













匿名函数
前言
上次咱们基本说了一下函数的定义及简单使用,Python中的基本函数及其常用用法简析,现在咱们整点进阶一些的。同样都是小白,咱也不知道实际需要不,但是对于函数的执行顺序以及装饰器的理解还是很有必要的。
首先咱们先简单复习一下:
函数的定义:
- def 函数名字(参数):
- 具体的函数语句块
- return [需要返回的数据]
函数的执行:
- # 函数只有被调用的时候才执行,函数可以执行多次
- 函数名称()
局部与全局变量:
不同的函数有不同的作用域
- def test1():
- name = 'XXX'
- print(name)
- def test2():
- name = 'YYY'
- print(name)
- test1()
- test2()
- 局部想使用全局变量 使用global 变量名
- 局部与全局变量同名仍要同时使用全局变量局部变量 globals()['变量名']
还有一种情况就是函数内嵌套了函数想使用上次层函数的变量。
- def test1():
- name = 'XXX'
- def test2():
- # 使用上一层的变量并打印查看
- nonlocal name
- print(name)
- # 在函数test1中调用执行test2
- test2()
- test1()
- # 直接调用test2会抛出异常test2 未定义
- # test2()
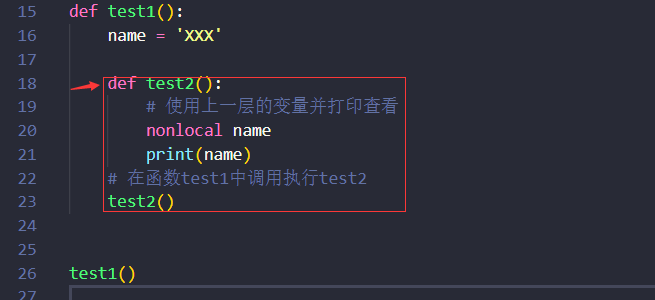
因为箭头那里有空格,Python也是根据这种格式来判断作用域的,只能像红色框那样在同一级的地方调用。
一个函数内返回另一个函数:
- def test1():
- print("in the test1")
- def test2():
- print("in the test2")
- return test1()
- test2()
想把上面的这段代码解释清楚,咱们插播一个递归。
递归的特性:
- 递归就是自己调用自己
- 必须有个明确的结束条件,不然会导致栈溢出
- 每次递归问题都有所减少
- 递归效率不高,但是有时候真的好用
来个最经典的斐波拉契数组。
- # 斐波拉契数组长这样:1,1,2,3,5,8,13,21,34,55...
- def fabonacci(n):
- # 结束条件
- if n <= 2:
- # 因为前两个数字都是1,所以当n小于等于2时返回1
- v = 1
- return v
- # 大于2的话就自己调用自己,斐波拉契第n个数字等于n-1的数字+n-2数字的和
- v = fabonacci(n-1)+fabonacci(n-2)
- return v
- print(fabonacci(6))

- import sys
- # 打印当前递归深度,默认为1000
- print(sys.getrecursionlimit())
- # 设置最大递归深度
- sys.setrecursionlimit(999999999)
- print(sys.getrecursionlimit())
其实就是表达函数内调用另一个函数,会等待另一个函数执行完毕,该函数再执行到结束...感觉递归讲不讲都一样了...so,咱们还是赶紧回到正题,代码的执行顺序是这样子的....
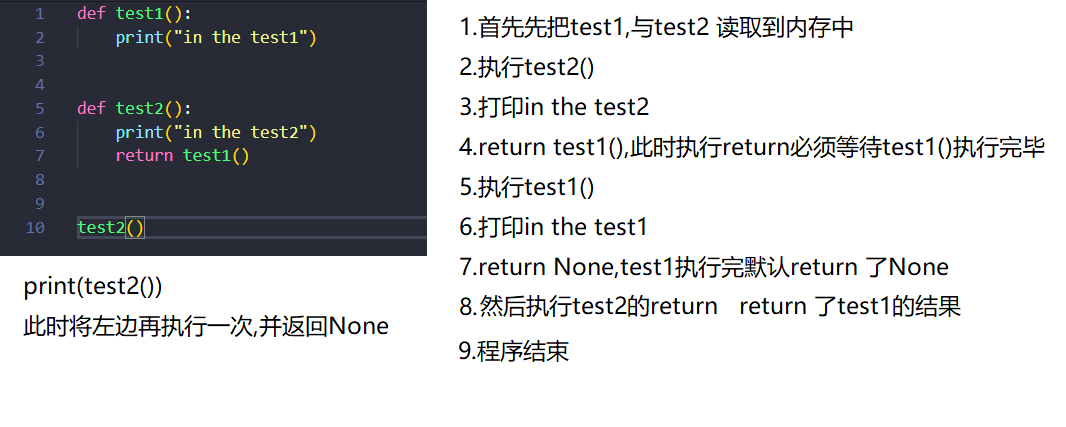
当然还能这么玩:
- def test1():
- print("in the test1")
- def test2():
- print("in the test2")
- # 此处返回test1的内存地址
- return test1
- test2()()
- # 先执行test2(),返回test1的内存地址
- # 加上小括号执行test1
匿名函数
- 使用lambda 创建
- 简单来说匿名函数就是一个没有名字的简单函数
- 匿名函数只有一个表达式,return 表达式计算的值
创建一个简单的匿名函数,命令如下所示。
- 格式 lambda 参数列表:表达式
- lambda num1, num2: num1+num2
使用一个变量接收一下,就是保存的内存地址,加上小括号传入参数就能运行了。
- func = lambda num1, num2: num1+num2
- print(func(1, 2))
我使用的编辑器是VS Code ,发现了一个问题,格式化代码的时候把匿名函数改成了函数...具体原因及细节未知。
格式化前:
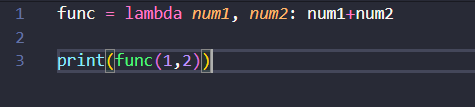
格式化后:
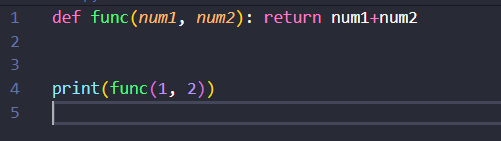
map 映射(循环让每一个函数执行函数,结果保存到新的列表)
map(匿名函数,可迭代对象)
map()处理序列中的每个元素,得到的结果是一个可迭代对象,该对象个数和位置与原来一样。
- li = [1, 5, 3, 2, 3]
- res = map(lambda x: x+1, li)
- print(type(res))
- # 返回的map对象
- print(list(res))
filter 判断
filter()遍历序列中的每个元素,得到的结果是True则留下来。
- people = ['sb_laowang', 'sb_xiaozhang', 'sb_laozhang', 'xiaoliu']
- # 将满足以帅比开头的保存为新的对象
- res = filter(lambda x: x.startswith('sb'), people)
- print(type(res))
- print(list(res))
reduce:将序列进行合并操作
- from functools import reduce
- num_li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- str_li = list('hello')
- res_num = reduce(lambda x, y: x+y, num_li)
- res_str = reduce(lambda x, y: x+y, str_li)
- print(str_li)
- print(type(res_num), res_num)
- print(type(res_str), res_str)
第一次运行的时候x,y是可迭代对象的前两个,后面x都是之前的累加,y则是没有进行累加的第一个,说一下reduce(lambda x, y: x+y, num_li)这个吧,可以打个断点看一下。
- 第一次x = 1 , y = 2
- 第二次x = 3 , y = 3
- 第三次x = 6 , y = 4
- 第四次x = 10 , y = 5
- ...
匿名函数的好处:
- 简化代码
- 没有名字,避免函数名字冲突
查看某个模块的所有方法:
- # print(dir(模块名字))
- # 例如:
- import time
- print(dir(time))
- print(dir(list))
提取数据结构:
- # 可能有这种需求,一个人给你个文件,读取出来是文本,或者是需要计算的公式,但是他是字符串
- # 假如是个字典格式的 {'name':'sb'},但是他是个文本
- temp1 = "{'name':'sb'}"
- print(temp1,type(temp1))
- temp2 = eval(temp1)
- print(temp2, type(temp2))
- temp3 = "1+2"
- print(eval(temp3))
- # 注意只能提取出来格式与要提取的格式一样的文本
总结:
本文基于Python,主要讲解了递归思想和匿名函数相关知识,例举了几个常用的匿名函数及其基本用法,如lambda、map、reduce、filter等,并简述了匿名函数的优点。关于匿名函数,还有以下一点需要注意。
匿名函数书写简单,适用于仅有一个简单表达式的函数,并且避免了函数名字冲突的问题,两个函数名字冲突下面函数会覆盖上面函数的功能,如:
- def func():
- print('aaa')
- def func():
- print('bbb')
- func()
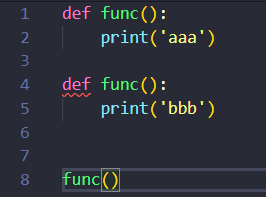

但是编辑器能检测出两个同名的函数,有一个编辑异常,虽然能正常运行,但是显然不符合代码开发规范。匿名函数没有名字肯定不会出现函数名字重复。













