前言
做大数据绝对躲不过的一个热门话题就是实时流计算,而提到实时流计算,就不得不提 Spark 和 Flink。Spark 从 2014 年左右开始迅速流行,刚推出时除了在某些场景比 Hadoop MapReduce 带来几十到上百倍的性能提升外,还提出了用一个统一的引擎支持批处理、流处理、交互式查询、机器学习等常见的数据处理场景。凭借高性能和全面的场景支持,Spark 早已成为众多大数据开发者的最爱。
正在 Spark 如日中天高速发展的时候,2016 年左右 Flink 开始进入大众的视野并逐渐广为人知。由于Spark在数据流的实时处理中较弱,而Flink 凭借更优的流处理引擎,同时也支持各种处理场景,成为 Spark 的有力挑战者。
本文对 Spark 和 Flink 进行了全面分析与对比,且看下一代大数据计算引擎之争,谁主沉浮?
Spark简介
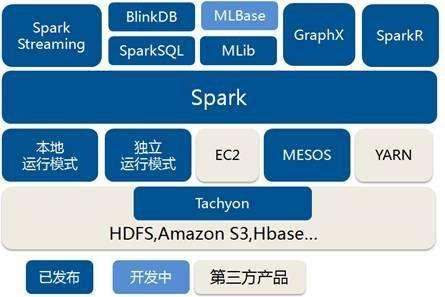
Spark是基于内存的计算框架,计算速度非常快。如果想要对接外部的数据,比如HDFS读取数据,需要事先搭建一个Hadoop 集群。Apache Spark是一个开源集群运算框架,相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
Flink简介
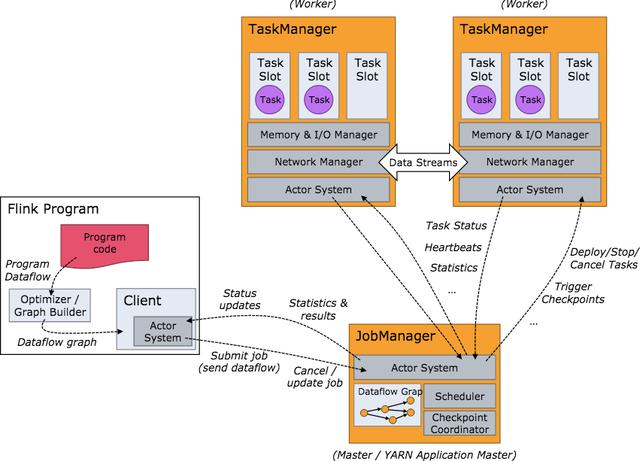
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。
Flink 和 Spark 对比
Spark和Flink都支持批处理和流处理,接下来让我们对这两种流行的数据处理框架在各方面进行对比。首先,这两个数据处理框架有很多相同点。
- 都基于内存计算;
- 都有统一的批处理和流处理APl,都支持类似SQL的编程接口;
- 都支持很多相同的转换操作,编程都是用类似于Scala Collection APl的函数式编程模式;
- 都有完善的错误恢复机制;
- 都支持Exactly once的语义一致性。
当然,它们的不同点也是相当明显,我们可以从4个不同的角度来看。
- 从流处理的角度来讲,Spark基于微批量处理,把流数据看成是一个个小的批处理数据块分别处理,所以延迟性只能做到秒级。而Flink基于每个事件处理,每当有新的数据输入都会立刻处理,是真正的流式计算,支持毫秒级计算。由于相同的原因,Spark只支持基于时间的窗口操作(处理时间或者事件时间),而Flink支持的窗口操作则非常灵活,不仅支持时间窗口,还支持基于数据本身的窗口,开发者可以自由定义想要的窗口操作。
- 从SQL 功能的角度来讲,Spark和Flink分别提供SparkSQL和Table APl提供SQL交互支持。两者相比较,Spark对SQL支持更好,相应的优化、扩展和性能更好,而Flink在SQL支持方面还有很大提升空间。
- 从迭代计算的角度来讲,Spark对机器学习的支持很好,因为可以在内存中缓存中间计算结果来加速机器学习算法的运行。但是大部分机器学习算法其实是一个有环的数据流,在Spark中,却是用无环图来表示。而Flink支持在运行时间中的有环数据流,从而可以更有效的对机器学习算法进行运算。
- 从相应的生态系统角度来讲,Spark 的社区无疑更加活跃。Spark可以说有着Apache旗下最多的开源贡献者,而且有很多不同的库来用在不同场景。而Flink由于较新,现阶段的开源社区不如Spark活跃,各种库的功能也不如Spark全面。但是Flink还在不断发展,各种功能也在逐渐完善。
如何选择Spark和Flink
对于以下场景,你可以选择 Spark。
- 数据量非常大而且逻辑复杂的批数据处理,并且对计算效率有较高要求(比如用大数据分析来构建推荐系统进行个性化推荐、广告定点投放等);
- 基于历史数据的交互式查询,要求响应较快;
- 基于实时数据流的数据处理,延迟性要求在在数百毫秒到数秒之间。
结语
任何技术都不是孤立发展的,大数据技术更是如此。放眼未来,无论是Spark还是Flink,两者的发展重点都将是数据科学和平台API化,使其生态系统越来越完善。亦或许,会有更新的大数据处理引擎出现,谁知道呢。