说到当前的深度学习框架,我们往往绕不开 TensorFlow 和 PyTorch。但除了这两个框架,一些新生力量也不容小觑,其中之一便是 JAX。它具有正向和反向自动微分功能,非常擅长计算高阶导数。这一崭露头角的框架究竟有多好用?怎样用它来展示神经网络内部复杂的梯度更新和反向传播?本文是一个教程贴,教你理解 Jax 的底层逻辑,让你更轻松地从 PyTorch 等进行迁移。
Jax 是谷歌开发的一个 Python 库,用于机器学习和数学计算。一经推出,Jax 便将其定义为一个 Python+NumPy 的程序包。它有着可以进行微分、向量化,在 TPU 和 GPU 上采用 JIT 语言等特性。简而言之,这就是 GPU 版本的 numpy,还可以进行自动微分。甚至一些研究者,如 Skye Wanderman-Milne,在去年的 NeurlPS 2019 大会上就介绍了 Jax。
但是,要让开发者从已经很熟悉的 PyTorch 或 TensorFlow 2.X 转移到 Jax 上,无疑是一个很大的改变:这两者在构建计算和反向传播的方式上有着本质的不同。PyTorch 构建一个计算图,并计算前向和反向传播过程。结果节点上的梯度是由中间节点的梯度累计而成的。
Jax 则不同,它让你用 Python 函数来表达计算过程,并用 grad( ) 将其转换为一个梯度函数,从而让你能够进行评价。但是它并不给出结果,而是给出结果的梯度。两者的对比如下所示:
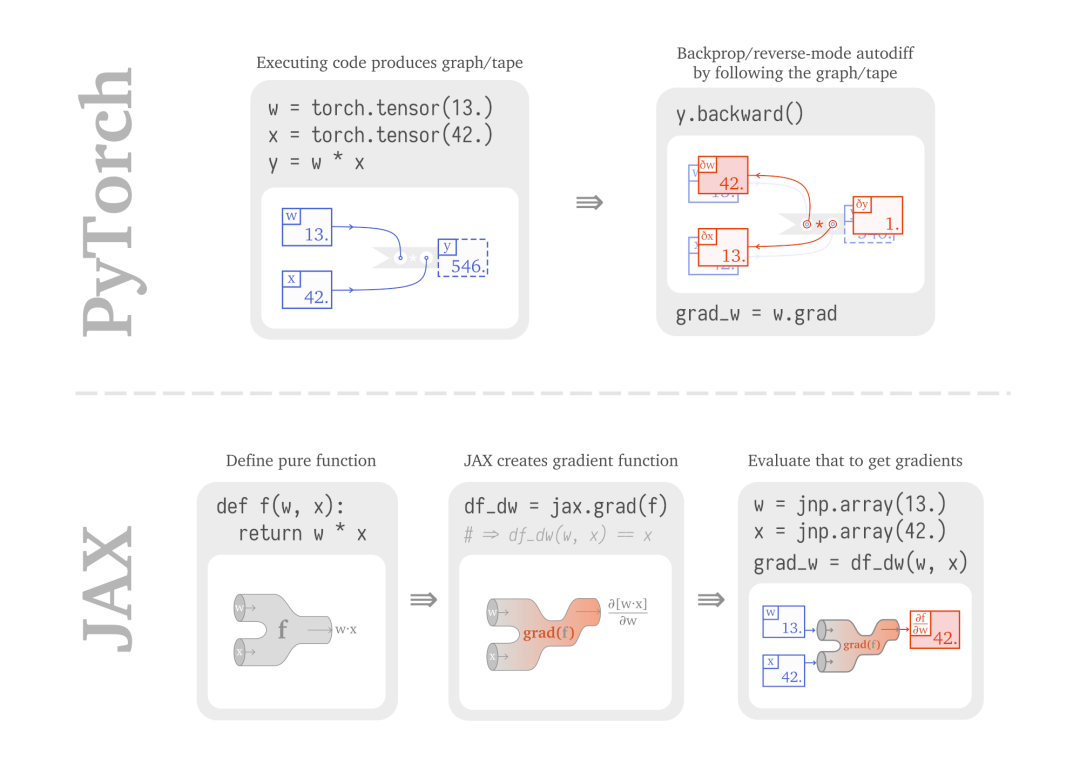
这样一来,你进行编程和构建模型的方式就不一样了。所以你可以使用 tape-based 的自动微分方法,并使用有状态的对象。但是 Jax 可能让你感到很吃惊,因为运行 grad() 函数的时候,它让微分过程如同函数一样。
也许你已经决定看看如 flax、trax 或 haiku 这些基于 Jax 的工具。在看 ResNet 等例子时,你会发现它和其他框架中的代码不一样。除了定义层、运行训练外,底层的逻辑是什么样的?这些小小的 numpy 程序是如何训练了一个巨大的架构?
本文便是介绍 Jax 构建模型的教程,机器之心节选了其中的两个部分:
- 快速回顾 PyTorch 上的 LSTM-LM 应用;
- 看看 PyTorch 风格的代码(基于 mutate 状态),并了解纯函数是如何构建模型的(Jax);
PyTorch 上的 LSTM 语言模型
我们首先用 PyTorch 实现 LSTM 语言模型,如下为代码:
- import torch
- class LSTMCell(torch.nn.Module):
- def __init__(self, in_dim, out_dim):
- super(LSTMCell, self).__init__()
- self.weight_ih = torch.nn.Parameter(torch.rand(4*out_dim, in_dim))
- self.weight_hh = torch.nn.Parameter(torch.rand(4*out_dim, out_dim))
- self.bias = torch.nn.Parameter(torch.zeros(4*out_dim,))
- def forward(self, inputs, h, c):
- ifgo = self.weight_ih @ inputs + self.weight_hh @ h + self.bias
- i, f, g, o = torch.chunk(ifgo, 4)
- i = torch.sigmoid(i)
- f = torch.sigmoid(f)
- g = torch.tanh(g)
- o = torch.sigmoid(o)
- new_c = f * c + i * g
- new_h = o * torch.tanh(new_c)
- return (new_h, new_c)
然后,我们基于这个 LSTM 神经元构建一个单层的网络。这里会有一个嵌入层,它和可学习的 (h,c)0 会展示单个参数如何改变。
- class LSTMLM(torch.nn.Module):
- def __init__(self, vocab_size, dim=17):
- super().__init__()
- self.cell = LSTMCell(dim, dim)
- self.embeddings = torch.nn.Parameter(torch.rand(vocab_size, dim))
- self.c_0 = torch.nn.Parameter(torch.zeros(dim))
- @property
- def hc_0(self):
- return (torch.tanh(self.c_0), self.c_0)
- def forward(self, seq, hc):
- loss = torch.tensor(0.)
- for idx in seq:
- loss -= torch.log_softmax(self.embeddings @ hc[0], dim=-1)[idx]
- hc = self.cell(self.embeddings[idx,:], *hc)
- return loss, hc
- def greedy_argmax(self, hc, length=6):
- with torch.no_grad():
- idxs = []
- for i in range(length):
- idx = torch.argmax(self.embeddings @ hc[0])
- idxs.append(idx.item())
- hc = self.cell(self.embeddings[idx,:], *hc)
- return idxs
构建后,进行训练:
- torch.manual_seed(0)
- # As training data, we will have indices of words/wordpieces/characters,
- # we just assume they are tokenized and integerized (toy example obviously).
- import jax.numpy as jnp
- vocab_size = 43 # prime trick! :)
- training_data = jnp.array([4, 8, 15, 16, 23, 42])
- lm = LSTMLM(vocab_sizevocab_size=vocab_size)
- print("Sample before:", lm.greedy_argmax(lm.hc_0))
- bptt_length = 3 # to illustrate hc.detach-ing
- for epoch in range(101):
- hc = lm.hc_0
- totalloss = 0.
- for start in range(0, len(training_data), bptt_length):
- batch = training_data[start:start+bptt_length]
- loss, (h, c) = lm(batch, hc)
- hc = (h.detach(), c.detach())
- if epoch % 50 == 0:
- totalloss += loss.item()
- loss.backward()
- for name, param in lm.named_parameters():
- if param.grad is not None:
- param.data -= 0.1 * param.grad
- del param.grad
- if totalloss:
- print("Loss:", totalloss)
- print("Sample after:", lm.greedy_argmax(lm.hc_0))
- Sample before: [42, 34, 34, 34, 34, 34]
- Loss: 25.953862190246582
- Loss: 3.7642268538475037
- Loss: 1.9537211656570435
- Sample after: [4, 8, 15, 16, 23, 42]
可以看到,PyTorch 的代码已经比较清楚了,但是还是有些问题。尽管我非常注意,但是还是要关注计算图中的节点数量。那些中间节点需要在正确的时间被清除。
纯函数
为了理解 JAX 如何处理这一问题,我们首先需要理解纯函数的概念。如果你之前做过函数式编程,那你可能对以下概念比较熟悉:纯函数就像数学中的函数或公式。它定义了如何从某些输入值获得输出值。重要的是,它没有「副作用」,即函数的任何部分都不会访问或改变任何全局状态。
我们在 Pytorch 中写代码时充满了中间变量或状态,而且这些状态经常会改变,这使得推理和优化工作变得非常棘手。因此,JAX 选择将程序员限制在纯函数的范围内,不让上述情况发生。
在深入了解 JAX 之前,可以先看几个纯函数的例子。纯函数必须满足以下条件:
- 你在什么情况下执行函数、何时执行函数应该不影响输出——只要输入不变,输出也应该不变;
- 无论我们将函数执行了 0 次、1 次还是多次,事后应该都是无法辨别的。
以下非纯函数都至少违背了上述条件中的一条:
- import random
- import time
- nr_executions = 0
- def pure_fn_1(x):
- return 2 * x
- def pure_fn_2(xs):
- ys = []
- for x in xs:
- # Mutating stateful variables *inside* the function is fine!
- ys.append(2 * x)
- return ys
- def impure_fn_1(xs):
- # Mutating arguments has lasting consequences outside the function! :(
- xs.append(sum(xs))
- return xs
- def impure_fn_2(x):
- # Very obviously mutating
- global state is bad... global
- nr_executions nr_executions += 1
- return 2 * x
- def impure_fn_3(x):
- # ...but just accessing it is, too, because now the function depends on the
- # execution context!
- return nr_executions * x
- def impure_fn_4(x):
- # Things like IO are classic examples of impurity.
- # All three of the following lines are violations of purity:
- print("Hello!")
- user_input = input()
- execution_time = time.time()
- return 2 * x
- def impure_fn_5(x):
- # Which constraint does this violate? Both, actually! You access the current
- # state of randomness *and* advance the number generator!
- p = random.random()
- return p * x
- Let's see a pure function that JAX operates on: the example from the intro figure.
- # (almost) 1-D linear regression
- def f(w, x):
- return w * x
- print(f(13., 42.))
- 546.0
目前为止还没有出现什么状况。JAX 现在允许你将下列函数转换为另一个函数,不是返回结果,而是返回函数结果针对函数第一个参数的梯度。
- import jax
- import jax.numpy as jnp
- # Gradient: with respect to weights! JAX uses the first argument by default.
- df_dw = jax.grad(f)
- def manual_df_dw(w, x):
- return x
- assert df_dw(13., 42.) == manual_df_dw(13., 42.)
- print(df_dw(13., 42.))
- 42.0
到目前为止,前面的所有内容你大概都在 JAX 的 README 文档见过,内容也很合理。但怎么跳转到类似 PyTorch 代码里的那种大模块呢?
首先,我们来添加一个偏置项,并尝试将一维线性回归变量包装成一个我们习惯使用的对象——一种线性回归「层」(LinearRegressor「layer」):
- class LinearRegressor():
- def __init__(self, w, b):
- self.w = w
- self.b = b
- def predict(self, x):
- return self.w * x + self.b
- def rms(self, xs: jnp.ndarray, ys: jnp.ndarray):
- return jnp.sqrt(jnp.sum(jnp.square(self.w * xs + self.b - ys)))
- my_regressor = LinearRegressor(13., 0.)
- # A kind of loss fuction, used for training
- xs = jnp.array([42.0])
- ys = jnp.array([500.0])
- print(my_regressor.rms(xs, ys))
- # Prediction for test data
- print(my_regressor.predict(42.))
- 46.0
- 546.0
接下来要怎么利用梯度进行训练呢?我们需要一个纯函数,它将我们的模型权重作为函数的输入参数,可能会像这样:
- def loss_fn(w, b, xs, ys):
- my_regressor = LinearRegressor(w, b)
- return my_regressor.rms(xsxs=xs, ysys=ys)
- # We use argnums=(0, 1) to tell JAX to give us
- # gradients wrt first and second parameter.
- grad_fn = jax.grad(loss_fn, argnums=(0, 1))
- print(loss_fn(13., 0., xs, ys))
- print(grad_fn(13., 0., xs, ys))
- 46.0
- (DeviceArray(42., dtype=float32), DeviceArray(1., dtype=float32))
你要说服自己这是对的。现在,这是可行的,但显然,在 loss_fn 的定义部分枚举所有参数是不可行的。
幸运的是,JAX 不仅可以对标量、向量、矩阵进行微分,还能对许多类似树的数据结构进行微分。这种结构被称为 pytree,包括 python dicts:
- def loss_fn(params, xs, ys):
- my_regressor = LinearRegressor(params['w'], params['b'])
- return my_regressor.rms(xsxs=xs, ysys=ys)
- grad_fn = jax.grad(loss_fn)
- print(loss_fn({'w': 13., 'b': 0.}, xs, ys))
- print(grad_fn({'w': 13., 'b': 0.}, xs, ys))
- 46.0
- {'b': DeviceArray(1., dtype=float32), 'w': DeviceArray(42., dtype=float32)}So this already looks nicer! We could write a training loop like this:
现在看起来好多了!我们可以写一个下面这样的训练循环:
- params = {'w': 13., 'b': 0.}
- for _ in range(15):
- print(loss_fn(params, xs, ys))
- grads = grad_fn(params, xs, ys)
- for name in params.keys():
- params[name] -= 0.002 * grads[name]
- # Now, predict:
- LinearRegressor(params['w'], params['b']).predict(42.)
- 46.0
- 42.47003
- 38.940002
- 35.410034
- 31.880066
- 28.350098
- 24.820068
- 21.2901
- 17.760132
- 14.230164
- 10.700165
- 7.170166
- 3.6401978
- 0.110198975
- 3.4197998
- DeviceArray(500.1102, dtype=float32)
注意,现在已经可以使用更多的 JAX helper 来进行自我更新:由于参数和梯度拥有共同的(类似树的)结构,我们可以想象将它们置于顶端,创造一个新树,其值在任何地方都是这两个树的「组合」,如下所示:
- def update_combiner(param, grad, lr=0.002):
- return param - lr * grad
- params = jax.tree_multimap(update_combiner, params, grads)
- # instead of:
- # for name in params.keys():
- # params[name] -= 0.1 * grads[name]
参考链接:https://sjmielke.com/jax-purify.htm
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】