












【51CTO.com快译】Telstra正在其网络数据上运行深度学习算法,以便及早预测设备故障,并找到对付语音和短信骗局的方法。
数据科学(网络)团队经理Tim Osborne近日在IBM的Think2020大会上作了发言,透露了这个代号为Telstra AI Lab即TAIL的项目。
TAIL在一个仍在不断改进的应用数据科学平台上运行,该平台是在IBM的帮助下搭建的。
它结合使用了现有的思科UCS C240和新的IBM Power System AC922用于计算,基于Kubernetes的堆栈在上面,包括用于在Kubernetes上运行机器学习算法的Kubeflow。
Osborne称,TAIL由25位数据科学家和工程师组成的团队提供支持,他们“与整个公司的网络工程人员全面合作,以期解决数据科学方面最具挑战性的问题。”
他称TAIL竭力应对的早期挑战包括网络优化、电源优化、欺诈及与电信有关的其他骗局。
他说:“对我们而言,网络优化是指能够进行预测,检测和诊断我们未能发现的问题。”
“关键是能够在我们的业务运营中取得积极的成果,为客户带来积极的成果,并努力思考我们如何才能拥有自组织的网络。此外能够使用深度学习算法理解机器代码,弄清楚这意味着什么,以便我们能够及早解决故障,这确实很棒,这正是我们眼下在做的事情。”
在电源优化方面,Osborne表示公司在探究供暖通风空调(HVAC)的优化,不过他并没有透露细节。
他还表示,TAIL现用于打击电信骗局。在过去这一年,Telstra及其他运营商在这方面面临监管压力。
“全球移动领域发生了很多骗局——有人通过短信发送骗局;有人打来电话让你回电,而打电话很费钱。我们正在采取相应对策。”
这项工作可以追溯到六个月前,Osborne透露,Telstra已请IBM搭建起了一个应用数据科学平台,使TAIL能够顺利运行。
他说:“我们有人才,我们有使用场景,机会就摆在面前,何况我们有数据。我们就是没有平台。早在2019年12月,我们开始与IBM合作。这种合作绝对堪称典范。”
“我们有共同的终极目标。IBM对获得更多的经验,让客户使用其平台以及Kubernetes和Kubeflow很感兴趣,而我们对在我们公司内使用那些工具并扩大规模很感兴趣。”
“我们现在有一个很出色的机器学习平台,我们的数据科学家现在心满意足。”
Osborne说,数据科学平台使其团队能够根据网络业务的需求迅速调查,并针对实际使用场景迅速扩大规模。
他说:“随着我们的业务变得更受欢迎,我们可以添加更多机器,可以在集群中添加更多机器,并根据需要扩展资源。”
底层揭秘
IBM的AI技术专家Adam Makarucha表示,应用数据科学平台已在去年底今年初部署起来。
它最初基于原生的Kubernetes而建,但是现计划将其迁移到Red Hat的OpenShift容器管理平台,因为OpenShift版本4.3支持Power System。
在硬件方面,Marakucha表示“总共有六台机器和六个节点”。
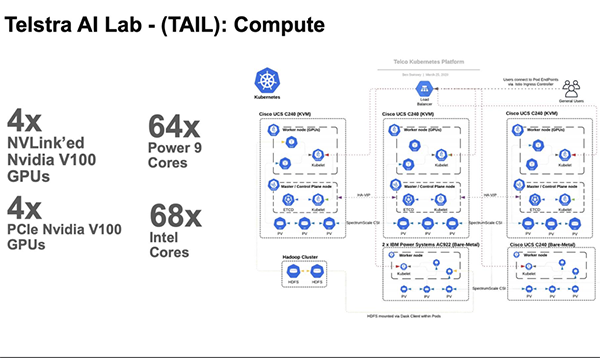
他说:“计算量似乎不大,但是该部署环境的关键是这些节点中每个节点都有GPU加速功能。这实际上意味着该机器的计算和功能总量实际上远超出了6节点系统的容量。实际上,其总性能可能相当于160个节点。该平台总共拥有237.6 Teraflops的[GPU]单精度性能。”
Marakucha称,虽然Telstra想使用Power System AC922,但也想充分使用已购置的思科UCS硬件及其他设备和服务。
Marakucha说:“我们本可以走使用基于x86的集群这条路,但是Telstra希望引入AC922,就因为它们在针对很庞大的数据集和大型模型进行深度学习方面有优势。”
他表示,虽然这种混合环境可能很难管理,但Kubernetes能够承担大部分的重任。
Marakucha还说,该环境已经过配置,对单单一个数据科学家在任何时间可以使用的资源数量作了一番限制,以防资源被独占。
“如果你是数据科学家,可能会这么做:我会试图获得尽可能多的CPU核心和计算资源,即便不会同时使用这些资源。这种环境下的许多数据科学家在做同样的事情,这意味着我们很快耗尽计算资源,因为我们在消耗所有核心。”
“于是我们将核心数量严格限制在两个,这意味着我们有灵活性,因为Kubernetes的优势在于,如果你要求两个核心,起码保证你有两个核心,但又允许你扩展到更多的核心,如果有闲置核心的话。我们只是锁住了一些配置,以防过度配置。”
原文标题:Telstra throws deep learning at its network challenges,作者:Ry Crozier
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】














