1.缓存概述
在很久很久以前人类和洪水作斗争的过程中,水库发挥了至关重要的作用 : 在发洪水时可以蓄水,缓解洪水对下游的冲击;在干旱时可以把库存的水释放出来以供人们使用。这里的水库就起着缓存的作用。在如今互联网的世界里随着互联网的普及,内容信息越来越复杂,用户数和访问量越来越大,我们的应用需要支撑更多的并发量,同时我们的应用服务器和数据库服务器所做的计算也越来越多。
但是往往我们的应用服务器资源是有限的,且服务器技术变革是缓慢的,数据库每秒能接受的请求次数也是有限的,那么如何能够有效利用有限的资源来提供尽可能大的吞吐量呢?一个有效的办法就是引入缓存,打破标准流程,每个环节中请求可以从缓存中直接获取目标数据并返回,从而减少计算量,有效提升响应速度,让有限的资源服务更多的用户。
2.缓存的定义
缓存就是数据交换的缓冲区(称作Cache),这个概念最初是来自于内存和 CPU。当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接使用执行,缓存找不到的话则从内存中找。由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。
3.缓存的分类
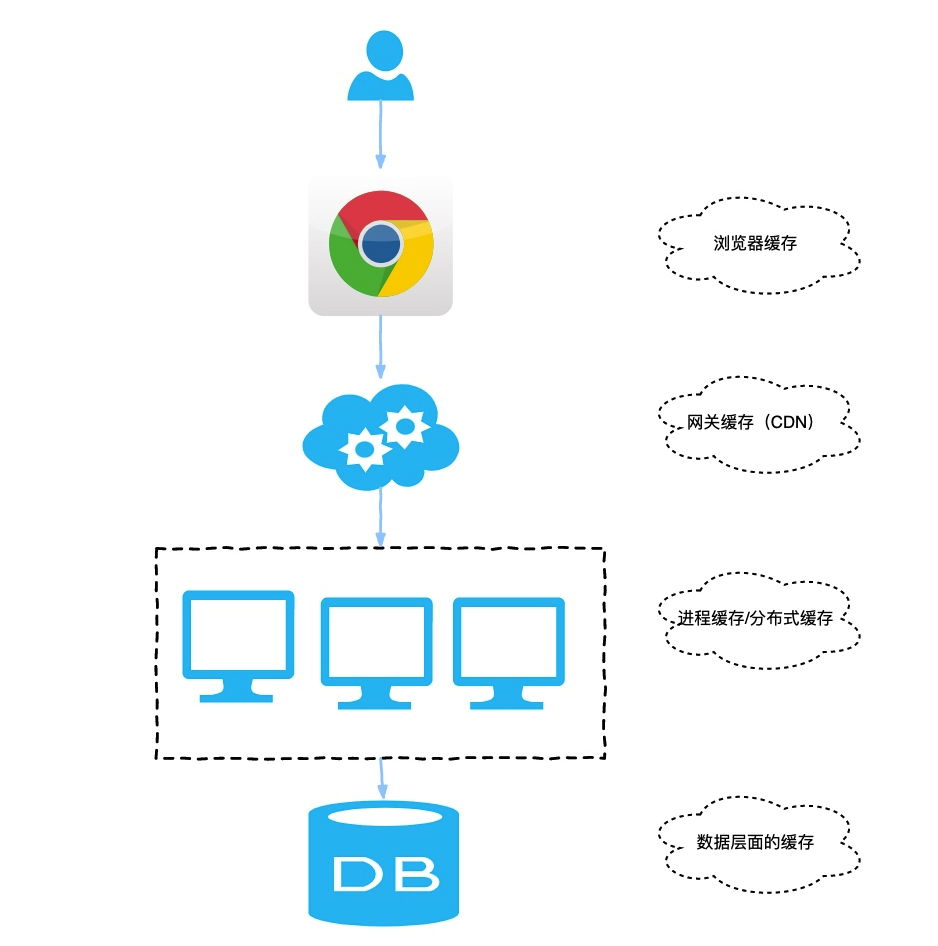
当用户从键入一个地址到页面的展示过程中通常包含了很多种缓存。有前端缓存、本地缓存(协商缓存,强缓存等)到我们的网关缓存(CDN 缓存)、最后到我们服务端缓存。服务端缓存又区分为进程缓存(本地缓存),还有比较火的分布式缓存,最后到了数据库层面的缓存。如下图所示:
4.缓存是一把双刃剑
在我们通常的软件设计中,有一些热点数据需要展示到页面,我们通常当这些数据缓存到内存或者其他读写速度优异的框架中。减少与数据库进行 I/O 操作。提升数据的响应速度。这一切看起来就是这么完美。
实际上,在缓存系统的设计架构中,还有很多坑。如果设计不当会导致很多严重的后果。设计不当,轻则请求变慢、性能降低,重则会数据不一致、系统可用性降低,甚至会导致缓存雪崩,整个系统无法对外提供服务。
接下来我们着重讲述一下在缓存设计过程中几大经典的问题。
缓存失效
先解释一下什么叫做缓存失效。
我们在存放缓存的时候,可以指定缓存 Key 的失效时间,当失效时间到了,此缓存就会失效,由于在缓存中找不到该数据,所以这个时候如果用户有请求该数据就绕过缓存直接到数据库中请求数据。
看到这里小伙伴们肯定有很多问号?
这不是很正常的现象嘛?为什么要把这个问题拿出来说呢?莫急看下图图示
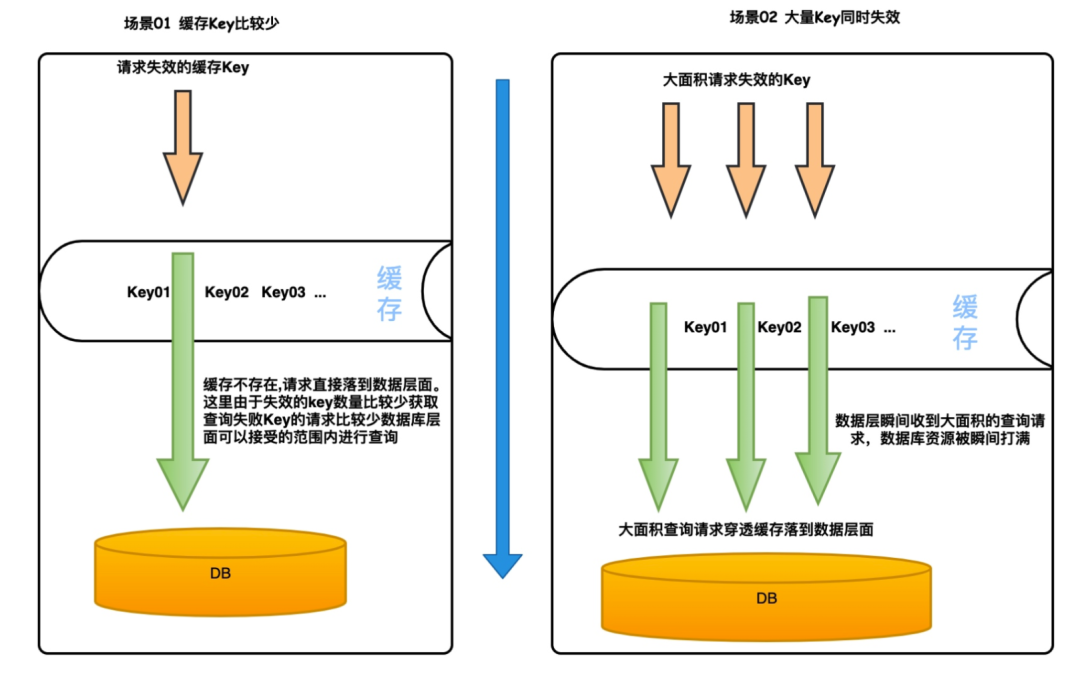
这里我们通过两个场景来说明一下
- 场景一:这种情况下一般不会对数据库造成比较严重的影响,因为失效的 key 的数量比较少,即使同时请求到数据库层面也是可以接受的。
- 场景二:在这种场景中,当缓存里面的大量 Key 同时失效,这个时候如果有请求过来,会穿过失效的 Key全部落到数据库层面。导致数据库的负荷瞬间添加。可能会出现数据库宕机等特大事故。
解决方案
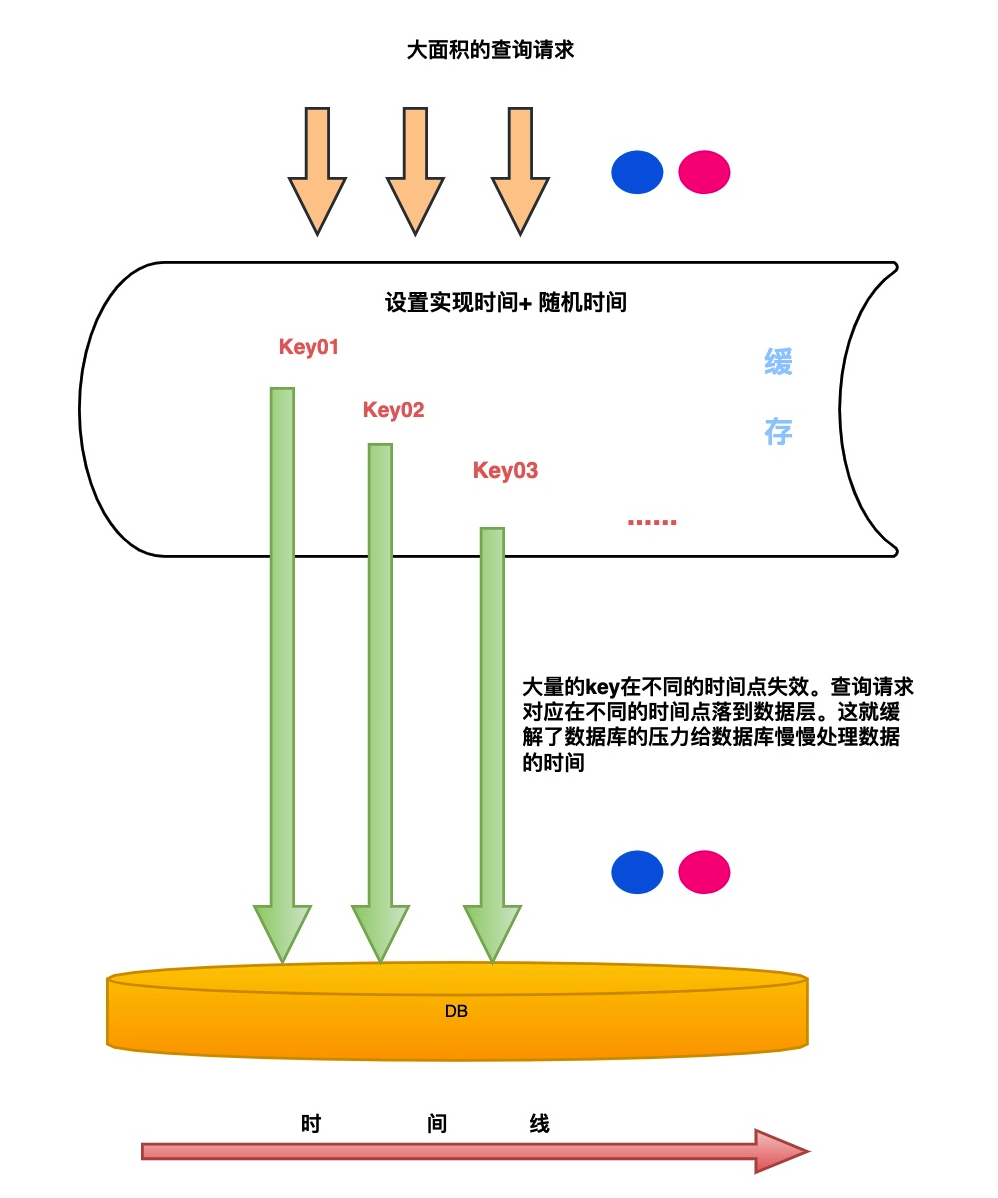
看到这里很多聪明的小伙伴其实已经想到了。场景 2 的事故主要因为很多 key 一起失效的原因,跟我们日常写缓存的过期时间息息相关。如果我们在日常的开发过程中需要将一批 Key 设置到缓存中并制定失效时间。这个时候就要注意场景 2 发生的情况。我们可以在失效时间 + 随机时间。避免大量 Key 失效冲击我们的数据库。
缓存击穿
通常情况下,我们去查询数据都是存在的。那么如果请求去查询一条压根儿数据库中根本就不存在的数据,也就是缓存和数据库都查询不到的这条数据会怎么样呢?这样会导致每次访问都会直接打到数据库上面去。这种查询不存在数据的现象我们称为缓存穿透。
下面是缓存失效的场景
很多伙伴看到这里肯定又会觉得这是一件很正常的事情。试想一下,如果有黑客会对你的系统进行攻击,拿一个不存在的 key 不停的去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉。
解决方案一
- 首先我们能想到的就是在网关参数进行过滤。校验请求的 key 是否是我们系统 key 的格式等
当然这网关层所能做到的只是一些简单过滤。每个后端的设计人员应该对服务的可用性和健壮性负责。接下来我们看看服务端应该如何处理
- 服务端可以将不存在的 key 暂时保存到我们的缓存中,再次接收到同样的请求后如果直接命中缓存并且值为空那么就会直接返回,不会穿透到数据库层面,这样就避免了缓存击穿。
但是黑客/恶意攻击者是不会这么轻易被打发的。每次请求都会传不同的 key 来攻击我们的服务。这个时候这个方案起不到作用了。
解决方案二
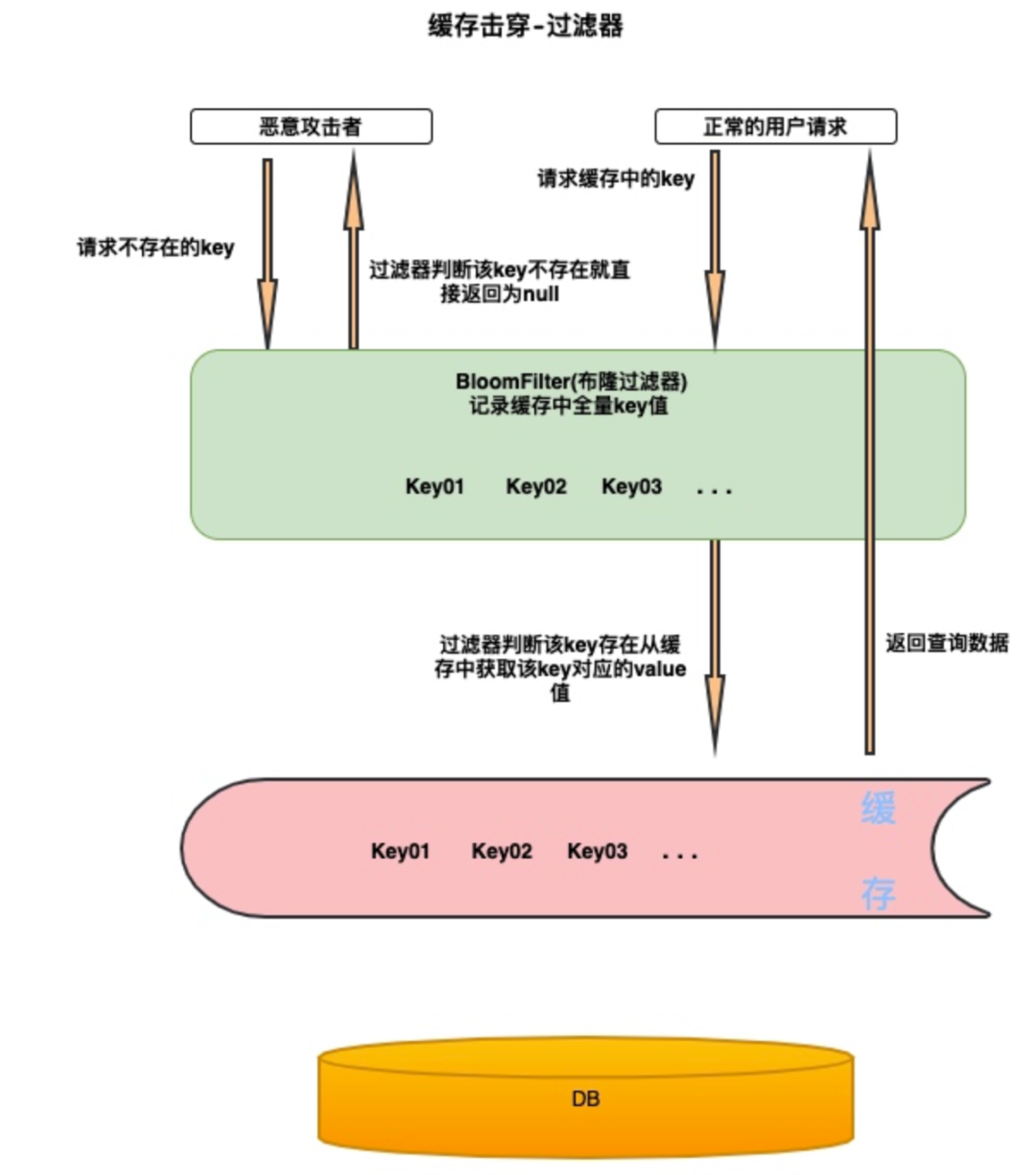
构建一个 BloomFilter(布隆过滤器) 缓存过滤器,记录全量数据。这样访问数据时,可以直接通过 BloomFilter 判断这个 key 是否存在,如果不存在直接返回即可,根本无需查缓存和 DB。这样在缓存之前加了一层校验。如果key 值不存在,就不会请求到我们的缓存更加不会到我们的数据库中。
布隆过滤器可以理解为一个不怎么精确的 set结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。即使误判不存在走到缓存和后端服务也是可以接受的。
缓存雪崩
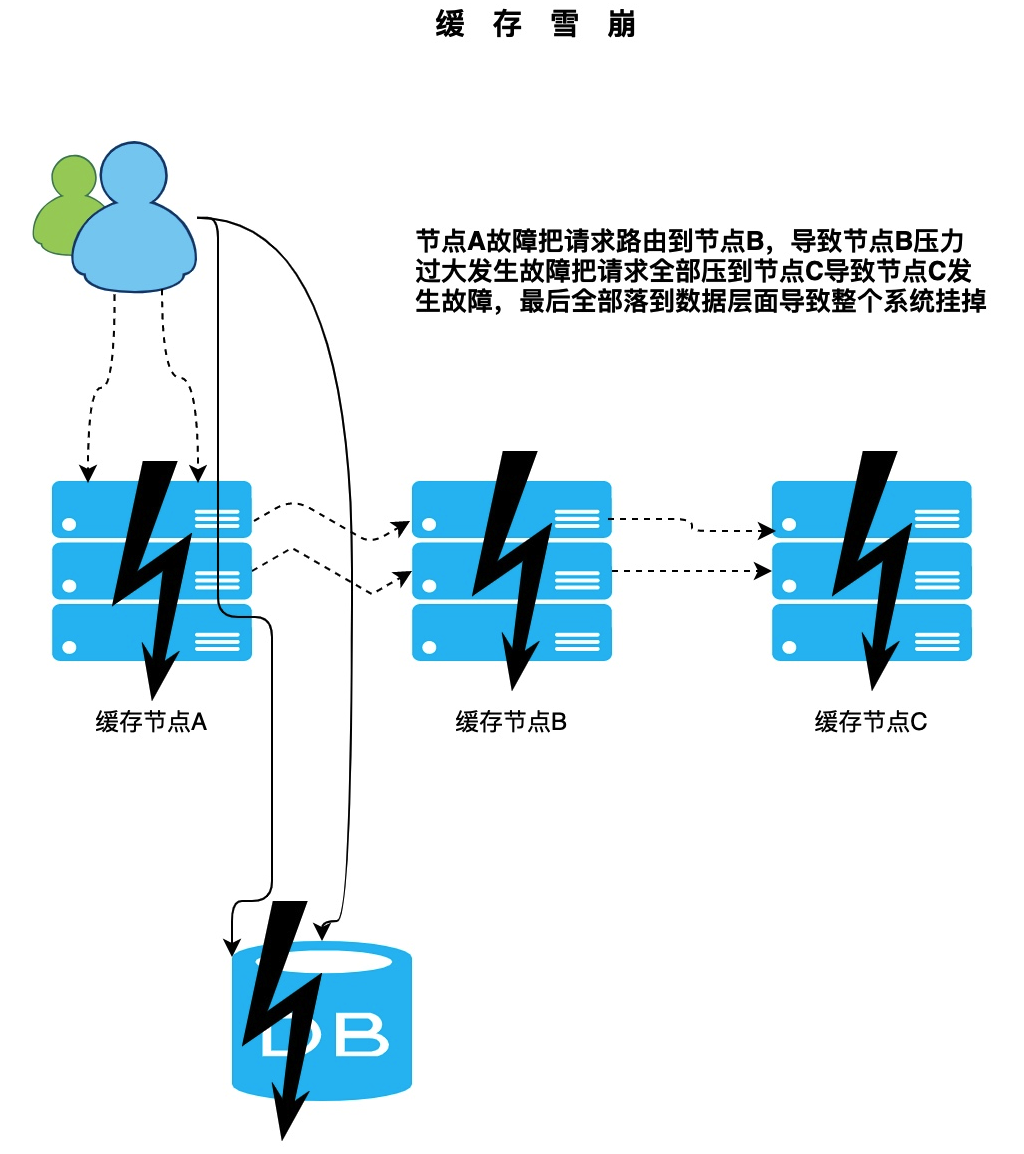
缓存雪崩是指缓存的部分节点不可用导致整个缓存体系甚至整个服务系统不可用。
那么你可能会有疑问,缓存雪崩和缓存击穿有什么关系呢?
从概念上来看,缓存击穿是因为查询不存在的 key 穿透缓存直接访问我们的数据库。而缓存雪崩是因为我们的缓存节点不可用,请求未经过缓存就直到了我们的数据库层面。然而两者都会影响我们的服务稳定性。
缓存节点的不可用会导致缓存雪崩,那么我们缓存组件集群部署是不是就解决了这个问题呢?
集群部署有两种情况:
- 一种就是简单的主从例如 redis 的哨兵之殇
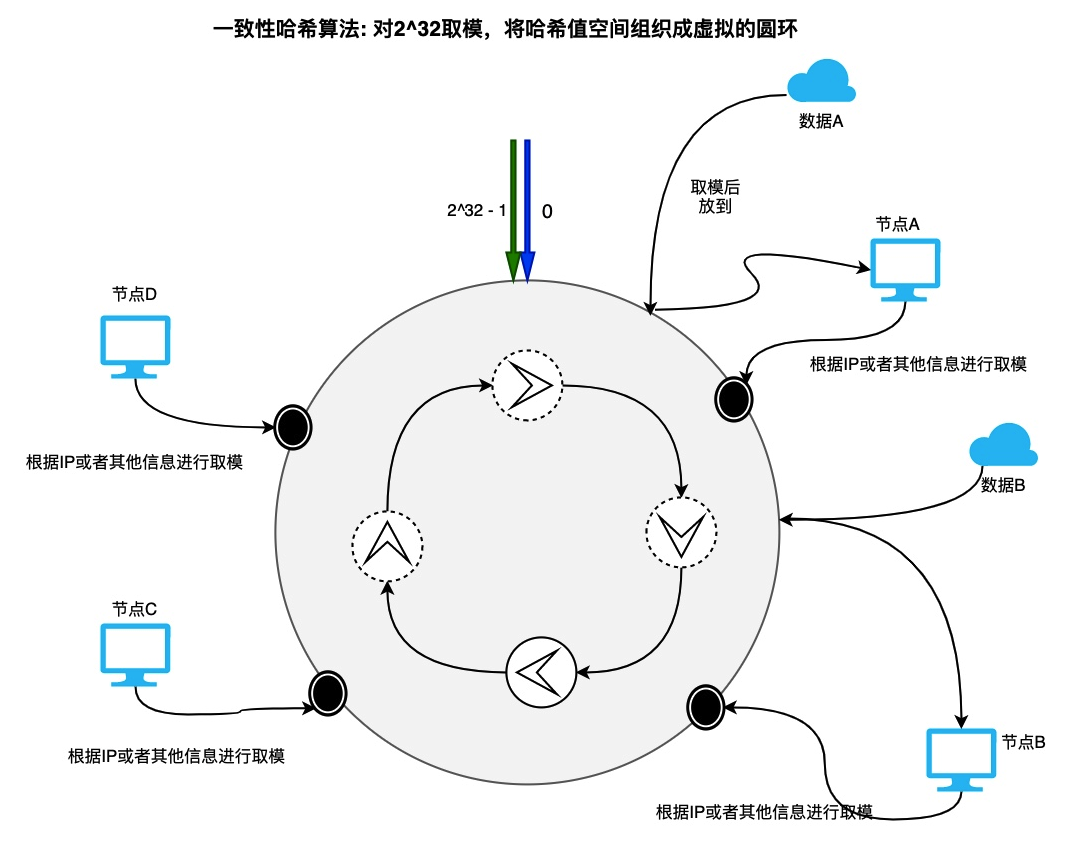
- 采取一致性 hash 算法集群部署例如 redis 的分片集群
第一种情况:发送雪崩的时候一般是多个节点同时不可用,例如我们的节点服务器内容不足,虽然分主从节点都是存储的数据都是一样的。如果缓存中的数据过大导致节点不可用。那大部分节点也会存在这个问题。请求会大面积的落到数据库层面导致后端系统崩溃。
第二种情况: 首先看一下下图虽然数据根据会根据取模算法分配到不同的节点中,假设节点 A 不可用,数据 A 会按照逆时针找到节点 B,会因为本来应该存放到节点 A 的数据存放到节点 B,以此类推会导致整个缓存节点不可用。请求也会大面积落到我们后端的数据库层面导致系统崩溃。
解决方案
- 对缓存体系进行实时监控,当请求访问的慢速比超过阀值时,及时报警,通过机器替换、服务替换进行及时恢复。
- 对缓存增加多个副本,缓存异常或请求 miss 后,再读取其他缓存副本。
- ehcache 本地缓存 + Hystrix 限流&降级,避免 MySQL被打死
- 业务 DB 的访问增加读写开关,当发现 DB 请求变慢、阻塞,慢请求超过阀值时,就会关闭读开关,部分或所有读 DB 的请求进行 failfast 立即返回,待 DB 恢复后再打开读开关。
数据不一致
数据不一致的概念很简单:就是缓存中的数据和数据库中的数据不一致。
那为什么会不一致呢?我们的数据被缓存之后,一旦数据被修改(修改时也是删除缓存中的数据)或删除,我们就需要同时操作缓存和数据库。这时就会存在一个数据不一致的问题。
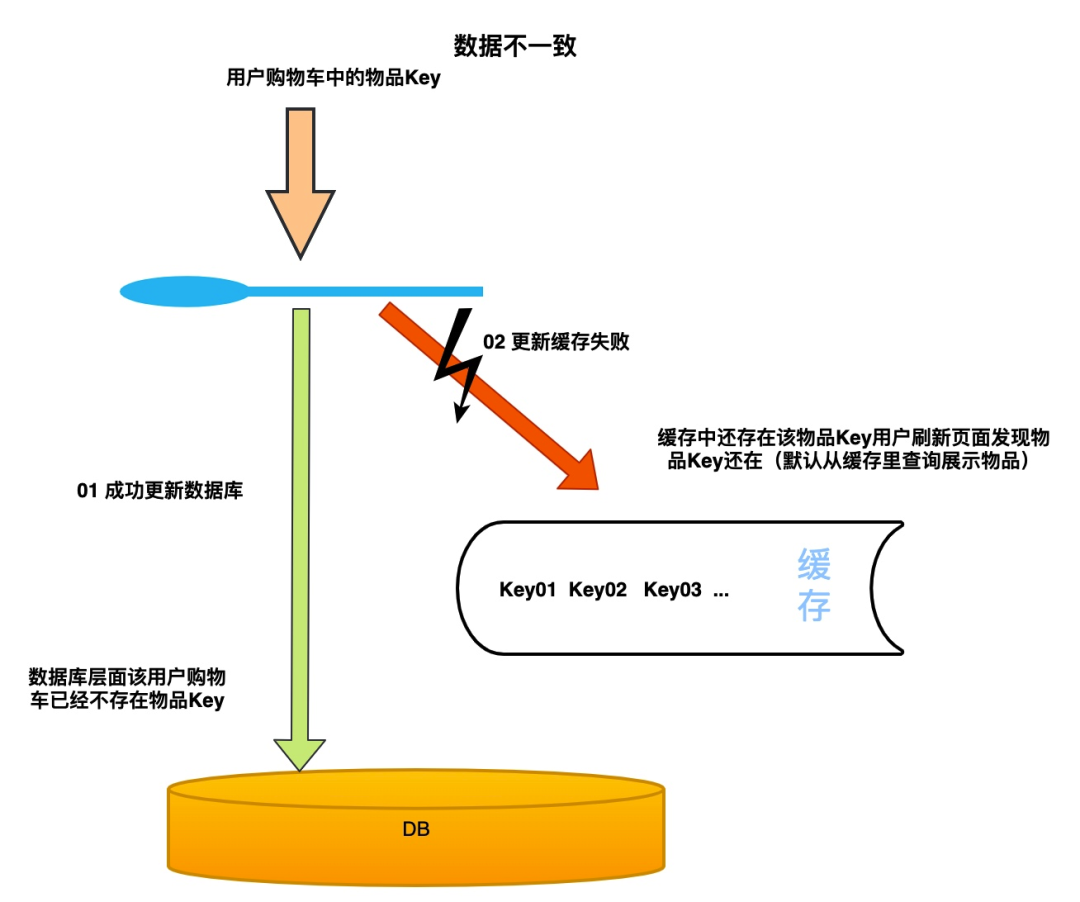
如上图所示当我们先删除数据库再去操作缓存,缓存中未删除数据库其实已经不存在该数据了。这个时候就会出现缓存不一致的情况。
聪明的小伙伴肯定想到了我们还是需要先做缓存删除操作,再去完成数据库操作。则会去数据库中查询,如果缓存中没有该数据,则会去数据库中查询,之后再放入到缓存中。这样就完美了嘛?答案肯定不会这么简单。请看下图:
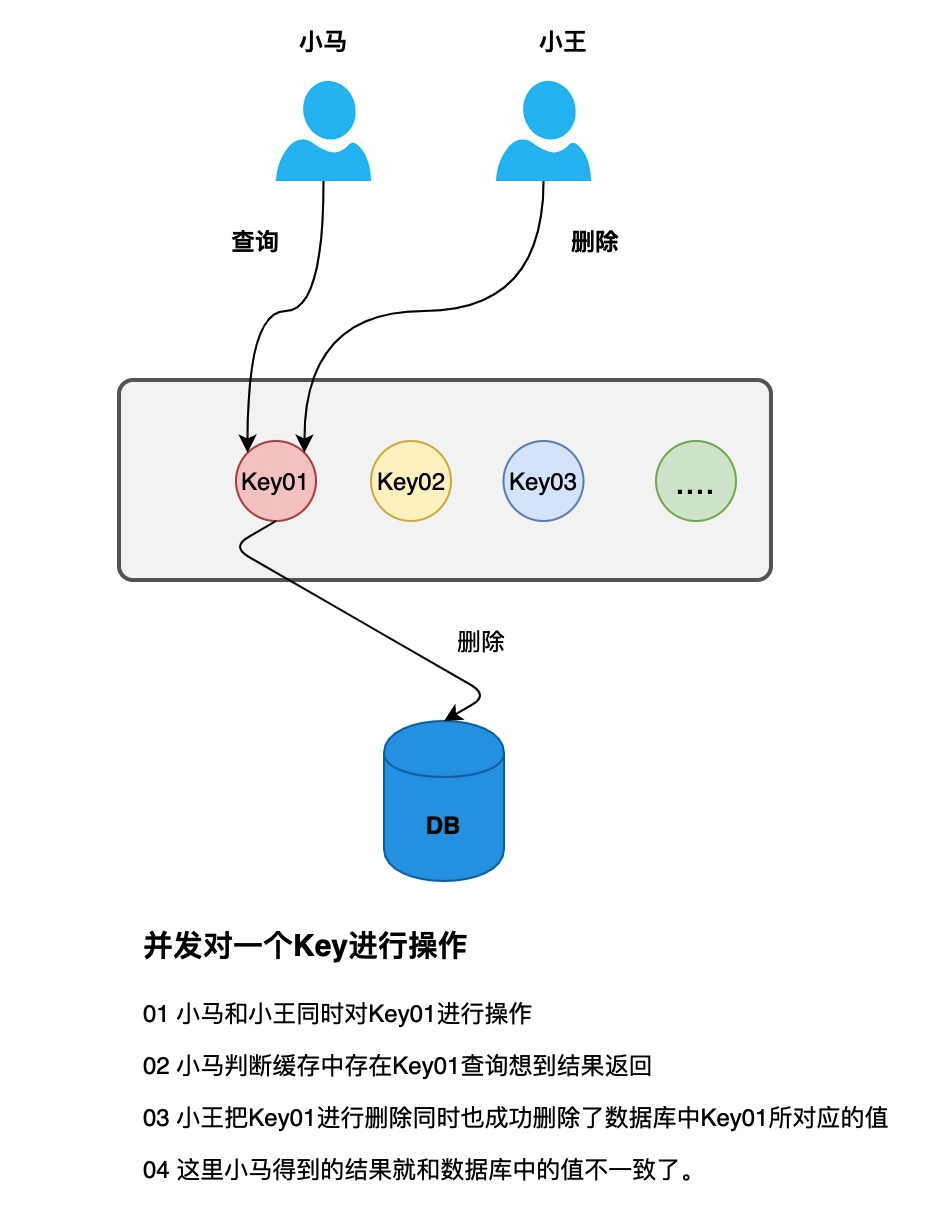
解决方案
这里其实没有什么很完美的解决方法。可以将变更的 key 添加到安全队列中。当另一个查询请求 B 进来时,如果发现缓存中没有该值,则会先去队列中查看该数据是否正在被更新或删除,如果队列中有该数据,则阻塞等待,直到 A 操作数据库成功之后,唤醒该阻塞线程,再去数据库中查询该数据。这里其实也是有很多缺陷的。线程需要阻塞等待。
最好的解决方案就是如果数据更新比较频繁且对数据有一定的一致性要求,我通常不建议使用缓存。看到这里是不是发出了一句切!!!!
5.总结
缓存虽然能大幅度的提高服务器的性能以及用户的体验感。但是随着而来的就是各种由于缓存导致的一系列问题。所以当我们使用缓存的过程中需要注意以上的经典问题。