使您的Apache Spark应用程序运行速度更快,而对代码的更改最少!
介绍
在开发Spark应用程序时,最耗时的部分之一是优化。 在此博客文章中,我将提供一些性能提示,以及(至少对我而言)启动时可能会使用的未知配置参数。
因此,我将介绍以下主题:
- 多个小文件作为源
- 随机分区参数
- 强制广播Join
- 分区vs合并vs随机分区参数设置
我们可以改善什么?
1. 使用多个小文件?
OpenCostInBytes(来自文档)—可以同时扫描打开文件的估计成本(以字节数衡量)。 将多个文件放入分区时使用。 最好高估一下,然后,具有较小文件的分区将比具有较大文件的分区(首先安排)更快。 默认值为4MB。
spark.conf.set("spark.files.openCostInBytes", SOME_COST_IN_BYTES)
我对包含12,000个文件的1GB文件夹,包含800个文件的7.8GB文件夹和包含1.6k个文件的18GB文件夹进行了测试。 我的目的是弄清楚输入文件是否较小,最好使用低于默认值的文件。
因此,当测试1GB和7.8GB文件夹时-肯定是较低的值,但是测试大约11MB的文件时,较大的参数值会更好。
使用接近您的小文件大小的openCostInBytes大小。 这样会更有效率!
2. 随机分区
开始使用Spark时,我莫名其妙地想到了在创建Spark会话时设置的配置是不可变的。 天哪,我怎么错。
因此,通常,在进行聚集或联接时,spark分区在spark中是一个静态数字(默认为200)。 根据您的数据大小,这会导致两个问题:
- 数据集很小-200太多,数据分散且效率不高
- 数据集巨大-200太少了。 数据被浪费了,我们没有充分利用我们想要的所有资源。
因此,在遇到此类问题时遇到了一些麻烦,我在Google上花费了很多时间,发现了这个美丽的东西
- spark.conf.set("spark.sql.shuffle.partitions", X)
可以在运行时中途随时随地更改此整洁的配置,它会影响设置后触发的步骤。 您也可以在创建Spark会话时使用这个坏男孩。 在对联接或聚合进行数据混排时,将使用此分区数量。 还获得数据帧分区计数:
- df.rdd.getNumPartitions()
您可以估计最合适的混搭分区数,以进行进一步的联接和聚合。
也就是说,您有一个巨大的数据框,并且想要保留一些信息。 这样就得到了大数据帧的分区数。 将shuffle分区参数设置为此值。 这样一来,加入后就不会成为默认值200! 更多并行性-我们来了!
3. 广播Join
非常简单的情况:我们有一个庞大的表,其中包含所有用户,而我们的表中包含内部用户,质量检查人员和其他不应包含在内的用户。 目标只是离开非内部人员。
- 读两个表
- Huge_table 左防联接小表
它看起来像是一个简单且性能明智的好解决方案。 如果您的小型表小于10MB,则您的小型数据集将在没有任何提示的情况下进行广播。 如果在代码中添加提示,则可能会使它在更大的数据集上运行,但这取决于优化程序的行为。
但是,假设它是100-200MB,并且提示您不要强制广播它。 因此,如果您确信它不会影响代码的性能(或引发一些OOM错误),则可以使用它并覆盖默认值:
- spark.conf.set("spark.sql.autoBroadcastJoinThreshold", SIZE_OF_SMALLER_DATASET)
在这种情况下,它将广播给所有执行者,并且加入应该工作得更快。
当心OOM错误!
4. 分区vs合并vs随机分区配置设置
如果您使用的是Spark,则可能知道重新分区方法。 对我来说,来自SQL后台方法合并的方式有不同的含义! 显然,在分区上进行火花合并时,其行为方式有所不同-它移动并将多个分区组合在一起。 基本上,我们将数据改组和移动减到最少。
如果我们只需要减少分区数,则应该使用合并而不是重新分区,因为这样可以最大程度地减少数据移动并且不会触发交换。 如果我们想更均匀地在分区之间划分数据,请重新分区。
但是,假设我们有一个重复出现的模式,我们执行联接/转换并得到200个分区,但是我们不需要200个分区,即100个甚至1个。
让我们尝试进行比较。 我们将读取11MB的文件夹,并像以前一样进行汇总。
通过将数据帧持久存储在仅存储选件磁盘上,我们可以估计数据帧大小。 所以small_df只有10 MB,但是分区数是200。等等? 平均每个分区可提供50KB的数据,这效率不高。 因此,我们将读取大数据帧,并将聚合后的分区计数设置为1,并强制Spark执行,最后我们将其算作一项操作。
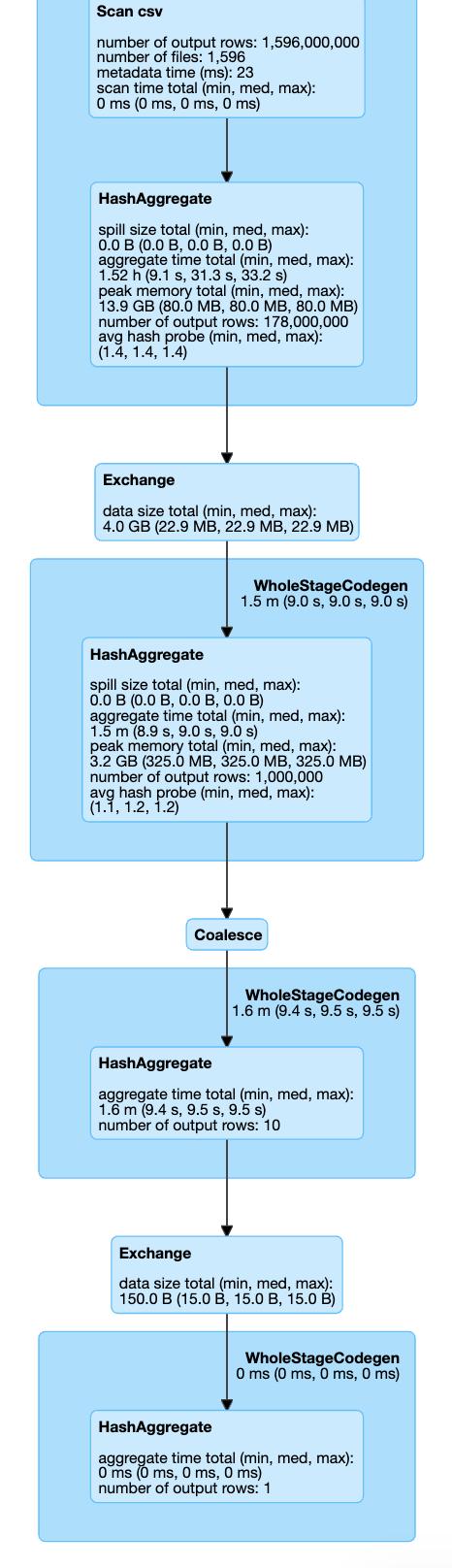
这是我们三种情况的执行计划:
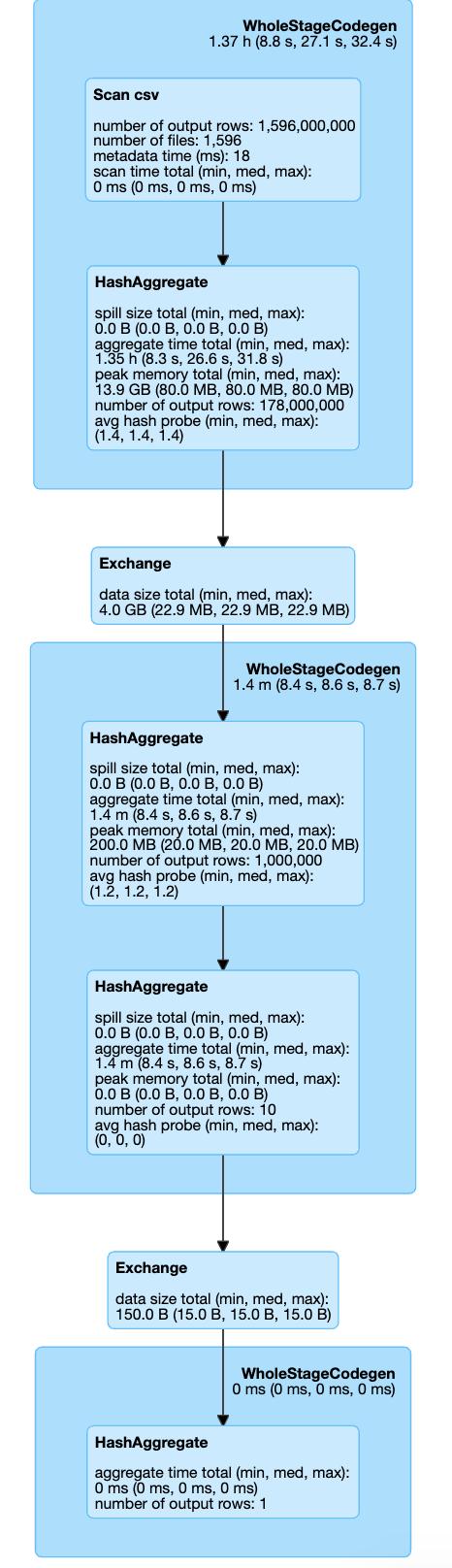
> Setting shuffle partition parameter
> Coalesce action
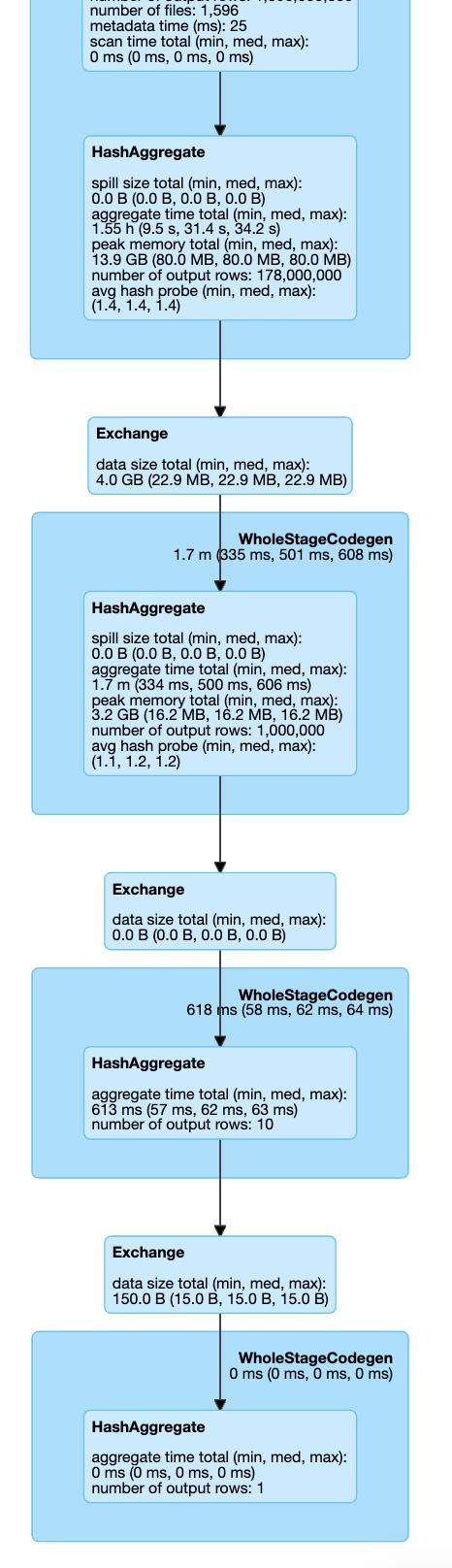
> Repartitioning
因此,在所有可见的设置中,我们不会调用Coalesce / Exchange的其他步骤(重新分区操作)。 因此,我们可以通过跳过它来节省一些执行时间。 如果我们看一下执行时间:Shuffle Partition设置在7.1分钟,Coalesce 8.1,Repartition 8.3中完成。
这只是一个简单的示例,它仍然显示了通过设置一个配置参数可以节省多少时间!
摘要
关于如何使您的Apache Spark应用程序更快,更高效地运行,有许多小而简单的技巧和窍门。 不幸的是,使用Spark时,大多数情况下解决方案都是单独的。 为了使其正常工作,大多数时候您必须了解Spark内部组件的内幕,并从头到尾阅读文档多次。
在本文中,我提到了如何更快地读取多个小文件,如何强制建议广播连接,选择何时使用shuffle分区参数,合并和重新分区。
我希望它很有用,并会在您开发Apache Spark应用程序的过程中为您提供帮助!