大家好,关于Python数据分析的工具我们已经讲了很多了,相信一直关注的读者对于Pandas、NumPy、Matplotlib的各种操作一定不陌生,今天我们就用一份简单的数据来学习如何使用Python进行数据分析,本文主要涉及下面三个部分:
- Pandas数据处理
- Matplotlib绘图
- 利用pyinstaller将py文件打包为exe
虽然本文使用的数据(医学相关)不会出现在你平时的工作学习中,但是处理的过程比如导入数据、缺失值处理、数据去重、计算、汇总、可视化、导出等操作却是重要的,甚至还教你如何将程序打包之后对于重复的工作可以一键完成!
数据与需求说明
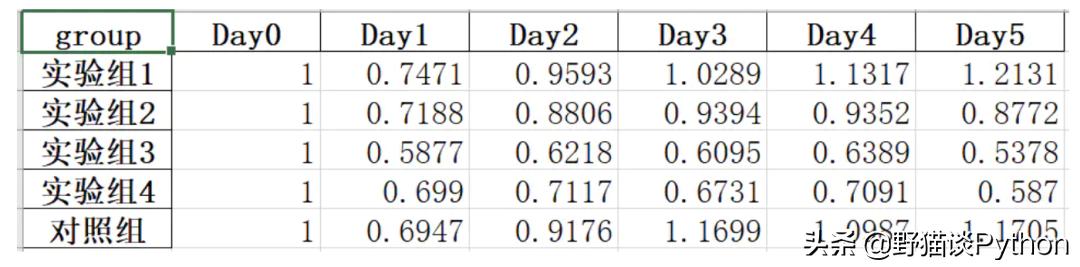
今天分享的案例来源于一个著名的实验Cell Counting Kit-8。首先我们来看下原始数据:
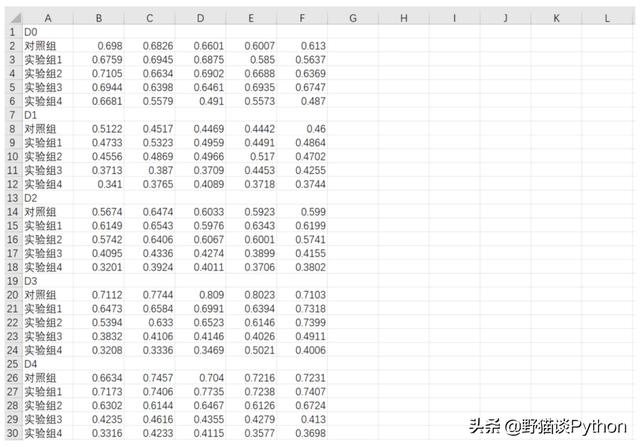
我们需要完成的工作主要有四块:
- 去除各组所有重复中的最大值和最小值
- 所有数据根据D0的对应分组进行标准化
- 计算各组数据的均值和标准差表格:均值汇总表和均值-标准差汇总表
- 绘制折线图
所以我们需要的结果应该是:在自己的桌面上建一个文件夹命名data,将原始数据data.xlsx放进去,之后运行完程序后文件夹会新增3个文件:
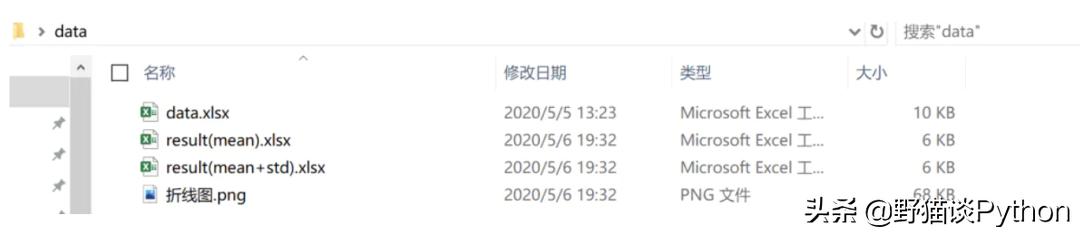
而这三个文件就是我们需要的结果
均值汇总表
均值-标准差汇总表

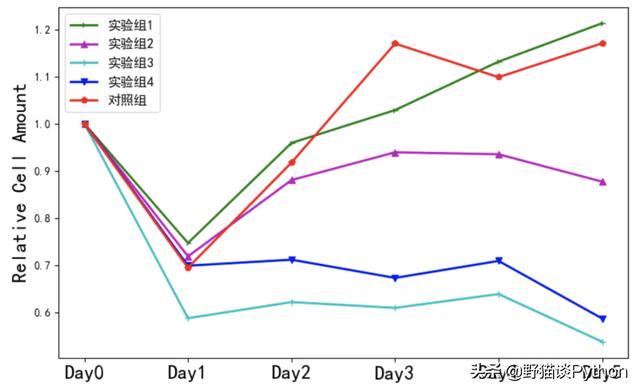
折线图
现在我们就来讲解如何实现。
代码实现
首先导入库并调用函数获取桌面文件夹路径并写在全局
import pandas as pd
import matplotlib.pyplot as plt
import os
import random
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
path = GetDesktopPath() + '/data/'
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
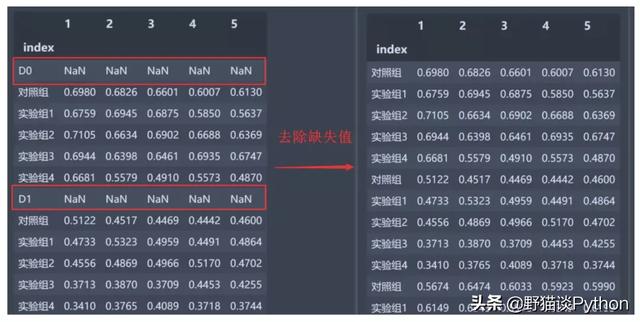
导入原始数据并去除缺失值
dat = pd.read_excel(path + 'data.xlsx',
sheet_name=0,
header=None,
index_col=0)
dat = dat.dropna(how='any', axis=0)
- 1.
- 2.
- 3.
- 4.
- 5.
获取重复次数,分组个数和天数。原始数据有6天、5组、5次重复,虽然也可以直接使用这三个数据,但以后的实验这三个可能会更改,为了让代码能够复用,最好不要写死
# 获取分组个数
ngroup = dat.index.value_counts().shape[0]
# 获取列数即重复次数
nrep = dat.shape[1]
# 获取天数(操作的批次数)即用总行数除以组数,用整除是为了返回int
nd = dat.shape[0] // ngroup
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
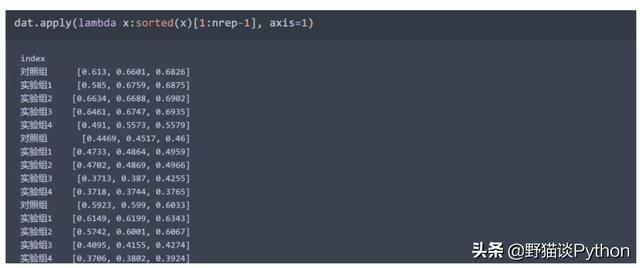
去掉极大值和极小值。这里用的解决办法是逐行升序排序,然后去掉第一个和最后一个数据,可以用apply+lambda处理
df = dat.apply(lambda x: sorted(x)[1:nrep - 1], axis=1)
df = df.to_frame(name='total')
for i in range(nrep - 2):
df[f'{i + 1}'] = df['total'].str[i]
df.drop(columns=['total'], inplace=True)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
用匿名函数排序返回的是Series的升序列表,须有转换回DataFrame再拆成三列,最后去掉原来返回那一列即可。因此有了如上代码
在常规列中添加分组信息和批次信息,便于后续做汇总表
df['group'] = df.index
day_lst = []
for i in range(nd):
day_lst.append(f'Day{i}')
# 用列表推导式做列表内元素重复并添加新列
df['day'] = [i for i in day_lst for _ in range(ngroup)]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
效果如图:
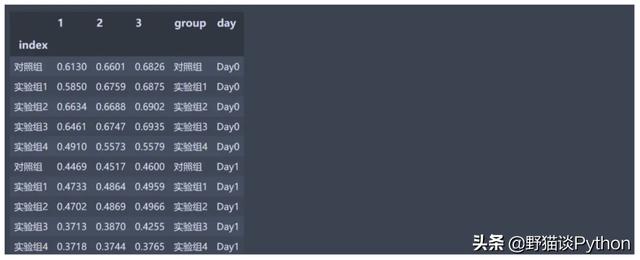
根据D0的各组均值对所有数据标准化,可以简单理解为DO批次5个组去除两个极值后各求平均值,这5个批次的5个组各自除于D0对应组的均值)
# 根据组数取出D0的所有行数,然后按行求均值,会自动忽略文本信息
mean_lst = df.iloc[0:ngroup, :].mean(axis = 1).tolist()
# 由于接下来要按行进行迭代,且索引的分组信息已经有一个新列来表述,这里重置索引方便迭代
df.reset_index(drop=True, inplace=True)
# 迭代的内容看起来复杂实际上不难
# 本质上就是将迭代行的数据和D0对应分组均值相除
for index, i in df.iterrows():
df.iloc[index, 0:nrep - 2] = i[0:nrep - 2] / mean_lst[index % ngroup]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
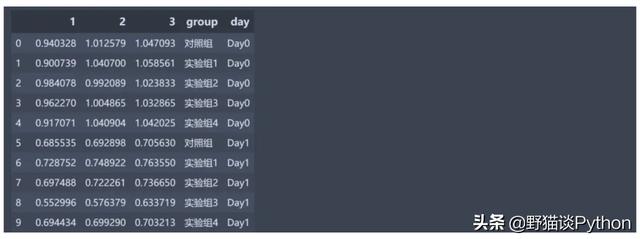
标准化结束后即可获取均值和标准差
# 同样mean和std均会忽略非数值列
# 谨慎一点用df['mean'] = df.iloc[:, 0:nrep - 2].mean(axis=1)也可以
df['mean'] = df.mean(axis=1)
df['std'] = df.std(axis=1)
# 获取最后四列
results = df.iloc[:, -4:]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
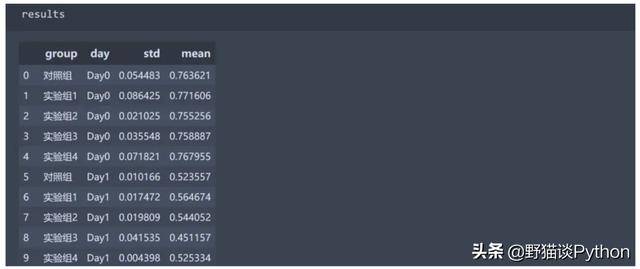
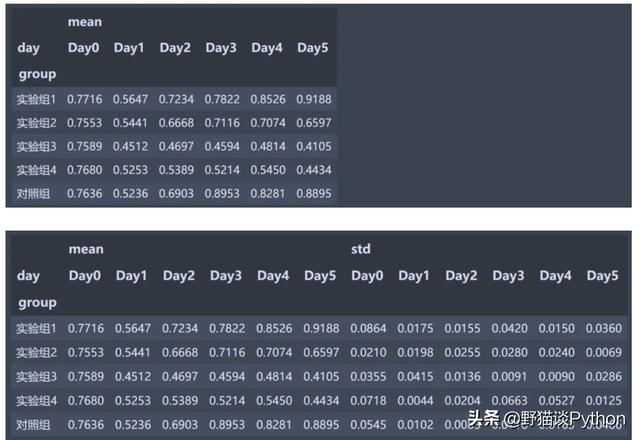
制作数据透视表并导出
# 用round保留4位有效数字
tb1 = pd.pivot_table(data=results,
index='group',
columns='day',
values='mean').round(4)
tb2 = pd.pivot_table(data=results,
index='group',
columns='day',
values=['mean', 'std']).round(4)
tb1.to_excel(path + '/result(mean).xlsx',
index=True,
header=True)
tb2.to_excel(path + '/result(mean+std).xlsx',
index=True,
header=True)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
在Jupyter Notebook呈现结果如下,在Excel的呈现如本文开头所示
利用matplotlib画图,补充两个细节,如果在Jupyter Notebook希望出图需要加上如下代码
%matplotlib inline
- 1.
如果有中文字符需要呈现也同样需要用代码设置
plt.rcParams['font.sans-serif'] = ['SimHei']
- 1.
汇总表的索引(组名)可以用做图像的标签。而颜色和折线上标记样式所用的测量是根据所需的个数随机无放回抽样
group_lst = tb1.index.tolist()
colors = ['b', 'g', 'r', 'c', 'm', 'y']
color_lst = random.sample(colors, ngroup)
markers = ['.', ',', 'o', 'v', '^', '<', '>',
'1', '2', '3', '4', 's', 'p', '*', 'h', 'H', '+', 'x', 'D', 'd']
marker_lst = random.sample(markers, ngroup)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
最后的画图代码:
# 设置画布大小
plt.figure(figsize=(8, 5))
for i in range(ngroup):
plt.plot(tb1.iloc[i, :].tolist(),
f'{color_lst[i]}{marker_lst[i]}-', lw=2)
plt.xticks(range(0, nd), day_lst, fontsize=18)
plt.ylabel('Relative Cell Amount', fontsize=18)
plt.legend(group_lst, loc='best', fontsize=12)
# 让图像的显示分布正常
plt.tight_layout()
# 保存一定要在调用展示之前
plt.savefig(path + "/折线图.png")
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
exe打包
首先在命令行使用pip安装pyinstaller
pip install pyinstaller
- 1.
将完整代码保存成py文件,这里我保存为cck8.py,然后放在桌面上data文件夹内,然后打开命令行,cd进入该文件夹,然后调用第二行命令即可以编译成exe
cd C:\Users\chenx\Desktop\data
pyinstaller --onefile --clean cck8.py
- 1.
- 2.
当然第二行的命令可以自定义如添加图标等等,这里不做介绍,有兴趣的可以自己探索。