01.分区表性能
PostgreSQL 对分区表的支持由来已久。在 10.0 之前,分区表需要用户通过继承的方式手动创建,从 10.0 开始支持声明式分区,即通过 SQL 直接创建分区表,改善了分区表的易用性;在 11 中,支持 HASH 分区,并在计划和执行阶段,增强分区裁剪策略,提升分区表查询性能;PostgreSQL 12 进一步增强了分区表的查询和数据导入性能,尤其对分区数量多的场景,查询优化效果尤为显著。
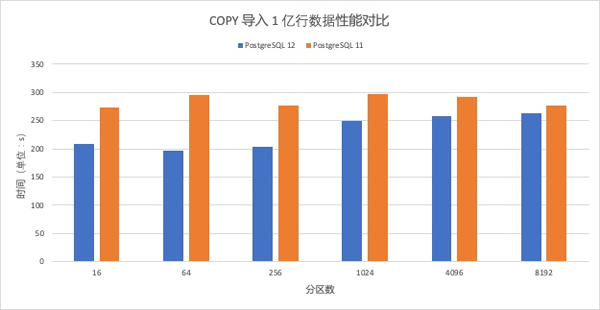
在阿里云创建两个同等规格(4c8g)的 RDS PostgreSQL 11 和 12 的实例,测试不同分区数情况下,使用 COPY 导入 1 亿行数据的性能对比如下。可见,随着分区数增多,导入性能始终优于 PostgreSQL 11。COPY 导入数据的性能提升得益于在 12 中支持了分区表批量插入,在次之前,仅支持一次一行的插入模式。
对于查询操作,在 PostgreSQL 10 中,会依次检查每个分区表,判断其可能有满足条件的数据,每个分区表的处理与普通表的处理流程类似;PostgreSQL 11 引入了分区裁剪特性,可以更早地定位需要访问的分区;PostgreSQL 12 则近一步将分区裁剪功能前置,避免为每个分区加载元数据并生成相应的内部结构,使得查询计划耗时进一步与无关的分区解耦。
由此可见,该优化与查询条件的分区过滤性相关,分区过滤性越好,所需处理的分区越少,优化效果越好。
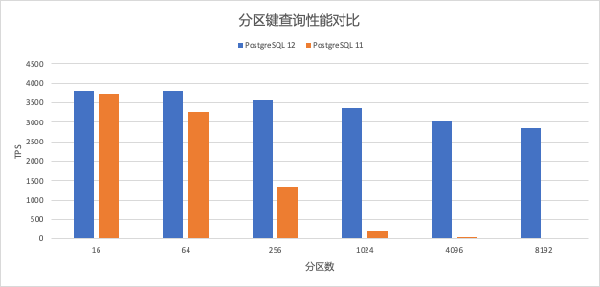
不同分区数下,分区键(同时也是主键)上的查询性能对比如下。可见,分区数越多,PostgreSQL 12 的性能提升越明显,最高提升达 150 倍。而随着分区数增加,PostgreSQL 12 的性能则保持相对稳定。
虽然分区表性能有大幅提升,但与单表相比,在很多场景下性能还有一定差距,在做表结构设计时,仍然需要结合实际业务场景,选择是否分区以及分区数量。
02.索引增强
B-tree 索引被广泛应用于数据库系统中,可以有效减少查询需要访问的数据量,提升查询性能。索引是一种 "空间换时间" 的查询优化策略,本身也会占用一些存储空间,其性能对查询也至关重要。
PostgreSQL 12 提升了标准 B-tree 的整体性能,减少了磁盘空间占用,对于复合索引,其空间使用率最多可减少 40%,可以有效节省用户的磁盘空间;对于有重复项的 B-tree 索引,其性能也有所提升。另外,引入 REINDEX CONCURRENTLY 命令,用户可以在业务无感知的情况下重建索引。
我们通过测试直观感受一下 B-tree 索引的空间占用优化。分别在 PostgreSQL 11 和 12 中创建如下表和索引,并插入 2000 万行数据,VACUUM 更新统计信息。
*请左右滑动阅览
CREATE TABLE foo (
aid bigint NOT NULL,
bid bigint NOT NULL
);
ALTER TABLE foo
ADD CONSTRAINT foo_pkey PRIMARY KEY (aid, bid);
CREATE INDEX foo_bid_idx ON foo(bid);
INSERT INTO foo (aid, bid)
SELECT i, i / 10000
FROM generate_series(1, 20000000) AS i;
VACUUM (ANALYZE) foo;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
分别查看两个 PostgreSQL 版本中 foo_bid_idx 索引的大小,如下:
*请左右滑动阅览
# PostgreSQL 11
postgres=> \di+ foo_bid_idx
List of relations
Schema | Name | Type | Owner | Table | Persistence | Size | Description
--------+-------------+-------+-------------+-------+-------------+--------+-------------
public | foo_bid_idx | index | postgres | foo | permanent | 544 MB |
(1 row)
# PostgreSQL 12
postgres=> \di+ foo_bid_idx
List of relations
Schema | Name | Type | Owner | Table | Persistence | Size | Description
--------+-------------+-------+-------------+-------+-------------+--------+-------------
public | foo_bid_idx | index | postgres | foo | permanent | 408 MB |
(1 row)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
可见,PostgreSQL 11 的索引比 PostgreSQL 12 大 33%,在索引较多的场景下,如此大幅度的空间节省还是很可观的。
除 B-tree 索引外,其他索引也有增强。如减小生成 GiST、GIN 和 SP-GiST 索引的WAL日志的开销,支持用 GiST 创建覆盖索引,支持用 SP-GiST 索引的 distance 运算符执行 K-NN 查询等。
03.支持 SQL/JSON 路径语言(path language)
PostgreSQL 在之前的版本中就已经支持了 JSON 数据类型,并支持对简单 JSON 数据的查询操作,如果 JSON 数据比较复杂,如嵌套较多,包含数组等,则不能便捷地查询其中的值,往往需要依赖外部插件来实现,比如支持 SQL/JSON 路径语言 的 jsquery 插件。
PostgreSQL 12 对非结构化数据的支持再进一步。内置支持了 SQL 2016 标准引入的 JSON 特性和丰富的路径查询方法,引入新的数据类型 jsonpath 表示路径表达式(path expression),支持 JSON 上的各种复杂查询,不再依赖插件。具体的使用方法可以参考文档,在此不赘述。
04.参数控制 Prepared 计划
对于重复执行的 PREPARE 语句,PostgreSQL 会缓存其执行计划,执行 PREPARE 语句时,PostgreSQL 会自动选择是重新生成一个新的计划(通常称之为定制计划,custom plan),还是使用缓存的计划(即通用计划,generic plan),但在特定场景下,数据库的选择可能并不是最优的。PostgreSQL 12 为用户提供了一个参数 plan_cache_mode 来自主选择使用哪种计划,比如查询的参数如果总是固定的常量,则可以显式设置该参数,使优化器总是使用通用计划,避免 SQL 解析和重写的代价,从而优化查询性能。
执行PREPARE 并运行,前 5 次均使用定制计划:
*请左右滑动阅览
postgres=> prepare p(integer) as select aid from foo where aid=$1;
PREPARE
postgres=> EXPLAIN EXECUTE p(1);
QUERY PLAN
-------------------------------------------------------------------------
Index Only Scan using foo_pkey on foo (cost=0.44..1.56 rows=1 width=8)
Index Cond: (aid = 1)
(2 rows)
# 后续四次执行的结果在此省略
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
执行第 6 次时使用通用计划,如下:
*请左右滑动阅览
postgres=> EXPLAIN EXECUTE p(1);
QUERY PLAN
-------------------------------------------------------------------------
Index Only Scan using foo_pkey on foo (cost=0.44..1.56 rows=1 width=8)
Index Cond: (aid = $1)
(2 rows)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
重新执行 PREPARE,并设置 plan_cache_mode 为 force_generic_plan,观察计划使用情况,可见第 1 次执行时就会使用通用计划,而无需等到第 6 次执行。
*请左右滑动阅览
postgres=> DEALLOCATE p;
DEALLOCATE
postgres=> prepare p(integer) as select aid from foo where aid=$1;
PREPARE
# plan_cache_mode 设置为 force_generic_plan
postgres=> set plan_cache_mode = force_generic_plan;
SET
postgres=> EXPLAIN EXECUTE p(1);
QUERY PLAN
-------------------------------------------------------------------------
Index Only Scan using foo_pkey on foo (cost=0.44..1.56 rows=1 width=8)
Index Cond: (aid = $1)
(2 rows)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
是否使用通用计划可以通过执行计划中变量是否做了参数化处理来判断。
05.可插拔表存储接口
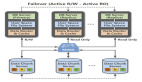
一直以来,PosgreSQL 都只支持 heap 表这一种存储引擎,其实现与其他模块耦合较多。PostgreSQL 12 借鉴自身索引可扩展的实现方式,抽象出一层存储引擎访问接口,为后续支持多种存储引擎奠定了基础,如 ZHeap、列存、K/V 存储、内存引擎等。
可插拔表存储访问接口的架构如下,在原有架构基础上,增加了 表访问管理层(Table Access Manager),提供统一的表访问接口,不同的存储引擎只需实现该接口即可接入。
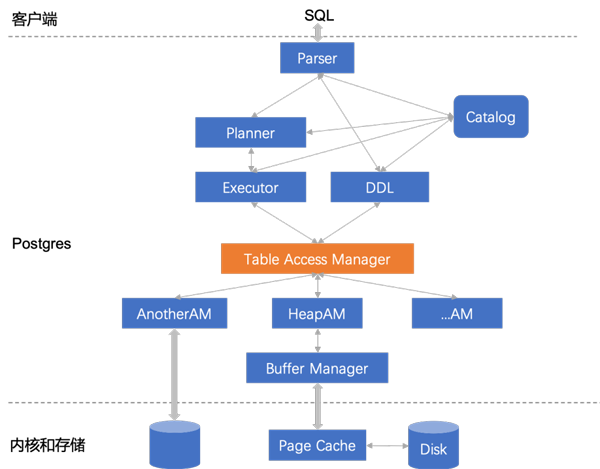
目前,存储引擎仍然只支持 Heap 表,相信不久的将来会支持更多的存储引擎。感兴趣的读者也可以尝试自行实现一个存储引擎。
*请左右滑动阅览
postgres=> select * from pg_am;
oid | amname | amhandler | amtype
------+--------+----------------------+--------
2 | heap | heap_tableam_handler | t
403 | btree | bthandler | i
405 | hash | hashhandler | i
783 | gist | gisthandler | i
2742 | gin | ginhandler | i
4000 | spgist | spghandler | i
3580 | brin | brinhandler | i
(7 rows)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
06.丰富的插件支持
阿里云 RDS PostgreSQL 12 提供了更加丰富的插件支持,满足广大用户在一些垂直领域和特殊场景下的需求,以下介绍一些较常用、有趣的插件,更多支持插件可以参考 PostgreSQL 的支持插件列表。
• roaringbitmap 将 roaringbitmap 作为一种内置数据类型,提供丰富的函数支持,使用 Roaring Bitmap 算法,极大提升位图计算性能。
• RDKit 支持 mol 数据类型(描述分子类型)和 fp 数据类型(描述分子指纹),支持化学分子计算和化学分子检索等功能。
• Ganos 阿里云自研时空数据引擎,支持对空间/时间数据进行高效的存储、索引、查询和分析计算。
• PASE 高性能向量检索插件,使用业界成熟稳定且高效的 ANN(Approximate nearest neighbor)检索算法,包括 IVFFlat 和HNSW 算法,通过这两种算法,可以在 PostgreSQL 数据库中实现极高速向量查询。
• zhparser 中文分词插件,助力实现中文的全文检索。
• oss_fdw 使用该插件可以将 OSS 中的数据加载到 PostgreSQL 中,也支持将 PostgreSQL 中的数据写入 OSS 中。
07.总结
RDS PostgreSQL 12 无论功能和性能都有很大提升,包括分区表查询性能优化,B-tree 索引空间优化和性能提升,参数方式选择 Prepare 语句执行计划,内置的、功能全面的 SQL/JSON 路径语言和更加丰富的插件支持。可插拔表访问接口作为未来支持多存储引擎的基础,意义重大,目前仍然只支持 Heap 表,用户测暂时不会有感知。
除本文介绍的特性外,该版本还有很多其他特性,如多列 MCV(Most-Common-Value)统计,内联 CTE(Common table expressions)等,文中未及介绍,感兴趣的读者可以参考相关文献,点击阅读原文阿里云购买实例进行体验。
08.参考文献
- https://www.postgresql.org/about/press/presskit12/
- https://www.postgresql.org/docs/12/release-12.html
- https://www.postgresql.org/docs/12/functions-json.html#FUNCTIONS-SQLJSON-PATH
- https://www.postgresql.org/docs/12/tableam.html