鉴于您已阅读本文,因此您的概率基本原理已准备好进行机器学习的概率为100%。
机器学习就是关于做出预测的一切。 从预测具有多种功能的房屋价格到基于单细胞测序确定肿瘤是否为恶性。 这些预测仅仅是预测-输出的值是从数据中找到的相关性得出的-并不是在现实世界中发生的确定性值或事件。
因此,我们可以认为机器学习是在给定一定的输入或公认的相关性的情况下输出最可能或概率性的结果(几乎像条件概率P(x | y)。因此,需要对概率论有扎实的理解才能理解机器学习 在更深层次上;虽然许多使用机器学习的人仅将其用作"黑匣子"(他们不在乎模型如何提出预测,而只是在预测本身),但其他人却在意理解ML模型是如何产生的 它的预测,并利用对ML模型如何学习的理解,以便更深入地了解他们正在研究的过程的机制。
机器学习中的许多"学习"过程实际上是从概率和概率分布中派生的,因此,了解这些概念背后的数学将使我们能够更深入地理解机器学习。
在本部分中,我将介绍高中水平的统计信息-如果您已经熟悉条件概率和高斯分布的简单版本,则可以继续进行下一部分。
想象一下,您正在乘坐飞机,并且正在尝试预测飞机在特定时间到达目的地的可能性。 您需要做的第一件事是了解会改变到达时间的不确定性(波动变量)的来源。 一些示例包括:
- 湍流
- 更多空中交通
- 闪电
- 其他恶劣天气
这称为被建模系统的固有随机性。 其他类型的不确定性源于不完整的可观察性-在我们的情况下,这可能意味着您可能无法预测即将发生的空中交通流量。 最后,建模不完善,就是您遗漏了大量变量的可能性。
上面的每个变量都由一个随机变量表示,该变量可以具有多个值,每个值都有不同的发生概率。
概率密度函数和质量函数分别用于连续函数和离散函数。
例如,如果X是特定量湍流的随机变量,则P(X = x)是随机变量X取该特定值的概率。
认知计算-一种被广泛认为是……的最重要表现的技能
作为其用户,我们已逐渐将技术视为理所当然。 这些天几乎没有什么比这更普遍了……
联合概率分布与正常分布相似,不同之处在于,您现在尝试封装两个变量的随机性,因此
P(x,y)= P(X = x,Y = y)
本质上,这是两个变量采用非常具体的值的可能性。
现在,如果我告诉您在飞机上飞行时到达目的地的概率为0.000000001,您将不相信我,但您必须考虑到有足够的燃料 到那里,飞机已经过检修。
P(您会准时到达目的地|加油,维修已完成)
这称为条件概率。
分布类型
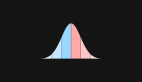
高斯分布
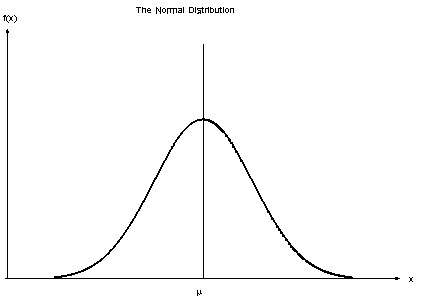
好的-现在有许多数学上表示分布的方法。 最常见的方法是旋转高斯分布(或正态分布),而正态名称是合适的,因为它是最常用于近似其他分布的分布。
您可以使用以下表达式在笛卡尔坐标上绘制方程式:
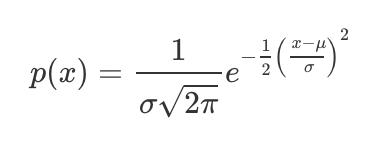
Sigma和µ分别代表总体标准偏差和均值。
想象一下,我们想要一次或三个绘制两个变量的分布。 事情很快就会疯狂起来。 这是二维高斯分布的样子。
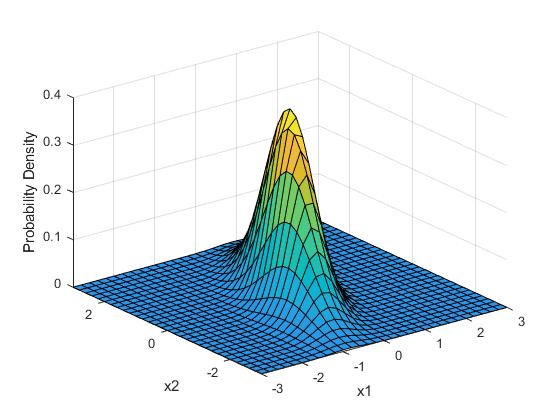
> Two dimensional multivariate gaussian distribution, where x1 and x2 represent the values of the tw
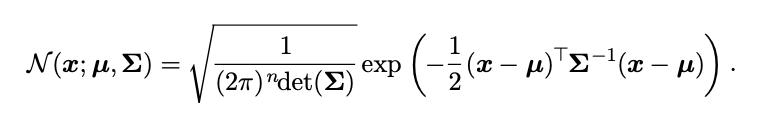
> The equation for a multivariate gaussian distribution
在这里,我们不仅要了解一个变量的"标准偏差",还要了解变量之间的相互关系。 换句话说,回到我们的飞机示例中,如果湍流度更高,这是否意味着坏的可能性更大? 我们使用协方差矩阵,其中协方差由以下公式表示。
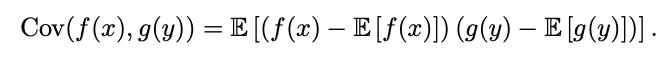
本质上,您是将两个随机变量的标准偏差相乘,以查看它们之间的比例关系(彼此之间的依存程度)。
拉普拉斯分布
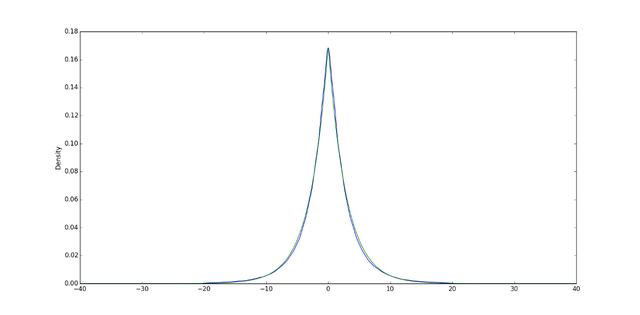
如果我们将高斯分布和拉普拉斯分布视为丘陵,那么高斯分布具有一个平滑的顶点。 换句话说,如果您将球放在顶部,则在加速之前,球会开始平稳滚动。
另一方面,拉普拉斯分布的山顶非常陡峭,放在顶部的球将立即开始加速。
信息论就是关于一组给定的值和概率捕获多少信息。
例如,如果我告诉您您今天要呼吸,会感到惊讶吗? 可能不是,因为这周您有99.99999%的机会还活着。 因此,该信息的信息含量低。 另一方面,其他信息具有更高的信息内容-可能性越小,它们拥有的信息就越多。
例如,如果我告诉你夏天要下雪,那条信息将具有超高的信息含量。
让我们更正式地定义信息(在数学上这意味着什么)。
我们可以通过采用特定概率的负对数来计算信息内容。
现在,夏季实际上下雪的可能性确实很小(例如,下雪的概率为0.0001%,不会下雪的概率为99.9999%)。 因此,我们获得大量信息的可能性非常低。
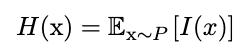
> Equation for self-information content
为了预测包含的平均信息量或预期信息量,我们从分布中的事件中找到预期的信息量。
现在,为什么信息在机器学习中很重要? 有时,我们输入一个概率分布,然后得到另一个输出,这两个都是针对相同的随机变量x,我们想看看分布之间的相似程度。
对于采用分派作为输入的变体自动编码器,尝试在几个潜在变量中进行编码,然后进行解构以尝试重新创建原始分布,请务必查看新分布是否具有更多或更少的信息 比原来的大一号。
我们可以通过检查新发行版是否具有较高的信息内容来检查模型是否"学习"了任何东西。 我们可以使用KL(Kullback-Leibler)散度来度量。
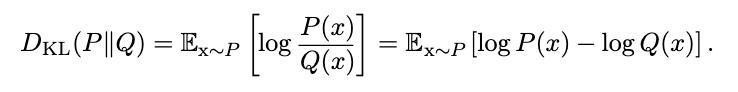
> Equation for Kuller-Leibler Divergence
结构化概率模型
结构化概率模型(具有节点和边)用于表示多个变量和与之关联的条件概率之间的相互作用。
例如,查看下面的结构化概率模型。 节点由小写字母表示,有向边表示条件关系。 换句话说,c取决于b上的a,因为a和b的箭头指向它。
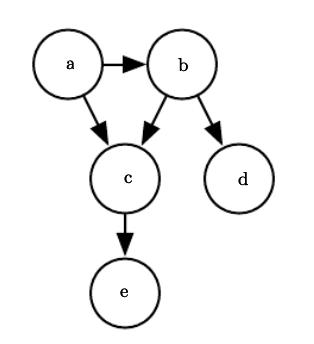
我们可以通过查看每个变量的条件概率乘积来表示找到所有五个变量的某种组合的概率。
"给定"符号右侧的变量表示提供有向箭头的节点。
无向模型不需要定向边缘(带有箭头)。 它们只是在表示依赖关系的变量之间有一行。
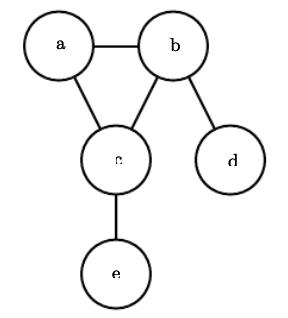
无向模型中的每个集团都由相互连接的节点组成。 例如,在上图中,a,b和c是集团。 每个集团都有与之关联的独特功能,可以从中得出一个因素。
就是这样-您需要了解的有关机器学习概率的全部信息:)