前言
小伙伴们肯定也比较好奇,Kafka 能够处理千万级消息,那它的消息是如何在 Partition 上存储的呢?今天这篇文章就来为大家揭秘消息是如何存储的。本文主要从消息的逻辑存储和物理存储两个角度来介绍其实现原理。
文章概览
- Partition、Replica、Log 和 LogSegment 的关系。
- 写入消息流程分析。
- 消费消息及副本同步流程分析。
Partition、Replica、Log 和 LogSegment 的关系
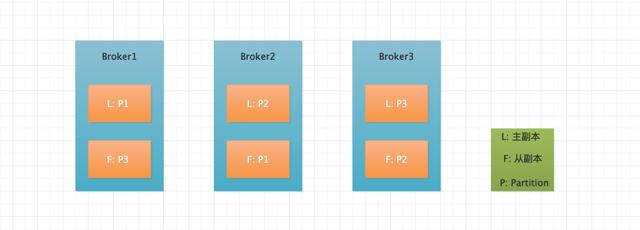
假设有一个 Kafka 集群,Broker 个数为 3,Topic 个数为 1,Partition 个数为 3,Replica 个数为 2。Partition 的物理分布如下图所示。
Partition分布图
从上图可以看出,该 Topic 由三个 Partition 构成,并且每个 Partition 由主从两个副本构成。每个 Partition 的主从副本分布在不同的 Broker 上,通过这点也可以看出,当某个 Broker 宕机时,可以将分布在其他 Broker 上的从副本设置为主副本,因为只有主副本对外提供读写请求,当然在最新的 2.x 版本中从副本也可以对外读请求了。将主从副本分布在不同的 Broker 上从而提高系统的可用性。
Partition 的实际物理存储是以 Log 文件的形式展示的,而每个 Log 文件又以多个 LogSegment 组成。Kafka 为什么要这么设计呢?其实原因比较简单,随着消息的不断写入,Log 文件肯定是越来越大,Kafka 为了方便管理,将一个大文件切割成一个一个的 LogSegment 来进行管理;每个 LogSegment 由数据文件和索引文件构成,数据文件是用来存储实际的消息内容,而索引文件是为了加快消息内容的读取。
可能又有朋友会问,Kafka 本身消费是以 Partition 维度顺序消费消息的,磁盘在顺序读的时候效率很高完全没有必要使用索引啊。其实 Kafka 为了满足一些特殊业务需求,比如要随机消费 Partition 中的消息,此时可以先通过索引文件快速定位到消息的实际存储位置,然后进行处理。
总结一下 Partition、Replica、Log 和 LogSegment 之间的关系。消息是以 Partition 维度进行管理的,为了提高系统的可用性,每个 Partition 都可以设置相应的 Replica 副本数,一般在创建 Topic 的时候同时指定 Replica 的个数;Partition 和 Replica 的实际物理存储形式是通过 Log 文件展现的,为了防止消息不断写入,导致 Log 文件大小持续增长,所以将 Log 切割成一个一个的 LogSegment 文件。
注意: 在同一时刻,每个主 Partition 中有且只有一个 LogSegment 被标识为可写入状态,当一个 LogSegment 文件大小超过一定大小后(比如当文件大小超过 1G,这个就类似于 HDFS 存储的数据文件,HDFS 中数据文件达到 128M 的时候就会被分出一个新的文件来存储数据),就会新创建一个 LogSegment 来继续接收新写入的消息。
写入消息流程分析
消息写入及落盘流程
流程解析
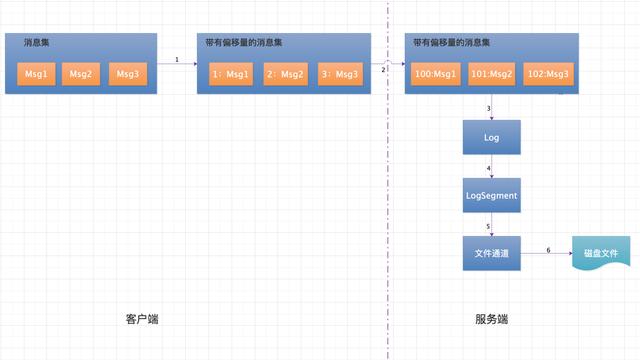
在第 3 篇文章讲过,生产者客户端对于每个 Partition 一次会发送一批消息到服务端,服务端收到一批消息后写入相应的 Partition 上。上图流程主要分为如下几步:
- 客户端消息收集器收集属于同一个分区的消息,并对每条消息设置一个偏移量,且每一批消息总是从 0 开始单调递增。比如第一次发送 3 条消息,则对三条消息依次编号 [0,1,2],第二次发送 4 条消息,则消息依次编号为 [0,1,2,3]。注意此处设置的消息偏移量是相对偏移量。
- 客户端将消息发送给服务端,服务端拿到下一条消息的绝对偏移量,将传到服务端的这批消息的相对偏移量修改成绝对偏移量。
- 将修改后的消息以追加的方式追加到当前活跃的 LogSegment 后面,然后更新绝对偏移量。
- 将消息集写入到文件通道。
- 文件通道将消息集 flush 到磁盘,完成消息的写入操作。
了解以上过程后,我们在来看看消息的具体构成情况。
消息构成细节图
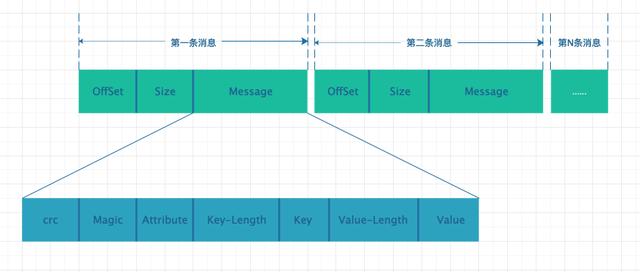
一条消息由如下三部分构成:
- OffSet:偏移量,消息在客户端发送前将相对偏移量存储到该位置,当消息存储到 LogSegment 前,先将其修改为绝对偏移量在写入磁盘。
- Size:本条 Message 的内容大小
- Message:消息的具体内容,其具体又由 7 部分组成,crc 用于校验消息,Attribute 代表了属性,key-length 和 value-length 分别代表 key 和 value 的长度,key 和 value 分别代表了其对应的内容。
消息偏移量的计算过程
通过以上流程可以看出,每条消息在被实际存储到磁盘时都会被分配一个绝对偏移量后才能被写入磁盘。在同一个分区内,消息的绝对偏移量都是从 0 开始,且单调递增;在不同分区内,消息的绝对偏移量是没有任何关系的。接下来讨论下消息的绝对偏移量的计算规则。
确定消息偏移量有两种方式,一种是顺序读取每一条消息来确定,此种方式代价比较大,实际上我们并不想知道消息的内容,而只是想知道消息的偏移量;第二种是读取每条消息的 Size 属性,然后计算出下一条消息的起始偏移量。比如第一条消息内容为 “abc”,写入磁盘后的偏移量为:8(OffSet)+ 4(Message 大小)+ 3(Message 内容的长度)= 15。第二条写入的消息内容为“defg”,其起始偏移量为 15,下一条消息的起始偏移量应该是:15+8+4+4=31,以此类推。
消费消息及副本同步流程分析
和写入消息流程不同,读取消息流程分为两种情况,分别是消费端消费消息和从副本(备份副本)同步主副本的消息。在开始分析读取流程之前,需要先明白几个用到的变量,不然流程分析可能会看的比较糊涂。
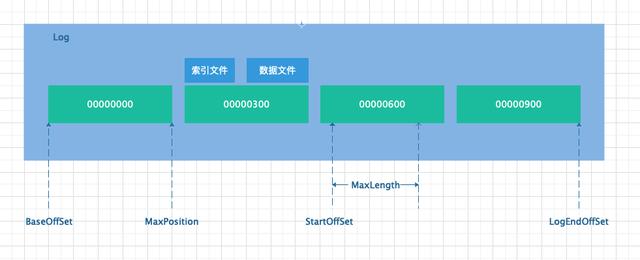
- BaseOffSet:基准偏移量,每个 Partition 由 N 个 LogSegment 组成,每个 LogSegment 都有基准偏移量,大概由如下构成,数组中每个数代表一个 LogSegment 的基准偏移量:[0,200,400,600, ...]。
- StartOffSet:起始偏移量,由消费端发起读取消息请求时,指定从哪个位置开始消费消息。
- MaxLength:拉取大小,由消费端发起读取消息请求时,指定本次最大拉取消息内容的数据大小。该参数可以通过max.partition.fetch.bytes来指定,默认大小为 1M。
- MaxOffSet:最大偏移量,消费端拉取消息时,最高可拉取消息的位置,即俗称的“高水位”。该参数由服务端指定,其作用是为了防止生产端还未写入的消息就被消费端进行消费。此参数对于从副本同步主副本不会用到。
- MaxPosition:LogSegment 的最大位置,确定了起始偏移量在某个 LogSegment 上开始,读取 MaxLength 后,不能超过 MaxPosition。MaxPosition 是一个实际的物理位置,而非偏移量。
假设消费端从 000000621 位置开始消费消息,关于几个变量的关系如下图所示。
位置关系图
消费端和从副本拉取流程如下:
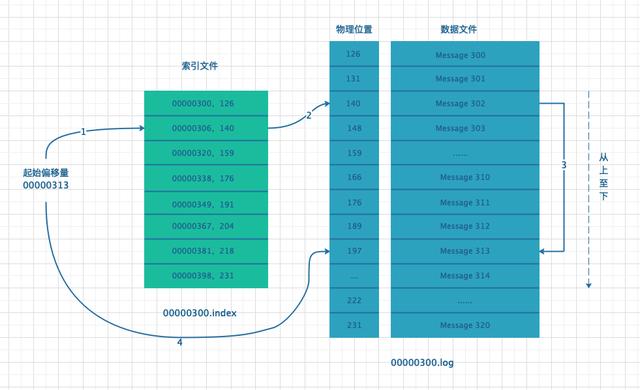
- 客户端确定拉取的位置,即 StartOffSet 的值,找到主副本对应的 LogSegment。
- LogSegment 由索引文件和数据文件构成,由于索引文件是从小到大排列的,首先从索引文件确定一个小于等于 StartOffSet 最近的索引位置。
- 根据索引位置找到对应的数据文件位置,由于数据文件也是从小到大排列的,从找到的数据文件位置顺序向后遍历,直到找到和 StartOffSet 相等的位置,即为消费或拉取消息的位置。
从 StartOffSet 开始向后拉取 MaxLength 大小的数据,返回给消费端或者从副本进行消费或备份操作。
假设拉取消息起始位置为 00000313,消息拉取流程图如下:
消息拉取流程图
总结
本文从逻辑存储和物理存储的角度,分析了消息的写入与消费流程。其中逻辑存储是以 Partition 来管理一批一批的消息,Partition 映射 Log 对象,Log 对象管理了多个 LogSegment,多个 Partition 构成了一个完整的 Topic。消息的实际物理存储是由一个一个的 LogSegment 构成,每个 LogSegment 又由索引文件和数据文件构成。