本文转载自公众号“读芯术”(ID:AI_Discovery)
2019年初,笔者几个人尝试构建端到端ML框架。我们认为,构建ML管道是一种令人沮丧的、脱节的体验,我们完全可以构建更好的东西。但事情并不像想象中那样顺利。
我们使用Kaggle数据集为ML管道的不同阶段(数据摄取、培训、部署等)进行了抽象,并公开了存储库来源并分享。一个月后,它登上了HN的头版,改进机器学习的用户体验是很多人的关切点。半年后,它在GitHub拥有了几百个“星星”,但几乎没有人使用它。痛定思痛,我们删除了90%的代码库。
经历这一切之后,我们建立了一个更好的项目:Cortex(模型服务基础设施)。但对于任何对机器学习和/或ML工具感兴趣的人来说,这都是一个警醒你的故事:
“生产机器学习确实需要更好的UX,但是ML生态系统是复杂和多变的,这使得构建一个覆盖大量用例的工具非常困难。”
为什么需要端到端ML框架
大多数人(Cortex贡献者)都有devops和web开发的背景,他们习惯于将应用程序的不同层抽象成单一接口的框架。
每个刚刚开始学习机器学习的人,都会感慨工具的脱节。你想建立推荐引擎和聊天机器人,在这一过程中你会发现自己在不同的环境之间来回跳转——Jupyternotebooks、终端、AWS控制台等。编写粘合代码和TensorFlow样板的整个文件夹可以被称为“管道”,这是很必要的。
如果可以用配置文件和命令来代替所有的修改和粘贴:
- $ deploy recommendation_engine
看起来还不错。接着我们构建一个工具,使用Python来转换数据,使用YAML来构建管道,使用CLI来控制一切:
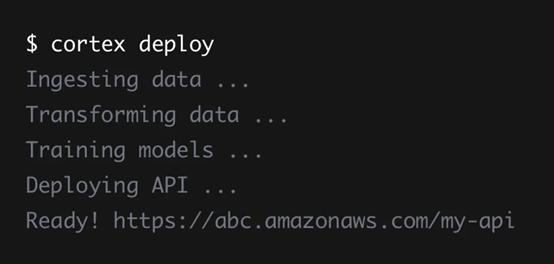
当你给它一个Kaggle数据集,使用支持的狭窄堆栈,再加上在api上设置的限制时,它是一个非常棒的工具。但问题来了,如果尝试在现实世界中使用它,那么它可能无法与堆栈一起工作。
虽然有些问题归结于设计,但很大一部分问题实际上是构建端到端工具的固有问题——只是在构建之后才发现。
端到端ML框架的问题
简单地说,机器学习生态系统产品对于端到端框架来说尚未成熟。ML工程师希望使用更好的UX工具,这当然无可厚非。但是试图构建一个涵盖多个用例的端到端框架,那你就错了,尤其是特别是在只有少数贡献者的情况下。
web框架或许会给我们启发,想想它们是什么时候开始崭露头角的吧。
Rails、Django和Symfony都是在2004年到2005年间发布的,它们都是web新MVC框架的一部分。虽然那时的web开发可能不是“稳定的”,特别是考虑到它走向成熟的过程(这很大程度上要归功于那些框架),但是web开发人员所做的工作仍然有高度的相似性。
事实上,Rails最早的格言之一是“你不是美丽而独特的雪花”,这是指大多数web开发人员都在构建架构上类似的应用程序,这些应用程序可以在相同的配置上运行。
机器学习产品还没有到那个阶段,一切仍在变化之中。数据科学家在他们处理的数据类型、使用的模型体系结构喜欢的语言/框架、应用程序的推断需求以及几乎所有能想到的其他方面都有所不同。
更重要的是,该领域本身就变化迅速。我们可以看到,自从Cortex18个月前首次发布以来:
- PyTorch已经从一个很有前途的项目变成了比较流行的ML框架,同时发布了许多专门的培训库(比如微软的Deep Speed)。
- 大量初创公司已经开始使用转移学习和预培训模型来微调和部署具有少量数据的模型(例如,现在不是每个人都需要100个节点的Spark集群)。
- Open AI发布了有史以来比较大的模型,15亿参数的GPT-2。此后,谷歌、Salesforce、微软和英伟达都发布了更大的型号。
变化从未停止,这意味着试图构建一个支持“正确”堆栈的端到端框架从一开始就注定要失败。
每个人都会要求他们需要的“一个功能”,但是没有人有相同的要求。我们尝试了一段时间,但很快发现“用Django换ML”是不可行的,至少不是想象中的那种方式。
关注模型服务基础设施
端到端是很困难的,因为ML生态系统的大部分就像“蛮荒之地”般尚未成型。然而,有一个领域是稳定和一致的:模型服务。
不管使用什么堆栈,大多数团队都是通过将模型包装在API中并部署到云中来将模型投入生产的。但数据科学家不喜欢它,因为用于构建可伸缩web服务的工具——docker、Kubernetes、EC2/GCE、负载均衡器等等——都不在他们的控制范围之内。
这是一个好机会。模型,即微服务的设计模式在团队中是一致的,而作为基础设施一部分的工具,也是非常稳定的。同时,作为软件工程师,在构建生产web服务方面比ML管道更有经验。
所以,我们认为应该给模型这个机会。我们应用了相同的设计原则,抽象了声明式YAML配置和最小的CLI背后的所有低层争论,并自动化了将经过训练的模型转换为可伸缩的生产web服务的过程。
通过专门关注模型服务,我们可以不知道堆栈的其他部分(只要模型有Python绑定,Cortex就可以为它服务)。因为Cortex可以插入任何堆栈,开始对Cortex在底层使用的工具有自己的看法,这反过来又使它更容易构建更高层次的功能。
例如,自从发布了用于模型服务的Cortex之后,增加了对GPU推理、基于请求的自动缩放、滚动更新和预测监控的支持。不需要为十几个不同的容器运行时和集群协调器实现这些特性。Cortex在引擎盖下使用了Docker和Kubernetes,而且用户根本不用操心它们。
到目前为止,这种方法似乎是有效的:
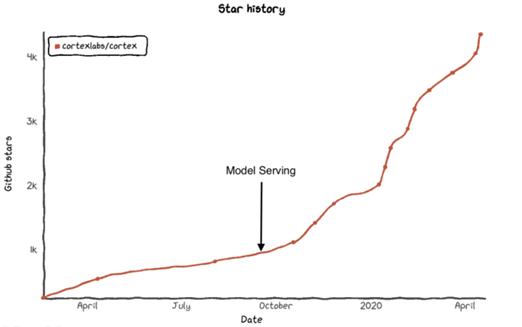
图源: Star History
将web开发的经验应用到ML工具中
从哲学上讲,web框架对如何看待Cortex有很大的影响。
像Rails和Django这样的框架非常重视程序员的工作效率和幸福感。要构建web应用程序,你不必担心配置SQL数据库、实现请求路由或编写自己的SMTP方法来发送电子邮件。所有这些都被隐藏到直观、简单的接口之后。
Cortex也是同样的。数据科学家不必学习Kubernetes,而是专注于数据科学。工程师们也不需要浪费几天时间来研究如何避免5GB版本的把他们的AWS账单搞到爆炸,他们可以自由地构建软件。
我们希望,随着ML生态系统的成熟和稳定,这样的“哲学”会慢慢扩展到堆栈的其他部分。而现在,模型服务就是一个很好的起点。