













在学习PostgreSQL的过程中,很容易陷入一种情况,貌似都懂,一问就含糊,今天我就来捋一捋那团乱麻。
postgresql 启动源于守护进程,其功能强大,主管比如执行恢复、初始化共享数据结构/内存空间,以及启动强制和可选的进程。
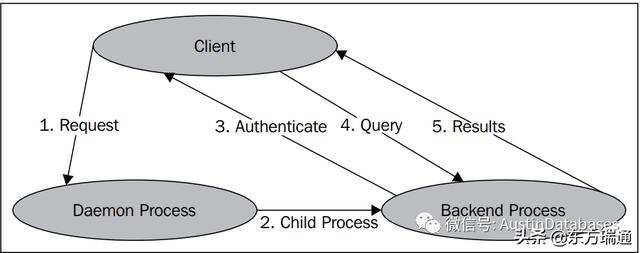
PostgreSql 在启动后,就开始接受客户的访问,下图演示了一个客户如何申请连接,由守护进程来分配一个子进程,然后来服务于客户的方式。
当有成千上万的用户要读取数据库中的数据,并且想更高速度度的读取,那就会牵扯到PG中的内存系统,PG的内存系统中,客户与backend process来进行交互,而backend process 会与PG的共享buffer中,而与其他数据库不同的地方是,PG的内存并不会和其他的三家的数据库一样,他要求的本身的buffer 的设置不会特别大(相对于其他三家的),他的设计中还要利用LINUX 系统的缓冲系统,在数据的读取上并不会引起任何问题,速度上也会有保障。
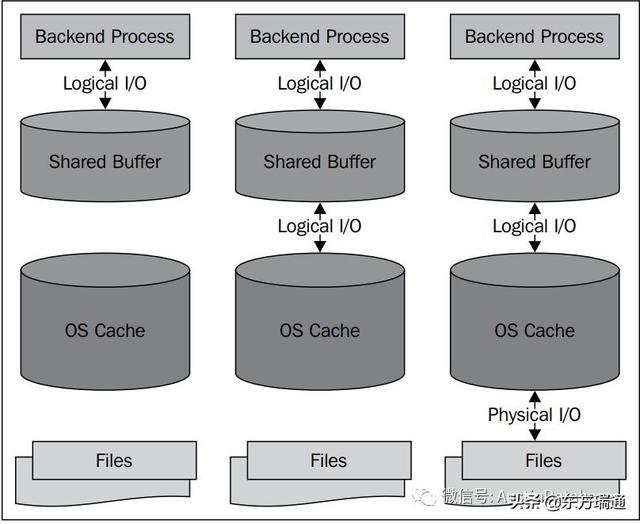
除了这两种级别的缓存之外,我们还可以使用磁盘控制器缓存、磁盘驱动器缓存等等。
上面基本上在关注与数据库的读操作,关于写操作中的一个问题就是大量数据的更改插入,数据是否马上会进行刷盘用户对表数据进行大量更改并发提交的情况下,不会马上对底层数据文件执行写操作。这可能只会导致确保提前写日志(WAL)文件与WAL缓冲区保持同步。那怎么来保证事务的持久性的问题和事务的原子性的问题,WAL 日志的重要的作用就是,保证系统的高性能下的AD功能,并让数据最终一致在数据文件中。
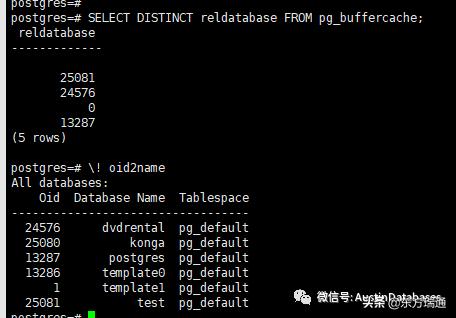
通过 buffercache 和 oid2name 两个命令可以看到目前的数据库的buffer到底有那些数据库已经在内存中。
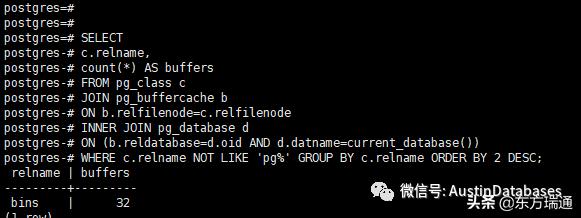
当然如果想关心一下,用户表的buffer读取的数据块的浮动可以将上的查询保存在一个表里面,并辅以时间,这样你就可以绘制出一个用户表的burfer的周期表。(能干什么自己想想,很有意思的)
- SELECT
- c.relname,
- count(*) AS buffers
- FROM pg_class c
- JOIN pg_buffercache b
- ON b.relfilenode=c.relfilenode
- INNER JOIN pg_database d
- ON (b.reldatabase=d.oid AND d.datname=current_database())
- WHERE c.relname NOT LIKE 'pg%' GROUP BY c.relname ORDER BY 2 DES
然后我们就到了内存与磁盘的交换,checkpoint,如
数据在内存中也不能一直寄存,需要落盘,这就牵扯到下一步checkpoint,检查点,检查点是一个强制的过程,在PG中数据总是以数据块写入和读取的,无论这个块的数据是否占满8K,读取的时候也是以块为单位进行读取,
用户在缓冲区中进行了更改,缓冲区与物理磁盘的数据文件不一致,该缓冲区的数据就是脏的,checkpoint的作用就是要将这些已经确认改变的数据写入到数据的文件的过程。相关的所有的数据页和索引页都会进行更新,同时将这个页面标记OK。
这样的方式可以让HEAP PAGE 和 INDEX PAGE 在这个checkpoint之前的页面都刷到磁盘的数据文件中。那么我可以理解的是,如果此时数据库没有任何的其他的手段,此时断电,那CHECKPOINT 之后的数据就会丢失(实际情况当然不会),这也就是redo,重做日志要检查checkpoint点的问题,他要确定从哪里开始重做
checkpoint 有三个参数,checkpoint_segments, checkpoint_timeout, 和checkpoint_completion_target.(PG 9X)
三个参数前两个属于凑够多少wal 才开始 checkpoint, 如果这个长时间没有checkpoint 那就根据第二个参数 checkpint_timeout 来根据时间来进行checkpoint,当然这样做的后果是,如果某个阶段数据量比较大,I/O就会出现消耗较高的情况,那第三个参数,checkpoint_completion_target就启动作用,让这个突发的情况,稍微的缓解,拉长这个写入的时间,让I/O系统不会那么的忙。
而当前PG11 中的与checkpoint的有关的参数不在有checkpoint_segments,换来的是max_wal_size ,要不超过设定时间去checkpoint 要不就是超过 max-wal-size 来进行 checkpoint,感觉这样设置比较合理,如果使用上面的方法,其实使用一个函数,就可以让PG的checkpoint紊乱,甚至可能会宕机(使坏的方法是就算了)
最后要在wal log 里面结束此次的捋一捋的活动。当我们对数据进行更改时,不会立即将更改写入数据文件,对缓冲区中的块进行更改,并将这些更改的记录写入WAL缓冲区,所以wal 才是保证系统运行效率与数据安全之间的一个妥协的产品。
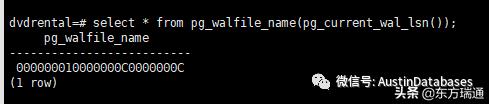
- select * from pg_walfile_name(pg_current_wal_lsn());
如何知道当前你正在操作的那个 wal 日志。(PG11)
- SELECT pg_xlogfile_name(pg_current_xlog_location()); (PG 9X)
使用过PG的人都知道PG 没有 DOUBLE WRITE 这个功能其实(DW是那个数据库的特征就不在说了),FULL PAGE 来支持的,到底FULL PAGE 是用了什么方法,躲避了 DW ,保证了数据的完全。当然这也是要消耗系统的I/O性能的,同时也可以通过细调某些参数来缓解某些性能问题。
在这之前我们说说为什么会有这样的情况,数据页如果是8KB的情况下,那硬件和系统能一次将这些信息都写到磁盘, 答案当然是 不 不 不
LINUX 一次是 4KB ,那硬件系统就更不知道是 4KB 还是 8KB ,所以如果系统CRASH 了,怎么办你明明写了8KB 人家写了 4KB 就断了,剩下了4KB 找谁,丢了,那启动后,物理页面损坏,谁给修,你给修。所以不同的数据库就各显神通,要把这块给弥补了。
PG 这里就是 FULL PAGE 主要是操作的是将PostgreSQL服务器会在检查点后第一次修改该页时将每个磁盘页的全部内容写入WAL。这样的好处是如果在下一次checkpoint的之前几期crash了,则我们在WAL 中有所有的数据页面,通过这些数据页面就可以将数据恢复。不好的地方就是将数据写入到了WAL日志中,多写数据是一定要影响性能的。
这里如果我们提高checkpoint的频率,会从逻辑的角度来抵消FULL page的影响,而如果缩小checkpoint的频率,那可能就会人为的创造出一个大的突发写入,那上边的一个参数就的调整了,那个参数呢,我想你已经知道了。
但结果是我不会关闭FULL PAGE 因为性能与数据的安全性比较,那个应该优先,不言而喻。
以上内容由东方瑞通资深讲师 Austin供稿,13年专业DBA经验,曾任互联网金融公司Senior DBA、500强制药企业Senior DBA,精通Mysql、PostgreSQL、Mongo DB、SQLServer。


















