












要说计算机系统里,什么技术把tradeoff体现的淋漓尽致,那肯定是缓存无疑。为了协调高速部件和低速部件的速度差异,加入一个中间缓存层,是解决这种冲突最有效的方案。
其中,JVM堆内缓存是缓存体系中重要的一环,最常用的有FIFO/LRU/LFU三种算法。
- FIFO是简单的队列,先进先出。
- LRU是最近最少使用,优先移除最久未使用的数据。是时间维度。
- LFU是最近最不常用,优先移除访问次数最少的数据。是统计维度。
由于过期也是缓存的一个重要特点。所有在设计这三种缓存算法时,需要额外的存储空间去存储这个过期时间。
以下将讨论这三种缓存算法的操作和设计要点,但暂未考虑高并发环境。
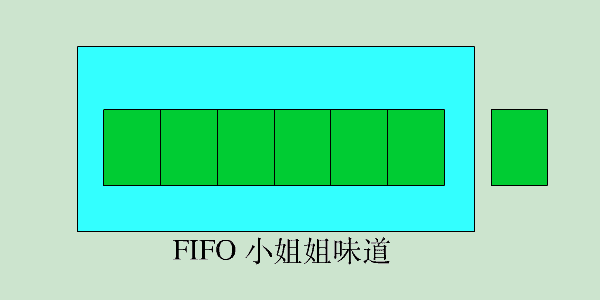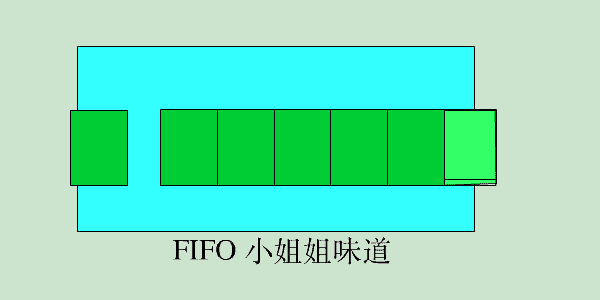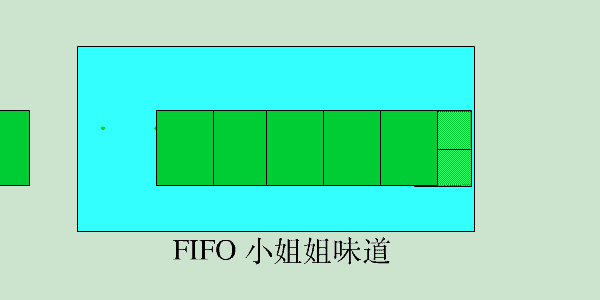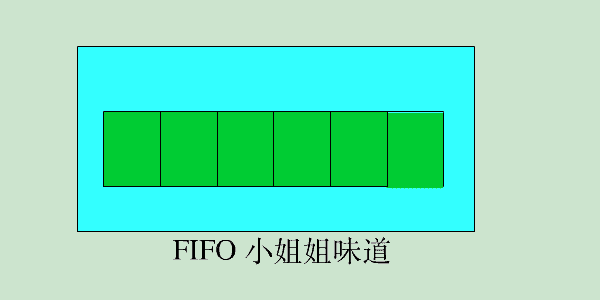
FIFO
先进先出,如果缓存容量满,则优先移出最早加入缓存的数据;其内部可以使用队列实现。
操作
- Object get(key) :获取保存的数据,如果数据不存在或者已经过期,则返回null。
- void put(key,value,expireTime):加入缓存。 无论此key是否已存在,均作为新key处理(移除旧key);如果空间不足,则移除已过期的key,如果没有,则移除最早加入缓存的key。过期时间未指定,则表示永不自动过期。
- 注意 ,我们允许key是有过期时间的,这一点与普通的FIFO有所区别,所以在设计此题时需要注意。(也是面试考察点,偏设计而非算法)
普通的FIFO或许大家都能很简单的写出,增加了过期时间的考虑之后,在设计时需要多考虑。如下示例,为暂未考虑并发环境的FIFO设计。
设计思路
1)用普通的hashMap保存缓存数据。
2)需要额外的map用来保存key的过期特性,例子中使用了TreeMap,将“剩余存活时间”作为key,利用TreeMap的排序特性。
- public class FIFOCache {
- //按照访问时间排序,保存所有key-value
- private final Map<String,Value> CACHE = new LinkedHashMap<>();
- //过期数据,只保存有过期时间的key
- //暂不考虑并发,我们认为同一个时间内没有重复的key,如果改造的话,可以将value换成set
- private final TreeMap<Long, String> EXPIRED = new TreeMap<>();
- private final int capacity;
- public FIFOCache(int capacity) {
- this.capacity = capacity;
- }
- public Object get(String key) {
- //
- Value value = CACHE.get(key);
- if (value == null) {
- return null;
- }
- //如果不包含过期时间
- long expired = value.expired;
- long now = System.nanoTime();
- //已过期
- if (expired > 0 && expired <= now) {
- CACHE.remove(key);
- EXPIRED.remove(expired);
- return null;
- }
- return value.value;
- }
- public void put(String key,Object value) {
- put(key,value,-1);
- }
- public void put(String key,Object value,int seconds) {
- //如果容量不足,移除过期数据
- if (capacity < CACHE.size()) {
- long now = System.nanoTime();
- //有过期的,全部移除
- Iterator<Long> iterator = EXPIRED.keySet().iterator();
- while (iterator.hasNext()) {
- long _key = iterator.next();
- //如果已过期,或者容量仍然溢出,则删除
- if (_key > now) {
- break;
- }
- //一次移除所有过期key
- String _value = EXPIRED.get(_key);
- CACHE.remove(_value);
- iterator.remove();
- }
- }
- //如果仍然容量不足,则移除最早访问的数据
- if (capacity < CACHE.size()) {
- Iterator<String> iterator = CACHE.keySet().iterator();
- while (iterator.hasNext() && capacity < CACHE.size()) {
- String _key = iterator.next();
- Value _value = CACHE.get(_key);
- long expired = _value.expired;
- if (expired > 0) {
- EXPIRED.remove(expired);
- }
- iterator.remove();
- }
- }
- //如果此key已存在,移除旧数据
- Value current = CACHE.remove(key);
- if (current != null && current.expired > 0) {
- EXPIRED.remove(current.expired);
- }
- //如果指定了过期时间
- if(seconds > 0) {
- long expireTime = expiredTime(seconds);
- EXPIRED.put(expireTime,key);
- CACHE.put(key,new Value(expireTime,value));
- } else {
- CACHE.put(key,new Value(-1,value));
- }
- }
- private long expiredTime(int expired) {
- return System.nanoTime() + TimeUnit.SECONDS.toNanos(expired);
- }
- public void remove(String key) {
- Value value = CACHE.remove(key);
- if(value == null) {
- return;
- }
- long expired = value.expired;
- if (expired > 0) {
- EXPIRED.remove(expired);
- }
- }
- class Value {
- long expired; //过期时间,纳秒
- Object value;
- Value(long expired,Object value) {
- this.expired = expired;
- this.value = value;
- }
- }
- }
LRU
least recently used,最近最少使用,是目前最常用的缓存算法和设计方案之一,其移除策略为“当缓存(页)满时,优先移除最近最久未使用的数据”,优点是易于设计和使用,适用场景广泛。算法可以参考leetcode 146 (LRU Cache)。
操作
- Object get(key):从cache中获取key对应的数据,如果此key已过期,移除此key,并则返回null。
- void put(key,value,expired):设置k-v,如果容量不足,则根据LRU置换算法移除“最久未被使用的key”。 需要注意,根据LRU优先移除已过期的keys,如果没有,则根据LRU移除未过期的key。如果未设定过期时间,则认为永不自动过期。
- 这里的设计关键是过期时间特性,这与常规的LRU有所不同。
设计思路
- LRU的基础算法,需要了解;每次put、get时需要更新key对应的访问时间,我们需要一个数据结构能够保存key最近的访问时间且能够排序。
- 既然包含过期时间特性,那么带有过期时间的key需要额外的数据结构保存。
- 暂时不考虑并发操作;尽量兼顾空间复杂度和时间复杂度。
- 此题仍然偏向于设计题,而非纯粹的算法题。
此题代码与FIFO基本相同,唯一不同点为get()方法,对于LRU而言,get方法需要重设访问时间(即调整所在cache中顺序)
- public Object get(String key) {
- //
- Value value = CACHE.get(key);
- if (value == null) {
- return null;
- }
- //如果不包含过期时间
- long expired = value.expired;
- long now = System.nanoTime();
- //已过期
- if (expired > 0 && expired <= now) {
- CACHE.remove(key);
- EXPIRED.remove(expired);
- return null;
- }
- //相对于FIFO,增加顺序重置
- CACHE.remove(key);
- CACHE.put(key,value);
- return value.value;
- }
LFU
最近最不常用,当缓存容量满时,移除 访问次数 最少的元素,如果访问次数相同的元素有多个,则移除最久访问的那个。设计要求参见leetcode 460( LFU Cache)
- public class LFUCache {
- //主要容器,用于保存k-v
- private Map<String, Object> keyToValue = new HashMap<>();
- //记录每个k被访问的次数
- private Map<String, Integer> keyToCount = new HashMap<>();
- //访问相同次数的key列表,按照访问次数排序,value为相同访问次数到key列表。
- private TreeMap<Integer, LinkedHashSet<String>> countToLRUKeys = new TreeMap<>();
- private int capacity;
- public LFUCache(int capacity) {
- this.capacity = capacity;
- //初始化,默认访问1次,主要是解决下文
- }
- public Object get(String key) {
- if (!keyToValue.containsKey(key)) {
- return null;
- }
- touch(key);
- return keyToValue.get(key);
- }
- /**
- * 如果一个key被访问,应该将其访问次数调整。
- * @param key
- */
- private void touch(String key) {
- int count = keyToCount.get(key);
- keyToCount.put(key, count + 1);//访问次数增加
- //从原有访问次数统计列表中移除
- countToLRUKeys.get(count).remove(key);
- //如果符合最少调用次数到key统计列表为空,则移除此调用次数到统计
- if (countToLRUKeys.get(count).size() == 0) {
- countToLRUKeys.remove(count);
- }
- //然后将此key的统计信息加入到管理列表中
- LinkedHashSet<String> countKeys = countToLRUKeys.get(count + 1);
- if (countKeys == null) {
- countKeys = new LinkedHashSet<>();
- countToLRUKeys.put(count + 1,countKeys);
- }
- countKeys.add(key);
- }
- public void put(String key, Object value) {
- if (capacity <= 0) {
- return;
- }
- if (keyToValue.containsKey(key)) {
- keyToValue.put(key, value);
- touch(key);
- return;
- }
- //容量超额之后,移除访问次数最少的元素
- if (keyToValue.size() >= capacity) {
- Map.Entry<Integer,LinkedHashSet<String>> entry = countToLRUKeys.firstEntry();
- Iterator<String> it = entry.getValue().iterator();
- String evictKey = it.next();
- it.remove();
- if (!it.hasNext()) {
- countToLRUKeys.remove(entry.getKey());
- }
- keyToCount.remove(evictKey);
- keyToValue.remove(evictKey);
- }
- keyToValue.put(key, value);
- keyToCount.put(key, 1);
- LinkedHashSet<String> keys = countToLRUKeys.get(1);
- if (keys == null) {
- keys = new LinkedHashSet<>();
- countToLRUKeys.put(1,keys);
- }
- keys.add(key);
- }
- }
End本文力求比较三个基本的缓存算法,以便对缓存建设之路有一个比较笼统的感觉。
更加易用的cache,可以参考guava的实现。谨希望这三个代码模版,能够对你有所帮助。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。



















