













如何恰当地提交代码,才能既保证研究的可复现性,又能扩大传播?近日,PapersWithCode 发布了机器学习代码完整性自查清单。目前,该清单已成为 NeurIPS 2020 代码提交流程的一部分。
可复现性是科学领域长期关注的话题,近期人工智能和机器学习社区也对此投入了更多关注。例如 ICML、ICLR 和 NeurIPS 这些顶级学术会议都在努力推进将实验代码和数据作为评审材料的一部分提交,并鼓励作者在评审或出版过程中提交代码以帮助结果可复现。
加拿大麦吉尔大学副教授、Facebook 蒙特利尔 FAIR 实验室负责人 Joelle Pineau 多次探讨该领域的可复现问题,并在去年底发布了可复现性检查清单。但是这份清单中的大部分内容与论文本身的构成有关,对于代码开源提供的指导较少。
最近,Papers with Code 联合创始人 Robert Stojnic 发布了一份机器学习代码完整性自查清单,或许可以帮助社区部分地解决这一难题。
Papers with Code 网站收集了大量论文实现集合和最佳实践。该团队对这些最佳实践进行了总结,得出一份机器学习代码完整性自查清单。目前该清单已成为 NeurIPS 2020 代码提交流程的一部分,并且将会提供给评审人员使用。
清单项目地址:https://github.com/paperswithcode/releasing-research-code
机器学习代码完整性自查清单
为鼓励复现性,帮助社区成员基于已发表工作更轻松地构建新的项目,Papers with Code 团队发布了机器学习完整性自查清单。
该清单基于脚本等评估代码库的完整性,共包含五大项:
- 依赖项
- 训练脚本
- 评估脚本
- 预训练模型
- 结果
该团队对 NeurIPS 2019 论文的官方 repo 进行分析后发现,代码完整性越高,项目的 GitHub 星数越多。
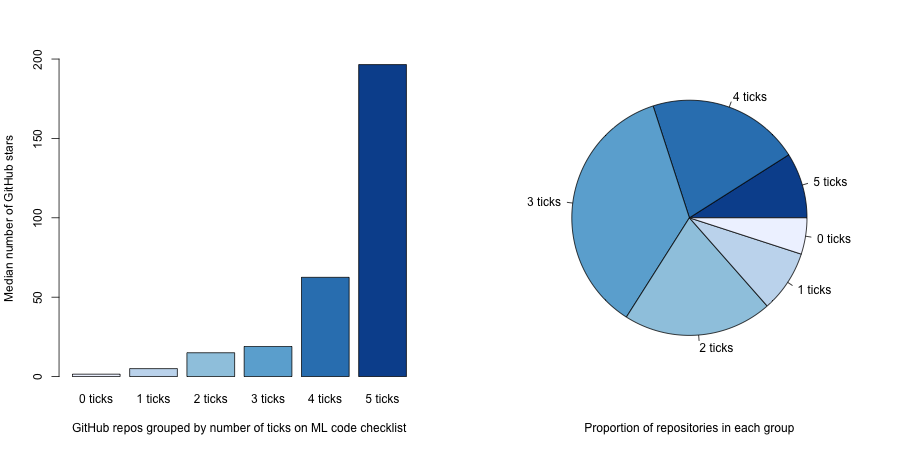
既然如此,我们赶快来看这五项的具体内容,并实施起来吧。
1. 依赖项
如果你用的语言是 Python,那么当使用 pip 和 virtualenv 时,你需要提供 requirements.txt 文件;当使用 anaconda 时,你需要提供 environment.yml 文件;当使用的是代码库时,你需要提供 setup.py。
在 README.md 中解释如何安装依赖项是一种很好的做法。假设用户具备极少的背景知识,编写 README 文件时尽量给出清晰完整的说明。因为如果用户无法设置好依赖项,那么他们大概率不会继续看你的代码。
如果想提供整体可复现的环境,你可以考虑使用 Docker,把环境的 Docker 镜像上传到 Dockerhub。
2. 训练脚本
代码应包含用来实现论文结果的训练脚本,也就是说你应该展示获得结果的过程中所使用的超参数和 trick。为了将效用最大化,理想情况下写代码时你的脑海中应当有一些扩展场景:如果用户也想在他们自己的数据集上使用相同的训练脚本呢?
你可以提供一个完备的命令行包装器(如 train.py)作为用户的切入点。
3. 评估脚本
模型评估和实验通常细节较多,在论文中常常无法得到详细地解释。这就是提交评估模型或运行实验的确切代码有助于完整描述流程的原因所在。而且,这也能帮助用户信任和理解你的研究。
你可以提供一个完备的命令行包装器(如 eval.py)作为用户的切入点。
4. 预训练模型
从头训练模型需要大量时间和成本。增加结果可信度的一种有效方法是提供预训练模型,使社区可以评估并获得最终结果。这意味着用户不用重新训练就能看到结果是可信的。
它还有一个用处,即有助于针对下游任务进行微调。发布预训练模型后,其他人能够将其应用于自己的数据集。
最后,有些用户可能想试验你的模型在某些样本数据上是否有效。提供预训练模型能够让用户了解你的研究并进行试验,从而理解论文的成果。
5. 结果
README 文件内应包括结果和能够复现这些结果的脚本。结果表格能让用户快速了解从这个 repo 中能够期待什么结果。
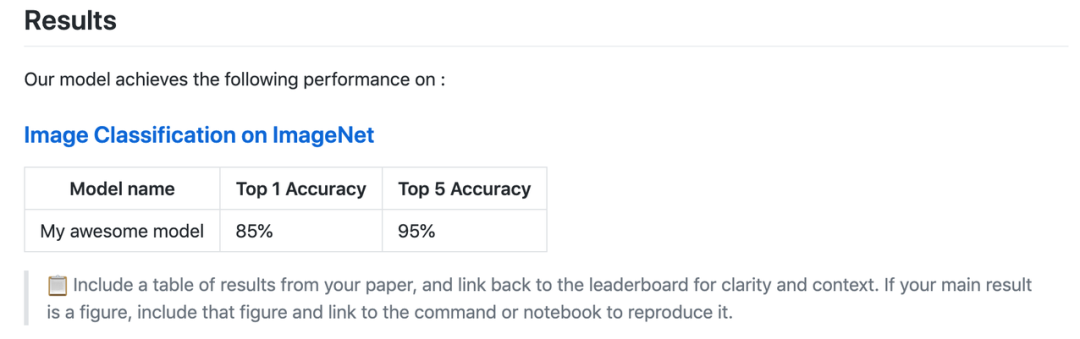
README.md 模板中的示例(模板地址:https://github.com/paperswithcode/releasing-research-code/blob/master/templates/README.md)
能够复现结果的指令给用户提供了另外一个切入点,能够直接促进可复现性。在一些情况下,论文的主要结果只有一张图,对于没有读过论文的用户,理解起来会很困难。
你还可以放置包含其他论文最新结果的完整排行榜链接,这有助于用户进一步理解你的研究结果。
具备代码完整性的项目示例
此外,该团队还提供了多个具备代码完整性的项目,以及有助于代码提交的额外资源。
NeurIPS 2019 项目示例
- https://github.com/kakaobrain/fast-autoaugment
- https://github.com/bknyaz/graph_attention_pool
- https://github.com/eth-sri/eran
- https://github.com/NVlabs/selfsupervised-denoising
- https://github.com/facebookresearch/FixRes
额外资源
预训练模型文件托管平台:
- Zenodo
- GitHub Releases
- Google Drive
- Dropbox
- AWS S3
模型文件管理工具:
- RClone
标准化模型界面:
- PyTorch Hub
- Tensorflow Hub
- Hugging Face NLP models
结果排行榜:
- Papers with Code leaderboards
- CodaLab
- NLP Progress
- EvalAI
- Weights & Biases - Benchmarks
制作项目页面工具:
- GitHub pages
- Fastpages
制作 demo 和教程工具:
- Google Colab
- Binder
- Streamlit

















