这条['liu','25']记录数据。
因此,上述就是说的回表查询,先定位主键值,再定位行记录。多扫了一遍索引树。
当然,也就多耗费了CPU,IO,内存等。
1.stu_info表案例
- create table stu_info (
- id int primary key,
- name varchar(20),
- age int,
- index(name)
- )
2.查看刚刚建立的表结构
- mysql> show create table stu_info\G;
- *************************** 1\. row ***************************
- Table: stu_info
- Create Table: CREATE TABLE `stu_info` (
- `id` int(11) NOT NULL,
- `name` varchar(20) COLLATE utf8_bin DEFAULT NULL,
- `age` int(11) DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `name` (`name`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
- 1 row in set (0.00 sec)
3.插入测试数据
- insert into stu_info values(1,'zhang',20);
- insert into stu_info values(4,'liu',25);
- insert into stu_info values(7,'huang',19);
- insert into stu_info values(10,'allen',27);
- insert into stu_info values(30,'benjiemin',27);
- insert into stu_info values(16,'roger',27);
- insert into stu_info values(28,'peter',16);
- commit
4.分析过程
我们来分析这几条数据的索引。由于我们name这个列建立了索引。所以name索引存储会按照【a~z】顺序排列。通过select语句,可以得到一些感性认识。如下:
- mysql> select name from stu_info;
- +-----------+
- | name |
- +-----------+
- | allen |
- | benjiemin |
- | huang |
- | liu |
- | peter |
- | roger |
- | zhang |
- +-----------+
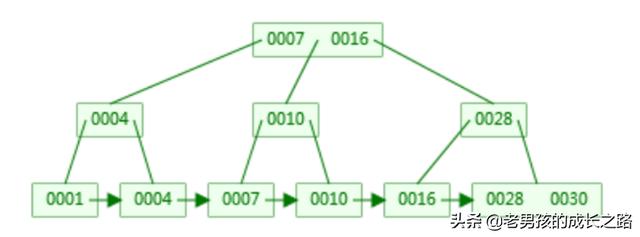
上述的普通索引secondary index在B+树存储格式可能如下:
根据旧金山大学提供的可视化B+tree的效果。
其可视化地址为:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
如下图:
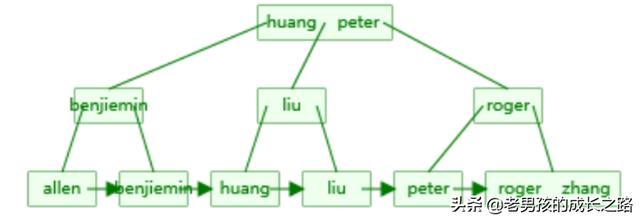
我在根据上面的图,画一个自己的。如下图所示:
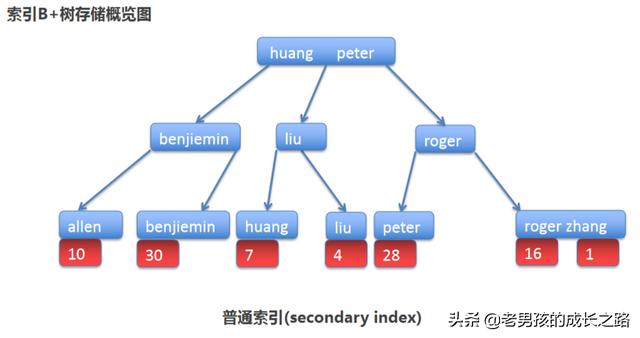
也能看到name这几个数据建立的B+树是怎么样的。也能看到我需要找到[liu]这个元素的话,需要两次查找。
但是,如果我的需求是,除了获取name之外还需要获取age的话。这里就需要回表了。为什么?因为我找不到age数据。
- 普通索引的叶子节点,只存主键。
那么clustered index聚集索引是如何保存的呢?继续使用上述可视化工具,再分析一波。
上图是聚集索引的示意图。转化为我的图如下:
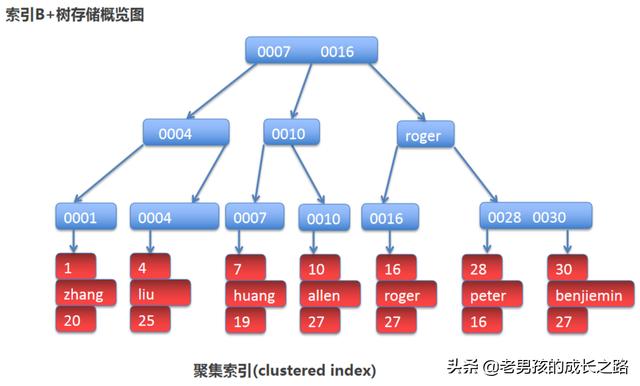
所以,name='liu'查询liu的年龄,是需要回表的。首先查询普通索引的B+树,再查询聚集索引的B+树。最后得到liu的那条行记录。
5.执行计划
我们也可以通过执行计划来分析一下,如下:
- mysql> explain select id,name,age from stu_info where name='liu'\G;
- *************************** 1\. row ***************************
- id: 1
- select_type: SIMPLE
- table: stu_info
- type: ref
- possible_keys: name
- key: name
- key_len: 63
- ref: const
- rows: 1
- Extra: Using index condition
- 1 row in set (0.00 sec)
看到Using index condition,我们这里用到了回表。
如果不取age,只取id和name的话,那么。就不需要回表。如下实验,继续看执行计划:
- mysql> explain select id,name from stu_info where name='liu'\G;
- *************************** 1\. row ***************************
- id: 1
- select_type: SIMPLE
- table: stu_info
- type: ref
- possible_keys: name
- key: name
- key_len: 63
- ref: const
- rows: 1
- Extra: Using where; Using index
- 1 row in set (0.00 sec)
那么,如果我们不想回表,不想多做IO的话。我们可以通过建立组合索引来解决这个问题。通过
- ALTER TABLE stu_info DROP INDEX name;
- alter table stu_info add key(name,age);
我们再继续看执行计划,如下:
- mysql> explain select name,age from stu_info where name='liu'\G;
- *************************** 1\. row ***************************
- id: 1
- select_type: SIMPLE
- table: stu_info
- type: ref
- possible_keys: name
- key: name
- key_len: 63
- ref: const
- rows: 1
- Extra: Using where; Using index
- 1 row in set (0.00 sec)
可以看到额外信息是Using where; Using index而不是Using index condition也就没有用到回表了。