













01 需求介绍
考虑MySQL中的一个经典应用:给定一个学生考试成绩表,要实现对学生按课程依成绩高低进行排序。为了简单起见,仅给定成绩表,而不考虑可能关联的学生信息表、课程信息表和教师信息表等,且成绩表中仅创建3个关键字段:
- cid:课程id,int型,共5门课程
- sid:学生id,int型,共8872名学生
- score:成绩,int型,共22366条成绩信息,分布于10-100之间

为了逐步分析,初始状态不添加主键,也不建立任何索引。
02 子查询
实现这一需求的最直接想法是通过子查询,对每个分数进行统计:统计表中有多少分数比其更高,那么该分数的排名就是更高分数计数+1。如果要区分课程排名,那么统计表时只需增加一个限制课程id相等的约束条件即可。
- 1SELECT
- 2 a.*, ( SELECT COUNT(score)+1 FROM scores WHERE cid = a.cid AND score > a.score ) AS 'rank'
- 3FROM
- 4 scores a
- 5ORDER BY
- 6 a.cid, a.score DESC;
需注意的是,在子查询约束条件中要求score > a.score以及COUNT()+1,表示统计的是比该成绩更高的计数+1,例如对于90、80、80、70……这样的分数得到排名结果是1,2,2,4……;如果选用score >= a.score和COUNT()作为排名条件,那么得到结果是1,3,3,4……
在未添加任何索引的情况下,这个查询速度是相当慢的,耗时120s。

未添加索引时的子查询执行计划
优化查询的第一想法当然是添加索引:虽然外层查询未用到任何where约束条件,但子查询中用到了cid和score两个字段判断,于是考虑添加索引:
- 1CREATE INDEX idc ON scores(cid);
- 2CREATE INDEX ids ON scores(score);
增加索引后,查询耗时96s,虽然有提升,但仍难堪重任。解释查询计划,发现虽然速度仍然很慢,但两个索引确实都得到了应用:

添加独立索引后的子查询执行计划
既然独立索引无法明显提升效率,考虑子查询中where条件不是独立字段的常值约束,而是依赖于外层循环取值的联合约束,那么再考虑添加一个联合索引:
- CREATE INDEX idcs ON scores(cid, score);
查询速度确实是更快了,实际用时24s。解释查询计划,发现既用到了独立索引,也用到了联合索引。但不得不说,24s的响应时间对于要求0.5s解决战斗的即时任务来说,仍然是不够的。
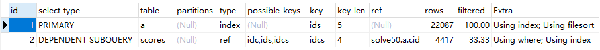
添加联合索引后的子查询执行计划
只能另辟蹊径。
03 自连接
一般来说,对于速度较慢的子查询任务,换做连接查询(join)可以得到明显提升。
具体到分课程排名这一具体需求,我们考虑对scores表进行自连接,其中连接条件为课程相等且a表score值小于b表score值,从而通过统计满足连接条件的记录数即可得到排名信息:
- 1SELECT
- 2 a.*, COUNT(b.score)+1 AS 'rank'
- 3FROM
- 4 scores a LEFT JOIN scores b ON (a.cid = b.cid AND a.score < b.score)
- 5GROUP BY
- 6 a.cid, a.sid
- 7ORDER BY
- 8 a.cid, COUNT(b.score)
需注意的是:连接方式要选用left join,以便将a表中的所有分数信息都显示出来;若是用join,则最高分因为不存在满足连接的记录而被漏掉。至于连接条件中score值和count()的关系类似于子查询中的情况。
应用自连接,在不创建任何索引的情况下查询速度与子查询情况差不多,耗时73s;在添加有效索引后,查询时间27s,效率有所提升,但与查询方案效率相当。

未添加索引时的自连接执行计划

添加有效索引后的自连接执行计划
显然,应用自连接替代子查询的方案并没有显著提升查询效率,即使是在添加了有效索引的基础上。
进一步分析数据表发现,实际上速度慢并不能否认索引在改善查询效率方面的能力,而仅仅是因为添加索引的字段取值较少的原因:cid字段仅有5个取值——当字段取值个数较少时,添加索引很难见效。
例如,如果换一个需求,改为按学生区分各门课程的成绩排名(sid取值数量很大),则应用索引即可有效改善查询效率。按学生查询成绩排名SQL语句:
- 1SELECT
- 2 a.*, count(b.score)+1 AS 'rank'
- 3FROM
- 4 scores a LEFT JOIN scores b ON (a.sid = b.sid AND a.score < b.score)
- 5GROUP BY
- 6 a.sid, a.cid
- 7ORDER BY
- 8 a.sid, count(b.score)
对于如上查询,在未添加索引时,查询时间34s;添加有效索引后耗时仅为0.184s,添加索引的提升效果非常明显。
虽然这一论断捍卫了索引的地位作用,但如果我们的需求就是按课程进行排名呢?显然,无论是子查询还是自连接方案,都难以满足我们的实时查询需求。
只得再觅他法。
04 自定义变量
实际上,上述两种方案之所以速度较慢,是因为都作用在两个表上查询,如果再考虑外层的order by,那么执行时间复杂度粗略估计在O(n3)量级。此时,我们考虑应用自定义变量实现更低复杂度的查询实现。
应用自定义变量,我们不仅可以提高速度,而且还能实现"各种"排名:例如对于90、80、80、70、60这样一组成绩,可能有3种排名需求,一种是连续排名,同分时名次也继续增加:1、2、3、4、5;第二种是同分同名,下一排名不跳级,即1、2、2、3、4;第三种是同分同名,下一排名跳级,即1、2、2、4、5。这三种需求应用自定义变量进行排序都可以轻松搞定(具体变量含义和思路后续给出):
- 连续排名:
- 1SELECT
- 2 sid, cid, @curRank:=@curRank+1 AS 'rank'
- 3FROM
- 4 scores, (SELECT @curRank:=0) tmp
- 5ORDER BY
- 6 score DESC
- 同分同名,不跳级:
- 1SELECT
- 2 sid, cid, @curRank:=IF(score=@preScore, @curRank, @curRank+1) AS 'rank',
- 3 @preScore:=score
- 4FROM
- 5 scores, (SELECT @curRank:=0, @preScore:=NULL) tmp
- 6ORDER BY
- 7 score
- 同分同名,跳级:
1SELECT
- 2 sid, cid, @curRank := IF(score=@preScore, @curRank, @totalRank) AS 'rank',
- 3 @preScore := score,
- 4 @totalRank := @totalRank+1
- 5FROM
- 6 scores, (SELECT @curRank:=1, @totalRank:=1, @preScore:=NULL) tmp
- 7ORDER BY
- 8 score
以上SQL语句是在不进行任何分类条件下的排名:通过自定义变量(MySQL定义变量用@作为引导符,并用:=表示赋值)记录前一个排名、前一个分数值、当前的总排名,分别实现三种需求。
那么,若要实现分类排名呢,比如说区分各课程进行排名?那么只需再增加一个自定义变量,用于记录前一个课程cid即可:
- 若当前分类信息与前一课程cid相同,则继续当前的排名处理(根据具体需求选择三种排名中的一种);
- 若当前分类与前一课程cid不同,则排名信息初始化,从1重新开始。
以相对复杂的“同分同名、跳级”为例,此时SQL语句为:
- 1SELECT sid, cid,
- 2 @totalRank := IF(cid=@preCid, @totalRank+1, 1),
- 3 @curRank := IF(cid=@preCid, IF(score=@preScore, @curRank, @totalRank), 1) AS 'rank',
- 4 @preScore := score,
- 5 @preCid := cid
- 6FROM
- 7 scores, (SELECT @curRank:=0, @totalRank:=0, @preScore:=NULL, @preCid:=NULL) tmp
- 8ORDER BY
- 9 cid, score DESC
- 8 score
对各变量含义解释如下:
- @totalRank用于记录当前分类中的总排名,初始化为0
- @curRank用于记录当前分类中的当前排名,初始化为0
- @preScore用于记录上一个分数情况,初始化为NULL
- @preCid用于记录上一个课程cid,初始化为NULL
执行流程及条件判断为:
- 若当前cid与前一cid相同,表示是同一个分类,排名在之前排名基础增加,具体来说:
- 总排名每次+1
- 若当前分数与前一分数相同,则当前排名不变;否则跳级到总排名
- 若当前cid与前一cid不同,表示开始新的课程排名,总排名和当前排名均初始化为1
基于以上SQL语句,执行相同的任务,耗时仅需0.09s,其效率相当于子查询最快速度24s的266倍,相当于自连接最快速度27s的300倍,其查询效率可见一斑。
另外,由于上述SQL语句不存在where约束条件,所以与是否建立索引无关。
05 MySQL8.0窗口函数
MySQL8.0版本的一个重要更新就是增加了窗口函数,使得前面的分类排名需求变得异常简单。
与前述类似,不同的排名需求有不同的窗口函数,而且三个函数的命名也非常形象直观:
- 连续排名:row_number(),排名即行号
- 同分同名,不跳级:dense_rank(),致密排名,类似1、2、2、3……这种,因为不跳级,所以比较"致密"
- 同分同名,跳级:rank(),普通排名,类似1、2、2、4……这种
其中,每个窗口函数函数又必须与over()函数配套使用,over()函数中的参数主要包括partion by 和order by:
- order by:与常规SQL语句中order by一致,表示按照某一字段进行排序,也区分ASC还是DESC
- partion by:用作分类依据,缺省时表示不分类,对所有记录排序;若指定某一字段,则表示在该字段间进行独立排序,跨字段重新开始
仍以之前的分课程排名需求为例,其SQL语句为:
- 1SELECT
- 2 *, RANK() OVER(PARTITION BY cid ORDER BY score DESC) AS 'rank'
- 3FROM
- 4 scores;
查询耗时0.066s,比自定义变量实现的排名速度略高一点。同时,该排名方式也与索引无关。
将RANK()替换成另外两个窗口函数,可实现其他相应需求。
06 总结
本文以对给定成绩表进行分课程排名为例,讲述了4种实现方案:
- 子查询方案,通过嵌套count()函数实现,效率较低,创建有效索引可提升一定效率,仅支持"同分同名、跳级"排名需求
- 自连接方案,与子查询类似,通过自连接和count()函数实现,效率较低,依赖于索引,也仅支持"同分同名、跳级"排名需求
- 自定义变量方案,通过定义变量实现计数,效率很高,不依赖索引,且可以实现各种排名需求,任意版本通用
- MySQL8.0窗口函数,相当于对自定义变量方案的封装,效率最高,不依赖于索引,但8.0以前版本无法使用
实际上,在得到排名需求后,可进一步通过简单子查询实现查询分类Top K的任务需求。
























