本文转载自公众号“读芯术”(ID:AI_Discovery)
人工智能,深度学习,这些词是不是听起来就很高大上,充满了神秘气息?仿佛是只对数学博士开放的高级领域?
错啦!在B站已经变成学习网站的今天,还有什么样的教程是网上找不到的呢?深度学习从未如此好上手,至少实操部分是这样。
假如你只是了解人工神经网络基础理论,却从未踏足如何编写,跟着本文一起试试吧。你将会对如何在PyTorch 库中执行人工神经网络运算,以预测原先未见的数据有一个基本的了解。
这篇文章最多10分钟就能读完;如果要跟着代码一步步操作的话,只要已经安装了必要的库,那么也只需15分钟。相信我,它并不难。
长话短说,快开始吧!
导入语句和数据集
在这个简单的范例中将用到几个库:
- Pandas:用于数据加载和处理
- Matplotlib: 用于数据可视化处理
- PyTorch: 用于模型训练
- Scikit-learn: 用于拆分训练集和测试集
如果仅仅是想复制粘贴的话,以下几条导入语句可供参考:
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
至于数据集,Iris数据集可以在这个URL上找到。下面演示如何把它直接导入
Pandas:
iris = pd.read_csv('https://raw.githubusercontent.com/pandas-dev/pandas/master/pandas/tests/data/iris.csv')
iris.head()
- 1.
- 2.
- 3.
前几行如下图所示:
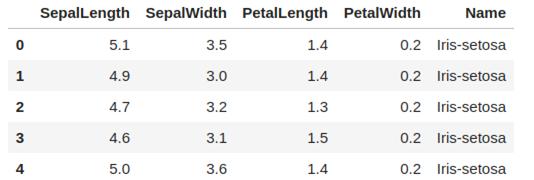
现在需要将 Name列中鸢尾花的品种名称更改或者重映射为分类值。——也就是0、1、2。以下是步骤说明:
mappings = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}iris['Name'] = iris['Name'].apply(lambda x: mappings[x])
- 1.
- 2.
- 3.
- 4.
- 5.
执行上述代码得到的DataFrame如下:
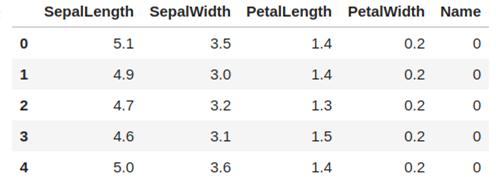
这恭喜你,你已经成功地迈出了第一步!
拆分训练集和测试集
在此环节,将使用 Scikit-Learn库拆分训练集和测试集。随后, 将拆分过的数据由 Numpy arrays 转换为PyTorchtensors。
首先,需要将Iris 数据集划分为“特征”和“ 标签集” ——或者是x和y。Name列是因变量而其余的则是“特征”(或者说是自变量)。
接下来笔者也将使用随机种子,所以可以直接复制下面的结果。代码如下:
X = iris.drop('Name', axis=1).values
y = iris['Name'].valuesX_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=42)X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
- 1.
- 2.
- 3.
- 4.
- 5.
如果从 X_train 开始检查前三行,会得到如下结果:

从 y_train开始则得到如下结果:
地基已经打好,下一环节将正式开始搭建神经网络。
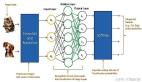
定义神经网络模型
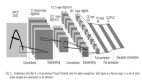
模型的架构很简单。重头戏在于神经网络的架构:
- 输入层 (4个输入特征(即X所含特征的数量),16个输出特征(随机))
- 全连接层 (16个输入特征(即输入层中输出特征的数量),12个输出特征(随机))
- 输出层(12个输入特征(即全连接层中输出特征的数量),3个输出特征(即不同品种的数量)
大致就是这样。除此之外还将使用ReLU 作为激活函数。下面展示如何在代码里执行这个激活函数。
class ANN(nn.Module):
def __init__(self):
super().__init__()
self.fc1 =nn.Linear(in_features=4, out_features=16)
self.fc2 =nn.Linear(in_features=16, out_features=12)
self.output =nn.Linear(in_features=12, out_features=3)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.output(x)
return x
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
PyTorch使用的面向对象声明模型的方式非常直观。在构造函数中,需定义所有层及其架构,若使用forward(),则需定义正向传播。
接着创建一个模型实例,并验证其架构是否与上文所指的架构相匹配:
model = ANN()
model
- 1.
- 2.
在训练模型之前,需注明以下几点:
- 评价标准:主要使用 CrossEntropyLoss来计算损失
- 优化器:使用学习率为0.01的Adam 优化算法
下面展示如何在代码中执行CrossEntropyLoss和Adam :
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
- 1.
- 2.
令人期盼已久的环节终于来啦——模型训练!
模型训练
这部分同样相当简单。模型训练将进行100轮, 持续追踪时间和损失。每10轮就向控制台输出一次当前状态——以指出目前所处的轮次和当前的损失。
代码如下:
%%timeepochs = 100
loss_arr = []for i in range(epochs):
y_hat = model.forward(X_train)
loss = criterion(y_hat, y_train)
loss_arr.append(loss)
if i % 10 == 0:
print(f'Epoch: {i} Loss: {loss}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
好奇最后三行是干嘛用的吗?答案很简单——反向传播——权重和偏置的更新使模型能真正地“学习”。
以下是上述代码的运行结果:
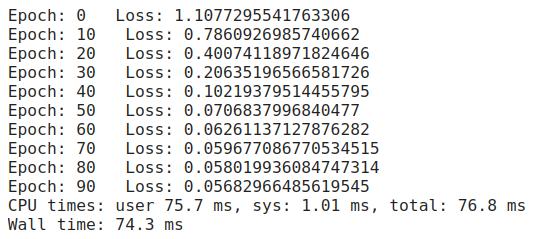
进度很快——但不要掉以轻心。
如果对纯数字真的不感冒,下图是损失曲线的可视化图(x轴为轮次编号,y轴为损失):

模型已经训练完毕,现在该干嘛呢?当然是模型评估。需要以某种方式在原先未见的数据上对这个模型进行评估。
模型评估
在评估过程中,欲以某种方式持续追踪模型做出的预测。需要迭代 X_test并进行预测,然后将预测结果与实际值进行比较。
这里将使用 torch.no_grad(),因为只是评估而已——无需更新权重和偏置。
总而言之,代码如下:
preds = []with torch.no_grad():
for val in X_test:
y_hat = model.forward(val)
preds.append(y_hat.argmax().item())
- 1.
- 2.
- 3.
- 4.
现在预测结果被存储在 preds阵列。可以用下列三个值构建一个Pandas DataFrame。
- Y:实际值
- YHat: 预测值
- Correct:对角线,对角线的值为1表示Y和YHat相匹配,值为0则表示不匹配
代码如下:
df = pd.DataFrame({'Y': y_test, 'YHat':preds})df['Correct'] = [1 if corr == pred else 0 for corr, pred in zip(df['Y'],df['YHat'])]
- 1.
df 的前五行如下图所示:

下一个问题是,实际该如何计算精确度呢?
很简单——只需计算 Correct列的和再除以 df的长度:
df['Correct'].sum() / len(df)>>> 1.0
- 1.
此模型对原先未见数据的准确率为100%。但需注意这完全是因为Iris数据集非常易于归类,并不意味着对于Iris数据集来说,神经网络就是最好的算法。NN对于这类问题来讲有点大材小用,不过这都是以后讨论的话题了。
这可能是你写过最简单的神经网络,有着完美简洁的数据集、没有缺失值、层次最少、还有神经元!本文没有什么高级深奥的东西,相信你一定能够掌握它。