












批归一化(Batch Normalization)是深度学习领域的重大突破之一,也是近年来研究人员讨论的热门话题之一。批归一化是一种被广泛采用的技术,能够使训练更快、更稳定,并已成为深度学习领域很具影响力的方法之一。然而,它仍然存在一些要注意的问题。
为什么要使用批归一化?
什么是批归一化
在训练深度学习模型过程中,当我们更新之前的权重时,每个中间激活层的输出分布在每次迭代中都会发生变化。这种现象被称为内部协变移位(ICS)。为了防止这种情况的发生,就需要修正所有的分布。简单地说,如果遇到了一些分布移位的问题,我们应该不让它们移位,以帮助进行梯度优化并防止梯度消失,这将有助于我们的神经网络更快地训练。因此,减少这种ICS是驱动批归一化发展的关键原理。
它是怎么运行的
批归一化通过减去批次上的经验均值除以经验标准差来归一化前一个输出层的输出。这将有助于数据看起来像高斯分布。
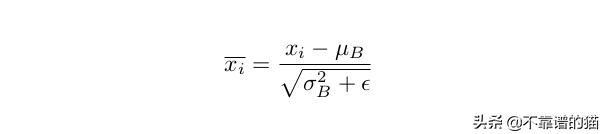
其中mu和sigma_square分别是batch均值和batch方差。
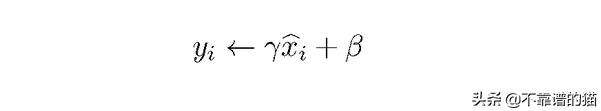
我们根据两个可学习的参数γ和β学习了新的均值和协方差。
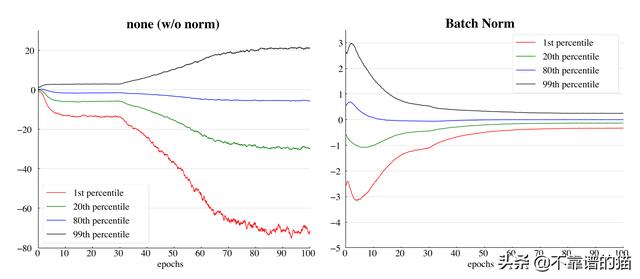
VGG-16网络的中间卷积层的特征分布输出
好处
我将列举使用批归一化的一些好处,但由于涉及到大量的文章,因此我不会赘述。
- 收敛更快。
- 降低了初始权重的重要性。
- 对超参数的鲁棒性。
- 泛化所需的数据更少。
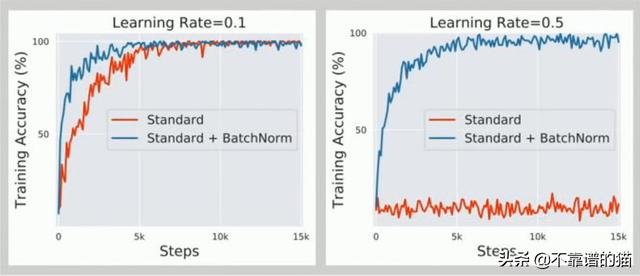
批归一化的问题
回到本文的动机,在许多情况下,批归一化可能会影响性能或者根本不起作用。
使用小的batch sizes时不稳定
如上所述,批归一化层必须计算均值和方差,以便对整个batch的前一个输出进行归一化。
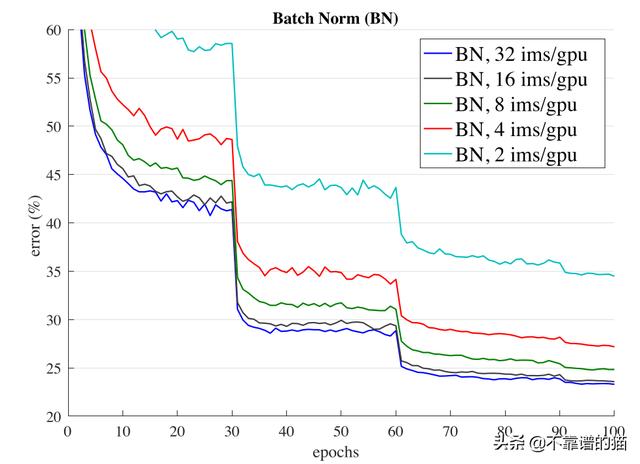
ResNet-50的批归一化验证误差
上面是ResNet-50的验证误差图。如果batch size保持为32,那么最终验证误差将在23左右,并且随着batch size的减小,误差会不断减小(batch size不能为1,因为它本身就是均值)。损失有很大的不同(大约10%)。
如果小batch size是一个问题,为什么我们不使用更大的batch size呢?实际上,我们不能在每种情况下都使用较大的batch size。在进行微调时,我们不能使用大的batch size,以避免使用大梯度伤害我们的模型。在分布式训练中,大的batch size最终将作为一组小的batch sizes分布在实例中。
会导致训练时间增加
NVIDIA和卡耐基梅隆大学进行的实验结果表明,“即使批归一化不占用大量计算资源,但收敛所需的总迭代次数却减少了。每次迭代的时间可能会显著增加”,并且随着batch size的增加,训练时间可能进一步增加。
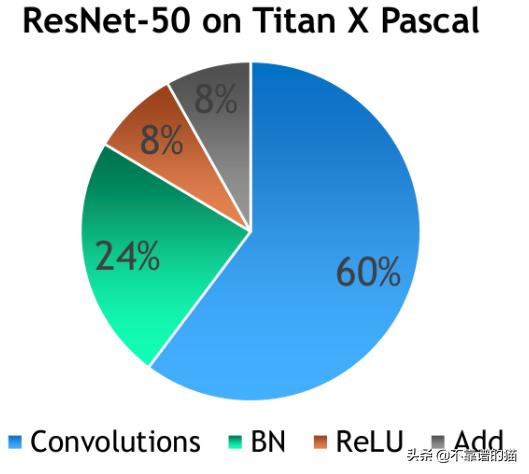
使用Titan X Pascal在ImageNet上的ResNet-50训练时间分布
如您所见,批归一化消耗了总训练时间的1/4。原因是因为批归一化要求对输入数据进行两次迭代:一次用于计算batch统计信息,另一次用于对输出进行归一化。
在测试/推断阶段不稳定
例如,考虑实际应用程序:“对象检测”。在训练对象检测器时,我们通常使用大的batch size(默认情况下,YOLOv4和Faster-RCNN都以batch size= 64进行训练)。但是在将这些深度学习模型投入生产后,这些模型并不像训练时那么有效。这是因为它们是用大的batch size进行训练的,而在实时情况下,它们得到的batch size等于1,因为它必须处理每一帧。如前所述,当使用batch size为1时,它本身就是均值,因此归一化层将无法有效地处理所谓的“内部协变移位”。
不利于在线学习
与batch学习相比,在线学习是一种学习技术,通过依次(或单独地,或通过称为mini-batches的small groups)向系统提供数据实例,对系统进行增量式训练。每一个学习步骤既快速又廉价,因此系统可以在新数据到达时动态地学习新数据。
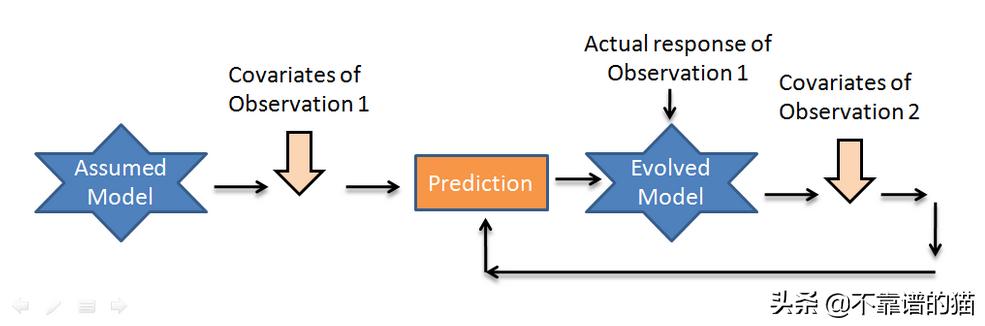
典型的在线学习管道
由于它依赖于外部数据源,数据可以单独到达,也可以成批到达。由于每次迭代中batch size的变化,它不能很好地概括输入数据的规模和shift,这最终会影响性能。
不适用于循环神经网络
在卷积神经网络中,尽管批归一化可以显著提高训练速度和泛化能力,但事实证明,它们很难应用于循环体系结构。批归一化可以应用于RNN的堆栈之间,其中归一化是“垂直”应用(即每个RNN的输出),但是它不能“水平”应用(即在时间步之间),因为重复的rescaling会导致梯度爆炸。
备选方案
在无法进行批归一化的情况下,可以使用以下几种替代方法:
- 层归一化。
- 实例归一化。
- 组归一化(+权重标准化)。
- 同步批归一化。
最后
批归一化尽管是深度学习开发中的一个里程碑技术,但是它仍会有一些问题,这表明归一化技术仍有改进的空间。


















