













本文转载自公众号“读芯术”(ID:AI_Discovery)
下面这种模型你肯定见过,高德纳优势分析模型在数据分析和数据科学会议上实在是太常见了。
不要与卡内基梅隆大学的能力成熟度模型混淆,该图表被多样地称作成熟度模型、连续体,甚至是自动扶梯。有时,公司也会颠倒用词次序使用。而行业术语常常将其称为分析成熟度模型,本文也将使用这种叫法。
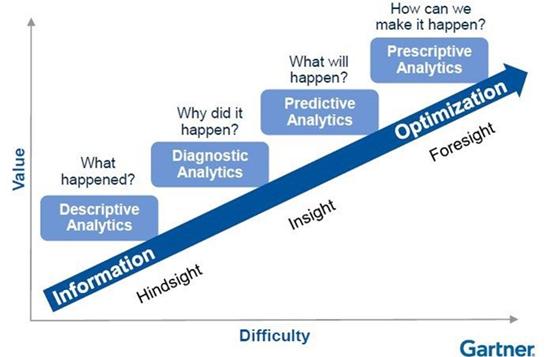
分析成熟度模型令人无法抗拒…
人们太偏爱这种模型了,主要原因有以下几个:
(1) 它的比喻是吸引人且能引发共鸣的。“这就像是一个孩子在成长。首先学着爬,其次是走,最后是跑。”与会者很容易理解这种比喻,并表示赞同。
(2) 其格式与新闻记者使用的经典5W1H技巧十分接近,能够立即吸引人们的注意。
从据理力争的创业数据极客到身着细条纹套装的企业销售分析人员,任何人都可以传达典型的套话:“我们从‘发生了什么’开始,接着直观地转到‘为什么发生’,再到‘将要发生什么’,并以令人满意的‘我们如何实现这一目标’结束。”
(3) 它有助于公司发展。常见的介入式咨询模式始于在成熟度模型上对公司所处位置的评估。然后,公司用对应的级别来确定接下来要优先学习的能力。
因此,该模型不仅通过令人印象深刻的能力结构,且通过清晰的提升路线图,为公司提供了十分清晰的发展思路。
但该模型包含可能阻碍数据科学发展的错误假设
以这种方式表现模型,在视觉上引入了许多巧妙的假设。不幸的是,这些假设中有许多是错误的,并且可能严重阻碍数据科学团队的发展。
这就很讽刺了,该模型旨在帮助公司做出更好的数据驱动型决策,却导致了建立数据科学团队的错误决策。
成熟度模型被构造为一系列效益级别。然而,在我们做以下假设时,风险也随之而来:
- 从底部开始,按顺序前进到各个级别
- 每个更高级别都比之前的较低级别带来更多价值
- 管理这些能力的方式属于同一领域
这些假设无一正确
让我们来一次性解构这些假设:
在进阶到高级分析前,无需“完成”附加描述型分析。
首先,一家公司如何准确地“完整拥有”附加报道、商业智能和分析能力?数据是不断变化的世界的动态表示,只要世界不断变化(这当然是永远的,且速度会不断加快),描述型分析就会有新的要求。
成熟的数据管理十分重要,出色的数据平台是数据科学的有力支持,且拥有所有所需数据并进行建模是一种难得的乐趣。拥有良好的数据仓库和数据湖,为随机森林的生长创造了一片肥沃土壤。
然而,数据仓库项目需要等待多年完成,在此期间还将数据科学团队部署到从事结构化查询语言(SQL)和归档责任的工作,这是得不偿失,甚至还会促使数据科学团队跳槽。
从根本上讲,除非正在构建产品功能,否则数据科学和数据分析的价值源泉仅来自于一个因素——就是决策。
如果数据科学家能通过数据来影响决策以达到更好效果,那么就可以创造价值。如果决策仍没有改变,那么就浪费了时间。无论安全高性能云托管可解释深度学习模型多么强大,都不会改变决策。整个团队极有可能存在数年,工资照领,却没有创造出任何价值。
在高级数据分析有所进展的机会渺茫的同时,无需在成熟度模型的较低级别上停留。数据科学家在少量但重要的业务决策上立即创造价值也是常见情况。
一个更好的策略在其简单程度方面几乎是可笑的:让数据科学家参与到可以接触到的最高层人员作出的最重要决策中。
坐在高层人员身边,了解他们的想法和决策过程。从他们已经想到的地方开始,继续推进思路。查看本地访问数据库、Excel电子表格程序。查找管理会计师,并运用你储备的各项技术来改善决策。
更高级别的数据分析是否能带来更多价值尚不确定
计算预测或规范模型的价值或“提升”有许多完善的方法,例如,可以利用统计技术来预测世界状况,你无需使用模型进行干预,一段时间后,再将其预测值与真值、创造价值进行比较。
例如,在启动数据科学项目以增加零售产品销售之前,可以预测在没有任何模型干预的情况下,下个月的收入可能是1万美元。执行定价和促销模型后,收入为1.2万美元,包括2000美元的模型营销增益。
但矛盾的是,计算描述型或诊断型工作的价值可能会非常棘手。人们如何准确地量化意识的价值?如果一个人被蒙住眼睛行走,那么如何估计他摘下眼罩的价值呢?
不同类型工作在完全不同的管理方法下蓬勃发展
我们知道,不同级别的团队可以并行工作,并以不同的方式衡量价值。这还没完:团队在成熟度模型下限停滞不前的一个重要原因就是,使描述型和诊断型分析有效的管理范式可能为预测型和规范型工作敲响“丧钟”。
简而言之,前者在强大的“工程”模式下蓬勃发展,要求互联网技术风格,拥有强大的项目管理和稳健的流程。而后者则在定义了起点和终点的项目范围外工作效果最佳。
二者最大的区别在于数据不确定性。预测型和规范型分析的特殊风险是:无法保证数据中包含足够的信息,使预测型和规范型分析的应用程序变得有价值。
更复杂的是,还可以使用多种通常同样有效的技术,来解决给定的问题。因此,必须有足够的空间进行早期尝试、试验和失败,使其影响较小。
如果正在建立用于预测型维护的机器学习模型,并且发现可用数据没有任何有用的信号,那么在笔记本电脑上进行两周的实验后失败总比在六个月的预算项目和十人团队中试验失败要好得多。
概言之,成熟度模型对团队造成损害的主要方式是:企业采用用于提供描述型分析解决方案的管理方法,并将其强加于高级分析工作中,而不去改变导致数据不确定性的方法。
通向更好的数据科学团队成熟度模型
成熟数据科学团队的选择是什么呢?
首先,抛弃描述型、诊断型、预测型和规范型兼具的模式。在一线,工作通常在这四项分析模式间无缝过渡。数据分析和数据科学专业人士始终在全面地进行诊断工作。
而且,每当有人从建立可视化转变到建立机器学习模型(反之亦然),并将此作为日常工作的一部分时,把公司的主要流程强加其上是费力不讨好的。
人们不该将分析成熟度和其价值比作正在长个头的孩子,这是在单个维度上的连续增量。更准确的出发点应从两个维度看待成熟度,即实际上创造价值的维度:决策支持或生产系统。
生产中成熟的决策科学和数据科学
我们真正想要的成熟度是决策科学成熟度。在这里,“工程学”就是次要的了。取而代之的是研究数据素养和数据解析、减轻认知偏见、并建立正确的指标和激励措施和实际奖励数据驱动的决策。
建立数据科学产品或将模型投入生产是一项十分不同的活动。它需要成熟的流程来确认数据不确定性,安全的空间进行实验以降低高级分析工作的风险,上线后适当的模型操作,以及针对产品而非项目量身定制的财务模型。
本文中还省略了一些现实生活中数据科学团队的复杂性:人工智能的子学科是否被视为科学或工程学?对于拥有博士学位的人最应该去哪里?仅调用预训练模型的人属于一名数据科学家?数据工程应该成为一个单独的团队吗?
数据科学是一个不断发展着的学科,这些问题都是快速发展过程中不断催生出的问题,也是我们必须去适应和解决的问题。















