在过去两年中已生成了90%的现有数据。 每天产生7.5亿兆字节的数据-每人约147,000千兆字节。 这些数字惊人,但可以预料:世界在增长,而机器经济也在以指数级增长。
这并不是说所有这些数据都立即有用。 如果没有大量的预处理,组织就不能简单地利用这些资源,但是有人在工作吗? Forrester报告称,在企业公司内部,仍有73%的数据未用于分析。 业务策略和数据策略之间仍然存在很大的差距-您组织的预测性解决方案将仅与初始问题陈述一样坚固。 根据Gartner的说法,组织需要建立特定的用例,并部署具有可衡量结果的技术,以实现AI的价值。
数据是一大难题
这个比喻仍然存在-数据就是新的石油(尽管最晚在2006年创造了这个词,也许并不是那么"新")。 在原始状态下绝对有价值。 精制后,它甚至更有价值。 但是,当将其转变成专门为解决特定问题而设计的产品时,其应用将无数,其价值将飞速增长。
数据也是如此:组织需要记住,这里的最终目标不是收集尽可能多的数据。 他们需要从数据中提取价值并将其应用于特定的业务问题。 观察数据,从中学习数据,然后基于该反馈使工作自动化的想法是机器学习的核心。
> GIF via giphy
尽管好莱坞经常描述这种情况,但ML并没有朝着证明"终结者假说"的方向发展。
了解机器学习
在任何组织成为数据驱动者之前,了解基础知识很重要。 人们通常认为机器学习的最终目标是对实时仪表板上显示的数据进行图形化和可视化处理。 ML与自动执行任务有关(而不是与替换工作有关),而不仅仅是显示统计信息。 广义上讲,机器学习向计算机教授有关世界的知识,以便机器可以使用该知识执行其他任务。 另一方面,统计信息可以教给人们一些有关世界的知识,以便他们可以看到更大的图景并做出明智的决策。
埃森哲称,与那些追求概念验证的公司相比,从战略上扩展AI的公司报告的AI投资回报几乎是其三倍。 显然,ML并不是一些笨拙的仪表板; 实际上,它可以帮助您的组织构建可以模仿,扩展和增强人类智能的智能系统,以实现某些"机器智能",从而使组织中的人员可以专注于解决更适合人类的问题。
但是,大多数组织都在努力实现可扩展的AI解决方案,并且没有从中受益(参见:金钱)。 问题? 您的组织不是人才短缺,而是战略短缺。 不服气吗? 我们来看一些数字。
可扩展的解决方案
自2015年以来,数据科学工作需求增长了344%。 我们可以清楚地看到,组织正在投资发展其数据科学团队,给人的印象是,如果他们继续聘用数据科学家,创新和数字化转型将自动成为副产品。 但是,仅使用了27%的企业数据,而将外部数据考虑在内则更加令人震惊-在世界上所有可用数据中,只有不到1%用于分析。
所有这些数据都有一个临界点。 公司可以花费数百万美元来组建庞大的数据团队,以搜寻Internet到处寻找和准备数据的方法-但这永远不是可扩展的解决方案,而且缺乏管理策略会造成瓶颈。
公司需要什么来部署AI和ML?
那么,流程从哪里开始,组织如何实际构建和部署成功的机器学习项目?
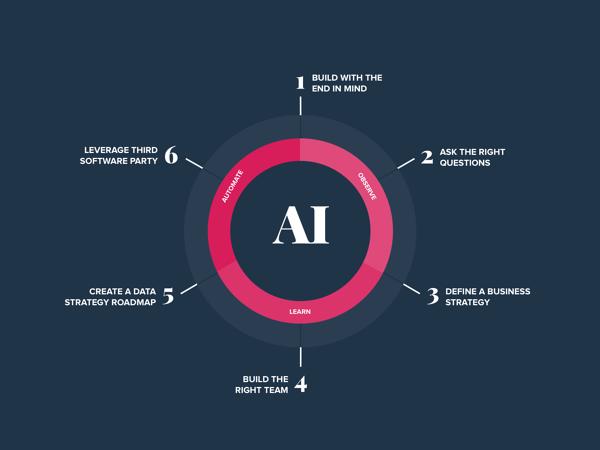
(1) 从结局开始。 您必须清楚地了解自己面临的问题以及想要实现的解决方案。 在保龄球比赛中,每个球都可以击倒十个针脚,但是如果您朝正确的方向扔球,那将是一场完美的比赛。 使用ML,您需要了解您的目标。 组织以目标为导向,他们一直在寻求增加收入和提高KPI-如果您的问题不能解决这些目标,则可能会偏离目标。
(2) 提出正确的问题。 大多数企业在尝试解决ML问题之前并没有提出正确的问题。 分析并了解您可以回答的内容和无法回答的内容,然后弄清楚您的预测系统如何使最终用户真正受益。 要问的一个关键问题:"我的项目会被它可以为组织创造的价值深深地驱动吗?"
(3) 定义业务策略。 必须使用将应用于其他项目的数据和ML项目来实现相同的策略制定细节。 您需要特定,可衡量和可实现的目标,实施计划以及有助于跟踪项目成功的指标。 仅从技术层面上看项目是不够的,您需要能够将解决方案连接到您的组织。 例如,在实施模型之后,您的公司会增加收入还是在市场上获得牢固的竞争优势?
(4) 建立合适的团队。 组织常常无法招到合适的人选,因为他们要么不知道自己想要实现的目标,要么对数据科学家的角色有相互矛盾的认识。 数据团队不仅由数据科学家组成,而且由更多的角色组成,并且认为一个角色能够建立和维护仓库,架构数据工作流程,编写完美优化的机器学习算法并对所有内容进行分析都是无知的。 为了填补项目的正确角色,您需要明确定义目标,了解每个技术角色/团队结构的细微差别,并确保在招聘信息中列出所有这些内容。 下图显示了核心技能对于数据科学中新兴角色的相对重要性:

> Chart of skill importance in Data Science
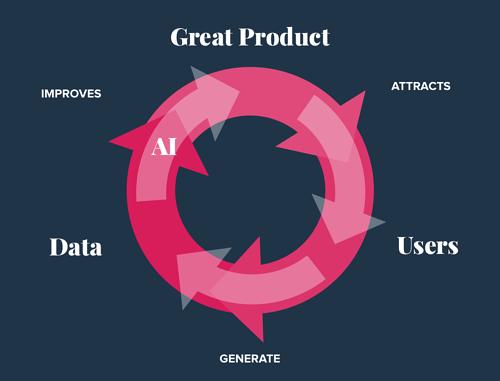
(5) 创建数据策略路线图。 数据是ML项目训练模型的关键资产。 根据人工智能领域的先驱Andrew Ng所说,最大,最成功的产品拥有最多的用户。 拥有最多的用户通常意味着您可以获得最多的数据,而对于现代ML,拥有最多的数据通常意味着您可以创建良好的AI。 下图描述了以上概念:
(6) 利用第三方软件。 不要试图彻底改变现状并建立内部数据管道。 为了成功启动AI,重要的是选择正确的工具,这些工具可以帮助您的组织完成在采购,抓取,标准化,优化和集成数据方面可以自动化的任务。 代表Alegion进行的Dimensional Research报告发现,最终,有71%的团队将培训数据和其他机器学习项目活动外包。 在"建造与购买"辩论中,选择"建造"的公司花费更多的时间和金钱。 请记住,您不是在雇用数据管理员,而是在雇用数据科学家。 采用DataOps工具并找到使数据生命周期的准备阶段和过程阶段自动化的方法,将会缩短洞察时间。
从来都不是容易的事,但不必那么难
一些企业没有足够的数据,另一些企业则在挣扎着十多年无法使用的价值。 拥有数据并不自动意味着可以从中获得见解。 组织无法识别从数据中获取见解所需的必要准备工作,因此,在创新和增长方面会出现越来越多的瓶颈。 不是没有数据,而是可用数据。
数据是创建预测性和智能解决方案的重要因素,但是数据不仅拥有很多,而且还有更多。 找到问题,找到合适的人来解决它,并为他们提供有效解决问题和衡量其效力所需的工具-这些是成功ML的要求。