老铁们,一年一度的520就要来了,大家有没有正在抓耳挠腮的给女朋友准备礼物呢?
作为一个业余非专业程序猿(ps:自称程序猿,哈哈),最近初学python,用它来抓取情话网站的100页情话,作为给女朋友的第二个小礼物。
由于小马达我,是自学,也是初学者,忘各位大神勿喷,程序比较简单,亲测可用。
下面进入正题:
目标:爬取指定网址的100页情话
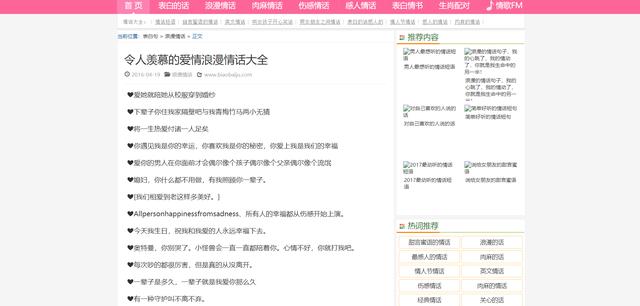
练手网站
准备:python:3.7版本、开发工具:pycharm、浏览器:谷歌浏览器
思路:
- 通过requests+xpath来爬取网页,并对信息进行提取
- 不管网站有没有反爬策略,最简单的携带headers用上
- 循环写入txt文件
- 把主要代码写成函数进行封装
几个关键点:
- 注意网页的编码格式,一般来说,可以结合response.encoding和response.headers来观察。如果headers里面没有Content-Type,则编码为encoding='utf-8';如果有Content-Type,以 charset 为准,没有charset,则为ISO-8859-1
- 观察网页的结构,确定如何编写程序实现翻页,在这里网站比较简单,直接把序号+1就行
- 关于用beautifulsoup还是xpath,酌情使用,在这里,我直接使用xpath定位更加方便
最终效果:
得到100页情话,并保存到txt文件里。
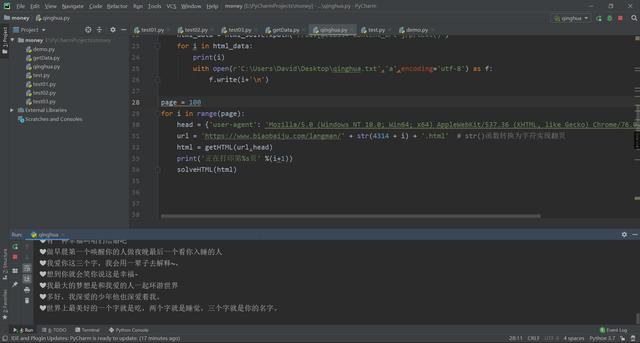
主要代码
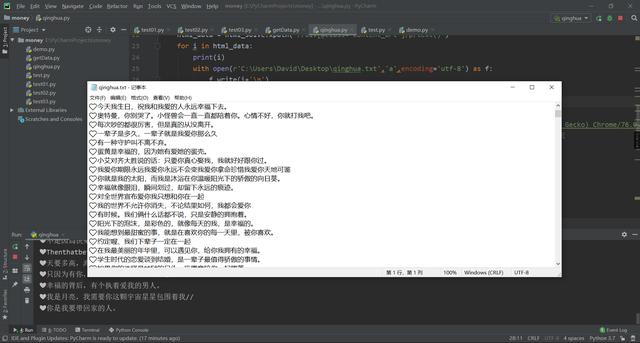
结果输出
后期计划改进:
- 准备把数据写入数据库
- 用flask框架搭建网站
- 准备实现词云效果,类似于下面这样。

好了,文字表达能力也不强,也不知道写啥,主要就是分享好玩的。奥,对了,小马达,什么都喜欢研究一下,这个号不打算写垂直领域,主要就是分享生活,结交朋友,当然了,你要点个赞,给个关注,那我们就是更好的朋友。哈哈,记得关注哦!