前言
大数据技术相辅相成,没有任何一种技术是没有缺点,孤立发展的。今天咱们来分析下Kafka和Redis的对比,看分布式发布订阅都有什么各自的优势与缺点。

Redis是什么
Redis 是开源免费的,遵守BSD协议,是一个高性能的key-value非关系型数据库。可能有朋友会问,Redis作为存储数据库,怎么和分布式发布订阅消息系统Kafka对比?两者本身不是同一个层次的东西啊。
但是Redis中有一个queue的数据类型,用来做发布/订阅系统,这个就可以和kafka进行比较了。
kafka是什么
Kafka 是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可在廉价PC Server上搭建起大规模消息系统。Kafka具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性
现在干货来了,kafka和Redis的区别联系
存储介质不同
redis queue数据是存储在内存,虽然有AOF和RDB的持久化方式,但是还是以内存为主。
kafka是存储在硬盘上
性能不同
因为存储介质不同,理论上redis queue的性能要优于kafka,但是在实际使用过程,这块体验并不是很明显,通常只有一些高并发场景下需要用redis queue,比如发红包,可以先将红包预先拆解然后push到redis queue,在抢的一瞬间可以很好的支撑并发。
成本不同
这边要划重点,划重点,划重点。
kafka存储在硬盘上,成本会比内存小很多,具体差1,2个数量级是有,在数据量非常大的情况下,使用kafka能够节省蛮多服务器成本。最常见的有应用产生的日志,这些日志产生的量级一般都很大,如果有需要进行处理,可以使用kafka队列。
这只是简单的介绍原始差距,咱们再来看核心对比——作为消息队列的优劣对比
Redis作为消息队列
redis发布(pub)、订阅(sub)模式
redis中的发布订阅由三部分组成。发布者(生产者)、通道(类似于topic)、订阅者(消费者),具体结构如下图:
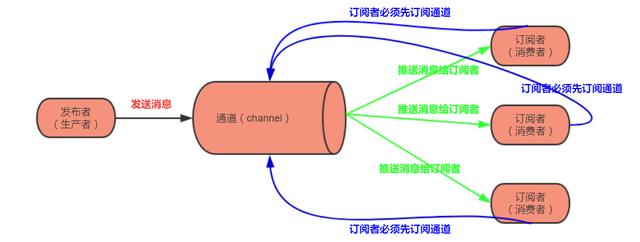
Redis的pub-sub模式非常像西式快餐一样,快餐快消,全都是因为Redis是使用内存来做存取,所有你生产的消息立马会被消费者一次性全部处理掉,并且没有留下任何痕迹, 同时因为内存总是宝贵的,所以内存上会有限制,当生产者以及消费者上来的时候也会对redis的效率,还有Redis在处理发布和消费big size(10K+的文件)的数据的时候会表现出无法忍受的缓慢
如果有以下场景可以考虑使用Redis作为消息队列
- 如果你的需求是快产快消的即时消费场景,并且生产的消息立即被消费者消费掉
- 如果速度是你十分看重的,比如慢了一秒好几千万这种
- 如果允许出现消息丢失的场景
- 如果你不需要系统保存你发送过的消息,做到来无影去无踪
- 如果需要处理的数据量并不是那么巨大
KafKa作为消息队列
KafKa的设计精妙,支持分布式,高可用的部署,并且对一个大的队列采用分成多个Partition(分区),来提高消息入队的吞吐量,分而治之的思想. 并且消费的时候支持group的概念,能够支持多个客户端消费同个队列,并且一个group中可以增加consumer的数量来扩展消费的处理量.
KafKa不受生产者数量的影响,因为吞吐量足够支撑,即使在廉价的单机服务器上也可以有10万每秒的消息传输量,并且消费者是想什么时候消费都可以,消息它就在那里,十分灵活,不用担心来无影去无踪的恐慌.能把消息持久化,并以一定的策略(例如一定时间内删除,或者到达多大容量的时候清空)
当有一下场景的时候你可以考虑使用KafKa作为消息队列
- 如果你想要稳定的消息队列
- 如果你想要你发送过的消息可以保留一定的时间,并不是无迹可寻的时候
- 如果你无法忍受数据的丢失
- 如果速度不需要那么的快
- 如果需要处理数据量巨大的时候
后结
Redis 是以 key 的 hash 方式来分散对列存储数据的,且 Redis 作为集群使用时,对应的应用对应一个 Redis,在某种程度上会造成数据的倾斜性,从而导致数据的丢失。
而从之前部署 Kafka 集群来看,kafka 的一个 topic(主题),可以有多个 partition(副本),而且是均匀的分布在 Kafka 集群上,这就不会出现 redis 那样的数据倾斜性。Kafka 同时也具备 Redis 的冗余机制,像 Redis 集群如果有一台机器宕掉是很有可能造成数据丢失,而 Kafka 因为是均匀的分布在集群主机上,即使宕掉一台机器,是不会影响使用。同时 Kafka 作为一个订阅消息系统,还具备每秒百万级别的高吞吐量,持久性的、分布式的特点等。