前言
最近有个好朋友换工作了,面了腾讯后端,跟他要了份面试真题,大家一起来探讨一下,哈哈~
腾讯后端一面
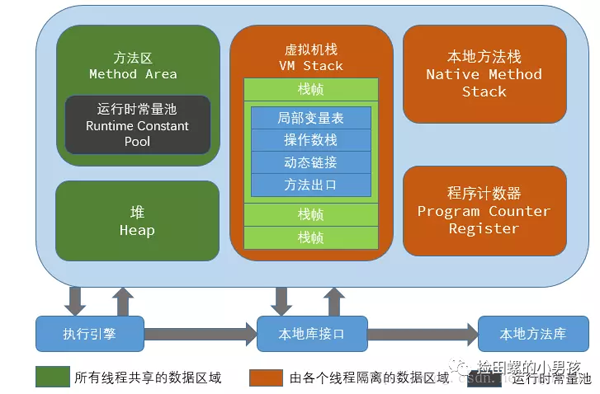
1.JVM内存模型
这个可以复习一下《深入理解Java虚拟机》第12章(Java内存模型和线程),放错图了哈~,也可以看看我之前的文章哈~JVM常见面试题解析
2.cms和g1有没有了解过,它们有什么区别
- CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用;
- G1收集器收集范围是老年代和新生代,不需要结合其他收集器使用;
- CMS收集器以最小的停顿时间为目标的收集器;
- G1收集器可预测垃圾回收的停顿时间
- CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
- G1收集器使用的是“标记-整理”算法,进行了空间整合,降低了内存空间碎片。
这个点是可以看《深入理解Java虚拟机》第三章,垃圾收集器与内存分配策略哈
3.谈谈你对垃圾回收的了解,什么时候发生垃圾回收,回收过程
可以讲JVM中一次完整的GC流程是怎样的,对象如何晋升到老年代,如Minor GC,Major GC,full GC这几个讲清楚,还有对象存活判断方法,还有垃圾回收算法,复制算法等等
这个点也是可以看《深入理解Java虚拟机》第三章,垃圾收集器与内存分配策略哈
4.对于数据的一致性是怎么保证的
- 这个如果是我的思路的话,我会谈缓存与数据库的一致性,可以看看我之前这篇文章:
并发环境下,先操作数据库还是先操作缓存?
- 也可以谈谈分布式事务下的数据一致性,也可以看看之前我的这篇文章:
后端程序员必备:分布式事务基础篇
5.Redis集群有没有了解过,主从和选举是怎么样子的
- 这个可以回答这些关键词,主从复制 ,哨兵机制等这些~
- 可以看看网上这篇啦,或者亲爱的读者,去网上看一下资料哈~Redis 主从复制架构和Sentinel哨兵机制(https://aiylqy.com/archives/213.html)
6.看你们公司使用的是MySQL,你们使用的是哪种存储引擎,为什么?MyISAM和InnoDB的区别
- MyISAM:如果执行大量的SELECT,MyISAM是更好的选择
- InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表
- mysiam表不支持外键,而InnoDB支持
MyISAM适合:
- 做很多count 的计算;
- 插入不频繁,查询非常频繁;
- 没有事务。
InnoDB适合:
- 列表内容 可靠性要求比较高,或者要求事务;
- 表更新和查询都相当的频繁,并且行锁定的机会比较大的情况。
7. 索引的底层数据结构是什么,为什么选择这种数据结构
可以看看网上的这篇,写得不错~MySQL索引为什么要用B+树实现?
8. SQL优化,怎么判断需要优化,从哪些方面着手优化
从索引角度出发,就有很多点可以讲,这个可以看看我的这两篇文章哈~
- 后端程序员必备:书写高质量SQL的30条建议
- 后端程序员必备:索引失效的十大杂症
9.手写代码:设计一个分布式自增id生成服务
可以去网上找一下答案哈,这个我也没什么思路~参考分库分表一些想法?nginx负载均衡一些想法?哈哈,亲爱的读者,如果你会的话,可不可以告诉我呢
腾讯后端二面
1.有没有了解过网络安全问题,常见的网络攻击有哪些,原理是什么,可以怎么解决
XSS,跨站脚本攻击?CSRF,跨站请求伪造?DDOS,分布式拒绝服务攻击?SQL注入?
对于SQL注入,可以进行后台处理,比如,使用预编译语句PreparedStatement进行预处理,又比如Mybatis映射语句中,用#{xxx}而不是${}
2.平时在开发接口或者设计项目的时候如何保证安全性的
- 签名
- 加密
- ip检测限流?
- 接口幂等
- 特殊字符实现过滤 防止xss、sql注入的攻击?
3.使用Redis集群时可能会存在什么问题
数据一致性问题
4.有没有了解过cap和base原则
CAP理论
CAP理论作为分布式系统的基础理论,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),这三个要素最多只能同时实现两点。
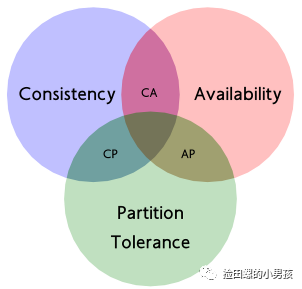
一致性(C:Consistency):
一致性是指数据在多个副本之间能否保持一致的特性。例如一个数据在某个分区节点更新之后,在其他分区节点读出来的数据也是更新之后的数据。
可用性(A:Availability):
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里的重点是"有限时间内"和"返回结果"。
分区容错性(P:Partition tolerance):
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务。
| 选择 | 说明 |
|---|---|
| CA | 放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择 |
| AP | 放弃一致性,分区容错性和可用性,这是很多分布式系统设计时的选择 |
| CP | 放弃可用性,追求一致性和分区容错性,网络问题会直接让整个系统不可用 |
BASE 理论
BASE 理论, 是对CAP中AP的一个扩展,对于我们的业务系统,我们考虑牺牲一致性来换取系统的可用性和分区容错性。BASE是Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写。
Basically Available
基本可用:通过支持局部故障而不是系统全局故障来实现的。如将用户分区在 5 个数据库服务器上,一个用户数据库的故障只影响这台特定主机那 20% 的用户,其他用户不受影响。
Soft State
软状态,状态可以有一段时间不同步
Eventually Consistent
最终一致,最终数据是一致的就可以了,而不是时时保持强一致。
5.zk是如何保证一致性的
可以看这本书哈~《从paxos到Zookeeper分布式一致性原理与实践》,
也可以看这篇文章:浅析Zookeeper的一致性原理(https://zhuanlan.zhihu.com/p/25594630)
6.你如何设计一个能抗住大流量的系统,说说设计方案
nginx负载均衡,流量防卫兵sentinel,服务拆分,缓存,消息队列,集群、限流、降级这些都可以搬出来啦~
7.有没有了解过缓存策略有哪些
- Cache-Aside
- Read-Through
- Write-Through
- Write-Behind
有兴趣还是可以看看我这篇文章 : 并发环境下,先操作数据库还是先操作缓存?