有一个词叫做“三月爬虫”,指的是有些学生临到毕业了,需要收集数据写毕业论文,于是在网上随便找了几篇教程,学了点requests甚至是urllib和正则表达式的皮毛,就开始写爬虫疯狂从网上爬数据。这些爬虫几乎没有做任何隐藏自己的举动,不换IP,不设置headers,不限制速度,极易被有反爬的网站封锁,极易给没反爬的小网站造成流量压力。
后来,他们又不知道看了哪篇文章,知道要使用代理IP,要修改UserAgent。于是,他们真的就只在headers设置UserAgent,其他项一概不设置。你给他指出来,他还振振有词:你看我这样能爬到数据啊,headers里面其他项目没有用。
事实真的是这样吗?
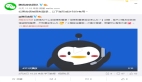
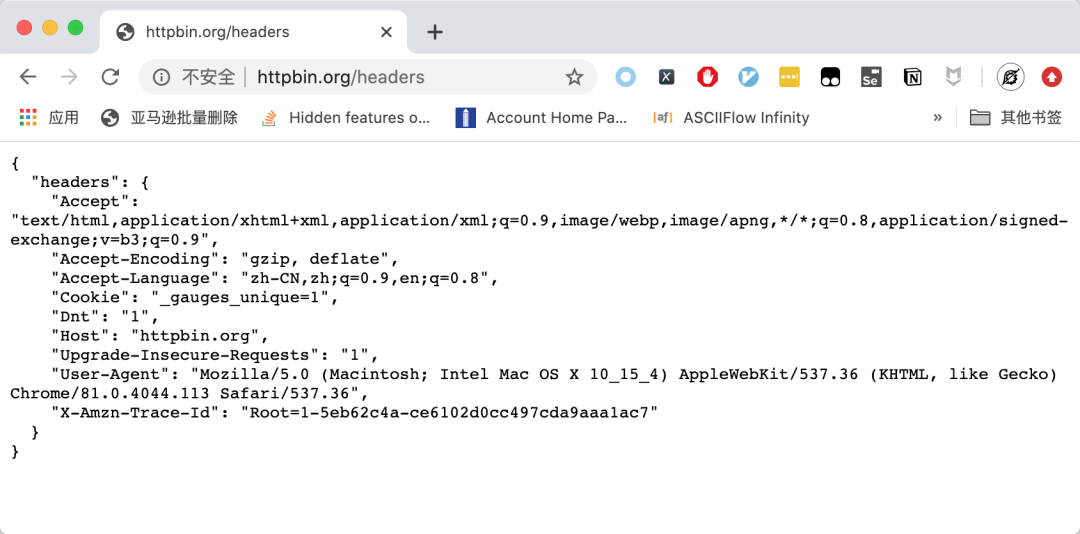
我们来做个实验,首先使用Chrome访问http://httpbin.org/headers 这个网站可以显示当前你的headers。运行效果如下图所示:
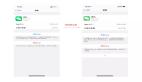
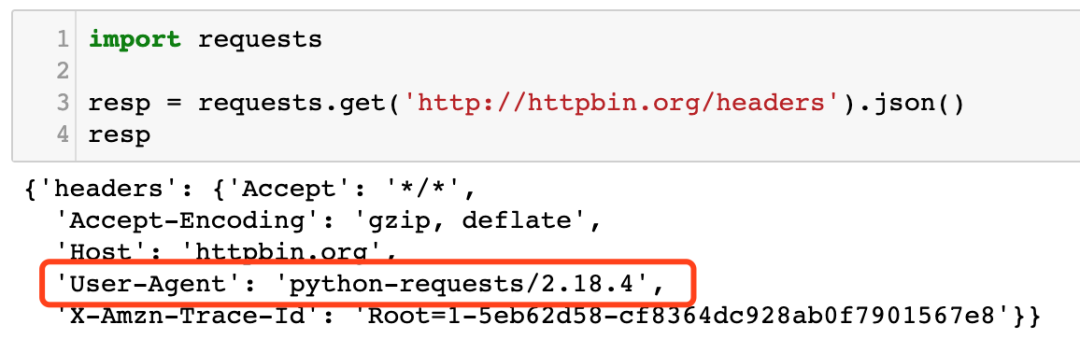
然后,再使用requests不设置headers请求这个URL,运行效果如下图所示:
最后,我们仅仅设置一个UserAgent看看效果:
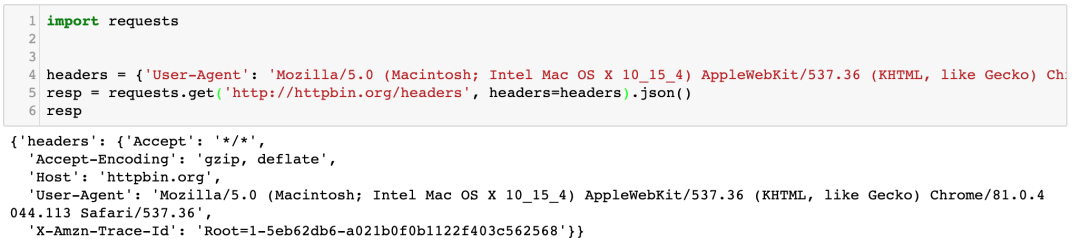
可以看出来,仅仅设置一个UserAgent,与用浏览器访问的 Headers 还是有很多不一样的地方。缺了很多项。网站只需要检测缺的这几项,就能确定你是用程序发起的请求还是用浏览器发的请求。
说回微信网页版的问题。很多人使用wxpy或者itchat这种第三方库通过Python控制自己的微信号,实现很多自动化操作。但不久以后就反馈说自己被限制登录网页版微信了,以为是不是自己的行为被微信发现了,例如一秒钟内发了几十条消息,或者同时回复了好几个人的消息。
但我要说的是,你们太高估自己了,微信要发现你们,根本就不用这么麻烦。它直接检查headers就可以了。
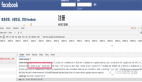
我们来看一下wxpy的源代码中,涉及到网络请求的地方:
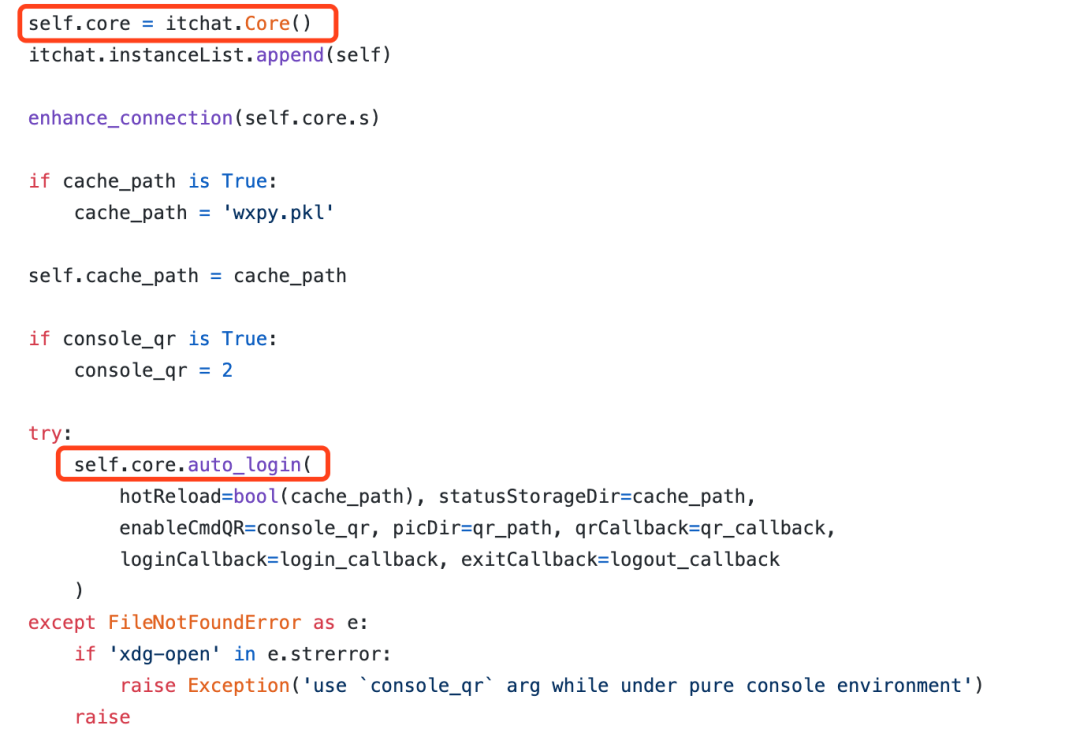
wxpy是基于itchat二次开发的,登录功能是通过 itchat 来实现的。我们再来看看itchat里面发起网络请求的地方:

其中的 self.core.s就是一个 requests 的 Session,如下图所示:
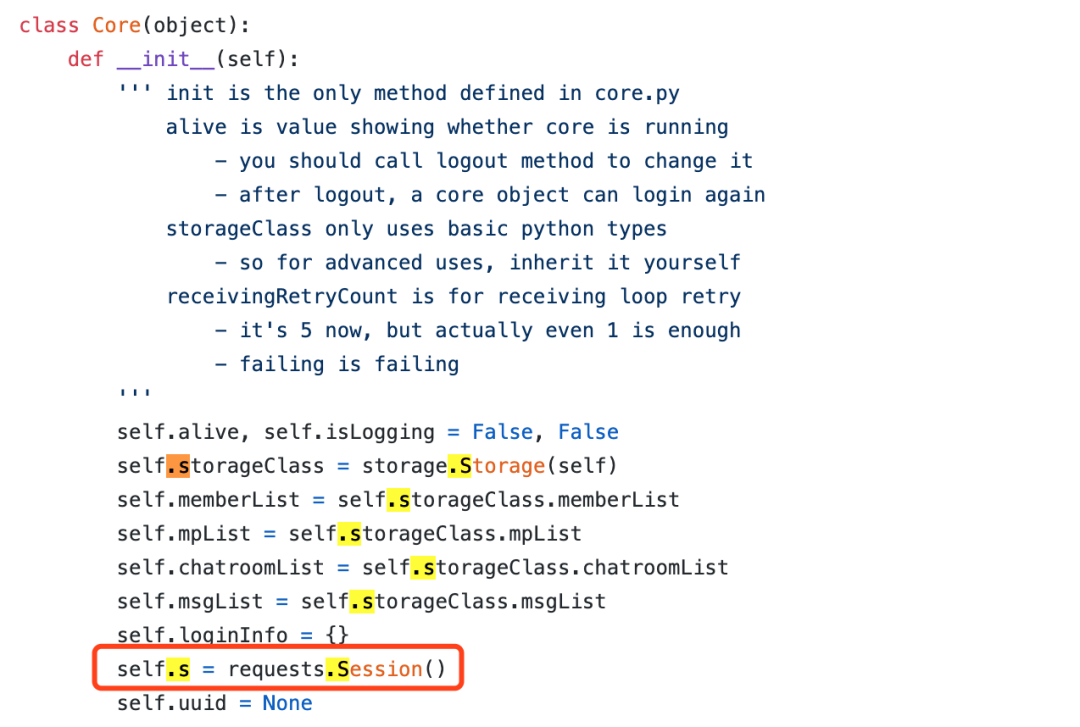
看到了吗?这两个库,他们在headers里面只放了UserAgent,其他字段都没有放。所以在你登录的瞬间,微信就已经知道你这个账号没有用浏览器登录了!
所以,那些用了wxpy或者itchat就被限制登录网页版微信的人,不要怀疑,你们就是被这两个库给害了。这两个库里面涉及到网络请求的相关代码,水平一看就是一个学了两三天爬虫的人写出来的代码。
你用这两个库就是让你的微信号去送死。
不仅仅是这两个库,我们再看看很多人使用的Python 弹幕包,更夸张,在获取斗鱼直播信息的时候,直接用requests请求网址,连headers都没有设置,如下图所示:
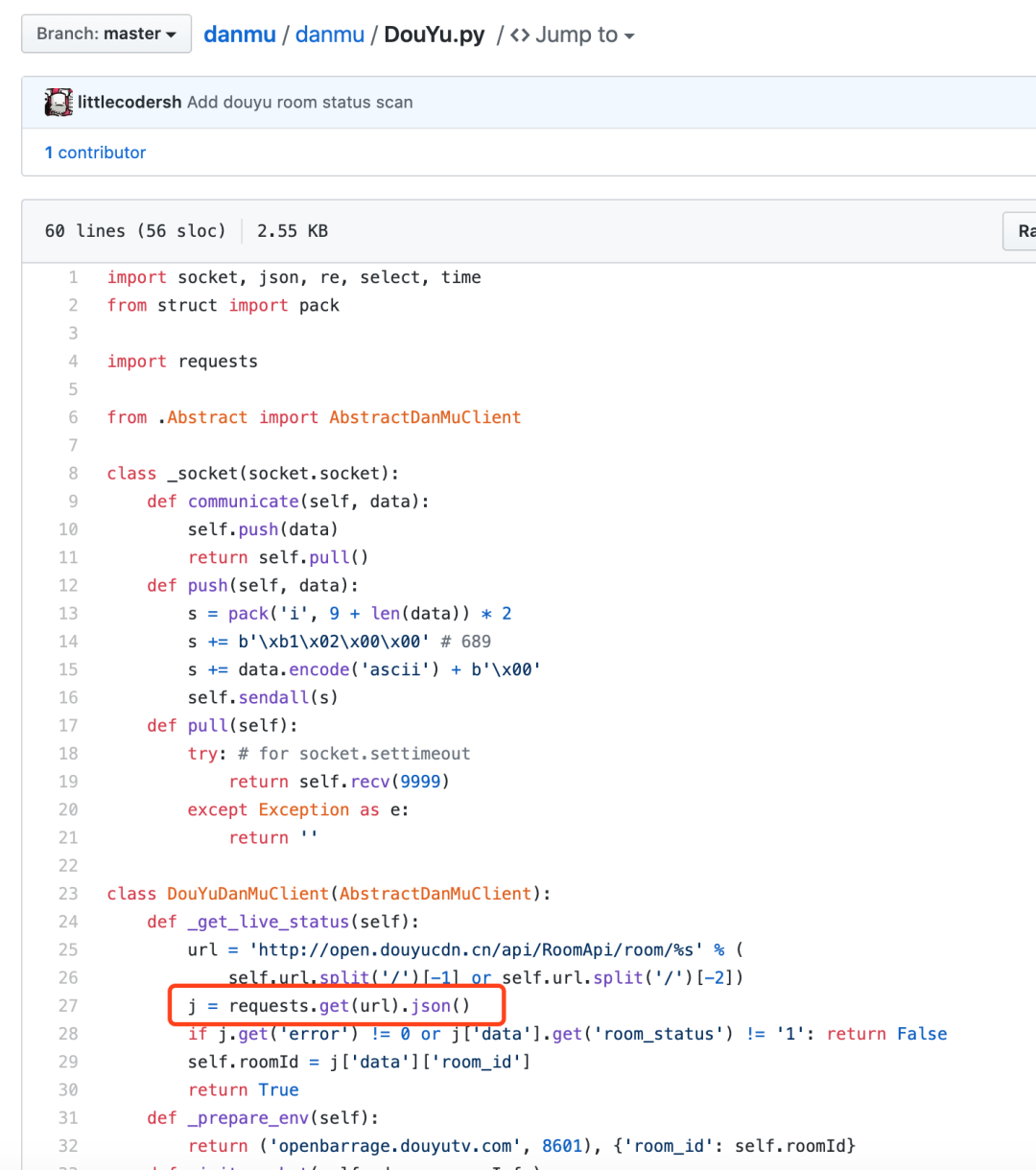
这纯粹就是送死行为。
现在大网站的机器行为对抗团队一般会把检测爬虫与封禁爬虫分开。因为反爬虫策略多了以后,不可避免存在误伤的情况,为了尽可能降低误伤率,检查爬虫时会对请求的可疑性进行打分,当你出现疑似爬虫行为时,给你的请求加上一些分数,某些行为分数高,某些行为分数低。当你总积分达到一定程度时,再调用封禁的流程。
由于 HTTP是无状态的,如果你要爬的网站不需要登录,那么也许你频繁更换 IP 有用(阿布云的代理池就是被这样污染的)。
但是对于微信这种需要登录的情况,你的所有可疑行为的积分都会直接关联到你的这个账号上。于是,一开始可能你用 wxpy 登录网页版微信没问题,这个时候你的可疑性积分还不够高,可能确实有一些老古董浏览器的 Headers 就是少了很多项?但是你已经在怀疑名单里面了。一旦你又出现了其他可疑行为导致可疑性积分继续增加,那么当微信已经可以100%确信你就是用的自动化程序登录网页版微信的时候,封禁你就是自然而然的事情了。