












本系列文字是一位创业者的投稿《面向NLP的AI产品方法论》,老曹尽量不做变动和评价,尽量保持系列文章的原貌,这是本系列的最后一篇——第5篇
语音/对话式交互是一件非常有挑战性的设计,极少有业务能一蹴而就。笔者所在的公司,过往开发了十几个多轮语音交互技能,平均算下来,首个BOT上线后,差不多得有半年时间进行迭代,才能够有稳定的,比较好的数据表现。
迭代优化的方法论有很多种,本文着重讲,如何通过数据分析(也是笔者最喜欢用的),去迭代语音/对话式交互技能。
先引用此前笔者写的《NLP方法论:如何设计多轮语音技能》一文,最后一个模块的两句话:
“上线前,依照流程标准,已经做好了数据埋点,并搭建好了完整的用户对话log分析后台。
上线后,通过业务后台观察业务数据,和实际真实用户的表述,继而迭代技能,提升体验。”
工欲善其事,必先利其器,强大的数据后台集群,是让业务变得越来越好的神兵利器。此前笔者也写过如何搭建数据后台,这里就只讲,在已有后台的情况下数据分析思路。
一个AI语音交互助手,核心价值是帮助用户完成任务,而在完成任务的过程中,又有着各种阻碍影响到AI助手为用户服务,伤害体验,影响价值交付。所以我们解决问题的思考点在于:如何从业务过程中,通过数据发现各种问题。
问题一旦能被发现,就自然有解决方案。
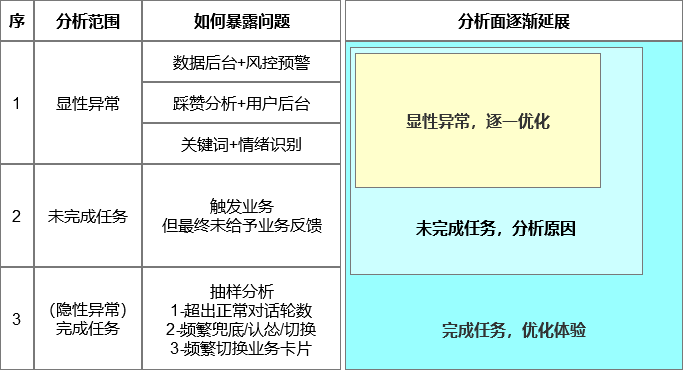
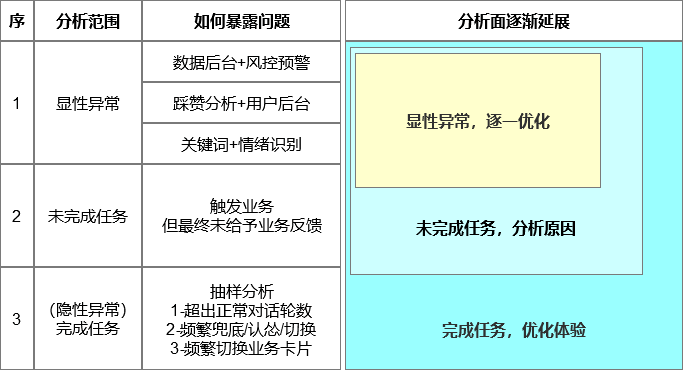
从分析角度,笔者分为三层(递进延展):
- 用户在使用AI助手的过程中遭遇过哪些显性问题。
- 为什么AI助手最终没有帮助用户完成任务。
- 如果用户最终完成了任务,使用过程中有哪些不爽。
下图是全文逻辑结构。
一、如何发现显性问题
所谓显性异常,指的是那些明显影响用户体验,最终影响AI助手帮助用户达成任务目标的问题。各家公司都能够通过基本的规则设计发现问题,只要能发现问题,就有解决方案,各个业务设计者无非是,在有限条件下做业务权衡取舍。
来源1、数据后台+风控预警
上线前一定要做好的数据埋点工作行为。例如:网络延迟、响应慢、异常、软硬件故障、崩溃……此前在数据字典一文中也统计了这种情况(字段有删减)。
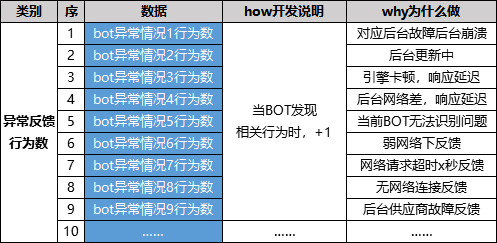
既要统计行为数,也要统计人次,行为数代表着一共发生了多少次这类问题,人次代表着影响了多少个用户(即范围),事先设定好阈值,达到了一定情况就邮件/短信预警。

BOT业务一旦异常,就会迅速的被发现。当时间拉长到3个月,产品里出现的各个方面的异常问题也能够得出一条曲线,问题一暴露,针对性进行优化即可。
这类问题,属于AI助手的稳定性考量范畴,但是一旦发生,极为严重,基本上任务就没法完成了。
来源2、踩赞分析+用户后台
DUI一般会设计这类功能反馈,以出门问问举例,每次AI完成一句话后,底部都会有一个赞或者踩的功能。
同时也直接把客服模块放到了较深的一个层级,用户在使用过程中,向我们提出的各种建议,找客服人员投诉什么的。
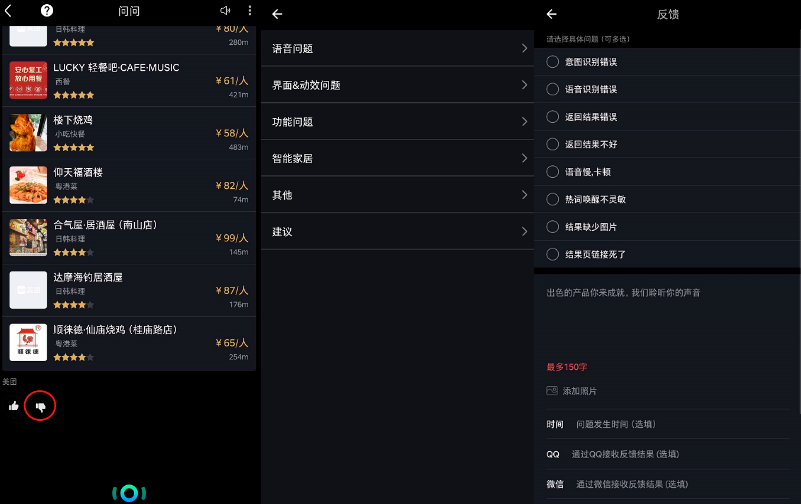
出门问问这一块做得比较细致,页面层级比较深,期望用户能够给予更精准的反馈,到底自己的AI助手哪里做的不够好。
但是实际上,只有少量的用户,会帮你做思考和分类,(我自己就是点个踩就跑掉,才不帮你做分类呢,我就表达不爽,问题出在哪你自己想去),甚至你也拦不住用户瞎填,这一块完全就是把压力推到用户那边,期望用户付出更多的成本帮助定位业务问题。
但从另外一个角度而言,不也是有相当一部分用户,认真分类填写了,节省了我们的压力么?你看这其实是设计选择,没有好坏之分。
用户的每次业务反馈都会在后台出现,不管用哪种方式收集,都能够以埋点的方式暴露出问题,暴露的人越多,这一块的问题就越值得重视。自然这种问题类型,也会长期积累,跑出一个问题分布图。
来源3、关键词搜索+情绪识别
前面的基本是用户使用GUI交互行为表达了不爽,但是这个范围依旧不够大,我们需要继续延展。
如果是,用户基本上不给点触反馈、产品没有设计踩的功能,亦或者是纯语音交互,怎么抓出来问题呢?
这一块就能够用得到对话log分析了,不讨论隐私问题,基本上用户跟AI助手发生的每一句语音,对话,点触行为,都会生成log。

一些关键词搜索,必然是用户表述的一些话,很容易就推理出,用户必然受挫,只不过情绪程度不一样。
另外一种就是使用模型算法,一般是用于舆情监控用的,可以抓出来用户的积极/消极情绪和言论。有很多大厂都开放这类业务,不避嫌的话埋入自己的业务模块里面就好,当然你也可以自己训练。
找到这些东西之后,然后分析这些话术出现在哪些技能里面,分布在哪个环节上,问题就自然暴露出来了。
二、是什么导致任务未完成
用户使用AI助手,就是为了完成任务的。
对话过程中,如果用户启动了某项业务,最终(不管结果是好还是坏,用户是否满意)没有结果,就是巨大的问题。
此处定义:任务未完成,指的是未成功填充全部槽位,用户最终没有得到结果。例如:买电影票和买机票没到确认下单环节,问天气,最终没给到天气结果等。
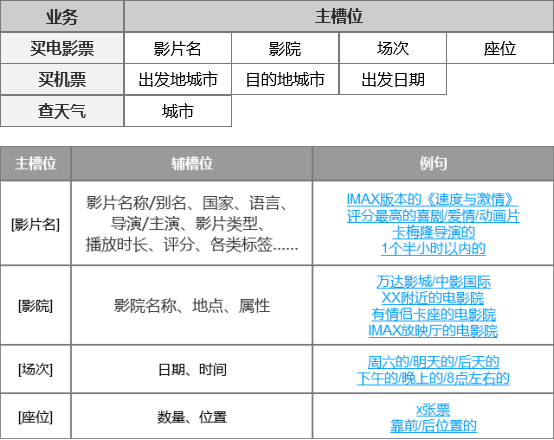
越是槽位越多的业务,越值得好好打磨,毕竟轮次越多,意外就越多,用户随时随地会离开。
一般AI助手返回结果给用户都会有一个标记。所以,此处的规则就比较容易定义。在一次会话行为中,触发了某项技能,最终该项技能没有(标记)返回结果。这类问题就值得抓出来,进行定位分析。
数据提出来还要进行一些清洗行为,例如:有些是失误触发,暴露的是中控错误理解,错误分配。有些用户单单是启动了该技能,最后直接退出,没有超过1轮以上的对话,这些就不值得算进统计项内。
找出正常的用户后,进行分析统计,比如4个槽位,仅仅填充了2个,用户努力对话几轮后,放弃掉了,哪里卡住了,哪里半途放弃了,这种就非常值得研究。很容易形成一个数据漏斗,看看问题主要集中出现在哪。
先解决有无结果的问题,然后才有条件去讨论结果优劣。
三、如何发现隐性问题
很多时候,用户即使是磕磕碰碰,但最终还是可以完成任务,这些问题都是隐形的,那么如何发现这些对话中的“磕磕碰碰”呢?
磕磕碰碰影响体验,这种感受多了,用户自然放弃。要发现这类问题,我们就得使用另外一项业务工具,对话log分析后台。
讨论之前,我们先明确一个概念:会话行为,也称之为session。(虽然是业内大家都懂的,但可能定义不一样,文章内还得解释下。)
从进入到离开称为一次会话行为,x分钟(自定义)未检测到用户的对话,算作一次会话行为的结束。
用户一天内可产生x次会话行为,每次会话行为可能触发1~y个业务,并进行z个对话轮次。
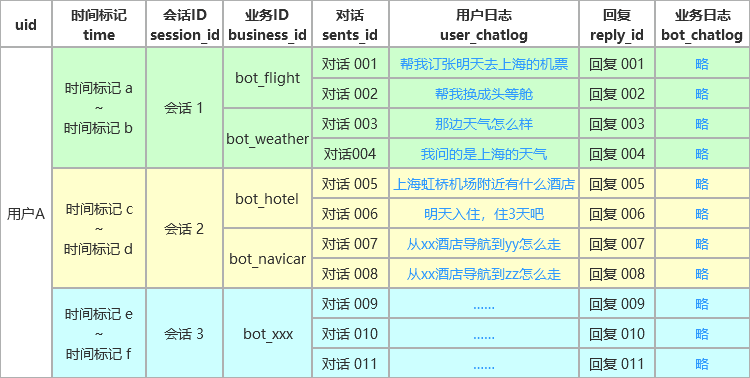
以用户A举例,该用户在当天3个不同的时间段,产生了3次会话行为,总共激活了5个业务,总计产生了11句对话轮次。
而我们的对话log分析后台,就能够以session为单位,还原用户的对话log,并解析在这次会话行为中,用户的表述和AI的理解。

简单来说,用户在一轮对话过程中,触发了什么技能,AI是如何理解这句话的意图,并基于怎样的业务逻辑进行回复,(比如:获得槽位后AI继续追问,不满意展示结果频繁更换槽位,切换到其他技能)都可以通过这个工具进行展示和统计。
为了帮助大家理解,引用此前写过的文章中的例子。
“帮我找个好看点的/有内涵的/羞羞的电影”“我想看关于海战的电影”“帮我找一个高大上的电影院”“附近方便停车么”“我想选一个靠门的座位”“这个电影院能办理会员卡么”
当AI遇见这类问题无法问题,会出现如下几种结果。
无法满足需求,漏给兜底闲聊。无法识别意图、触发认怂话术。
兜底闲聊能接上话就好,一般AI认怂话术是,“抱歉我不明白,请对我说blablabla……”
如果上面的例子比较扯的话,来看下面在买电影场景下正常一些的例子。
“有没有斯皮尔伯格导演的”“我想看速激7”“有没有便宜点的”“我要倒数第三排中间的座位”“有没有适合情侣去的私人电影院”
这些又回归到业务设计上,就完全是业务以及语义覆盖问题了。
此时,我们可以发现,在一次会话过程中,频繁出现兜底,频繁切换业务,频繁认怂……这些都是非常影响用户体验的。
我们只需要设计一个抽样规则,即,在一组会话中,若兜底大于x,切换业务大于y,认怂行为大于z,可单独抽样,可叠加抽样,就很容易筛选出对应的问题了。
同时我们还能对用户的行为进行抽样分析。
个人认为,能完成下单行为的用户,是真需求的用户,他们的对话行为的可信度非常高,如此可以规避掉那些随便试试的用户,类比就是逛淘宝但是不买的用户。
例如:买飞机票这件事,最短路径是3轮对话完成下单付费行为,最长的是10几轮后才完成下单付费行为。为什么会有10几轮呢?每个用户不一样,这个就得进一步去统计分析了。
比如我们可以统计出,过往x天(一般以BOT版本为时间周期),所有完成订单行为的用户,在指定业务下的平均对话轮数。用这个基准作为比较,去发现问题。
提供几个笔者的分析案例,也是此前的一些文章里面提到过的。
案例一(买飞机票时,用户切换技能后下单)
用户在买飞机票的时候,我们发现相当一部分用户会(担心延误)查看天气,这个是用户的购买决策依据,所以这个就给了我们启发,不要让用户问,在查询机票的时候,就直接一并显示天气情况了,如果有影响飞行的天气,同时根据两个城市的距离测算,给予一个火车/打车出行方式,给用户做选择。
同理推理出,在使用其他技能的时候,一定会有关联查询的,这就是通过分析得出的一个小优化点。这些都是通过数据分析暴露出使用习惯,而做出的优化行为。
案例二(买电影票时,用户口语习惯)
买电影票刚刚上线那段时间,发现大量用户在填充电影名词槽那里卡住了。
《速度与激情8》刚刚上映,用户会表述是我想看速度与激情、速激、速8等等;《魔童哪咤》上映的时候,用户的表述是,我想看哪咤的电影;《叶问3》上映的时候,用户的表述会是,叶问。甚至是甄子丹的那个电影;
而AI先提取对应的影片名,然后交给接口方去完成查询行为,只有正确填充“指定电影的全称”才能够可查询成功,所以此处就需要做映射关系的特殊处理。在定电影票例子中,十分考虑场景和时效性,也就是说,用户在不同的时间点,说我要看《某》系列电影的时候,口语上大概率是绝对不会带上第几部的。
只要能暴露问题,就会有解决方案。
案例三(买电影票时,用户的交互习惯)
我们在设计电影票技能的时候,内部曾经讨论到,如果用户需求明确,且一口气完整满足4个词槽,是否应当直接给予结果?例如:我帮我买2张《魔童哪咤》的电影票,附近找个最近的电影院,晚上8点钟左右开场的,随便什么座位都行。
为了完成这个,我们花费了不少精力。从我们后台的实际数据表现去看,实际上用户并不会这么说,很少有用户做多个复合条件叠加查询的,且从来没有用户会一口气说出4个词槽!可以明确一个结论,我们此前的的一部分工作被浪费掉了!
案例四(某一类业务用户筛选习惯)
产品人员看自己负责的业务模块,比如下图。展示的是:某个单位时间内,多少用户,使用了XX业务,中间更换了多少意图,最终完成下单行为。
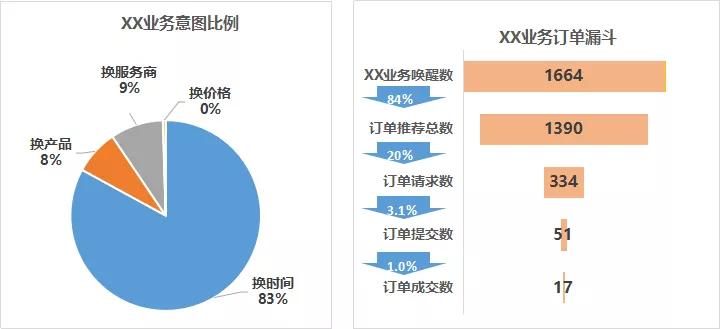
比如定个酒店(这种非标准品确实很难搞),用户会就自己在意的查询条件,反复进行筛选行为,导致对话变得非常长。这个能暴露出用户在意什么,我们就可以基于用户特别在意进行优化了。
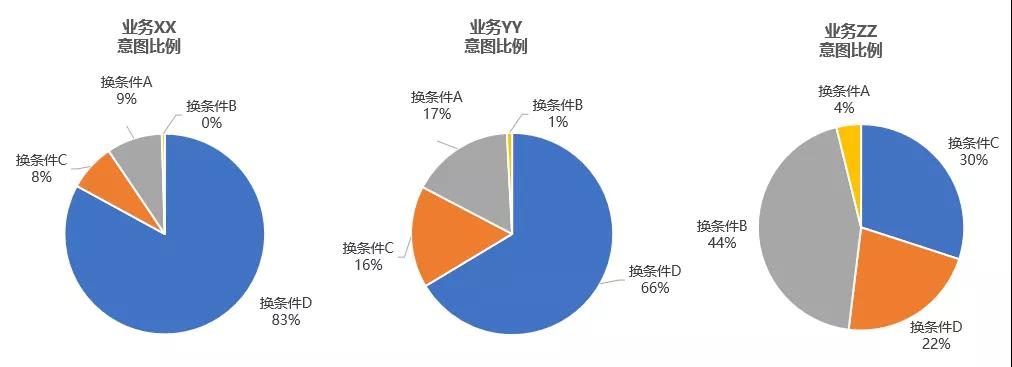
长期使用对话log分析后台,就能够加深用户使用的真实理解,我才能够写出《如何评测语音助手的智能程度(1)意图理解》这类受各位内行认同的文章。
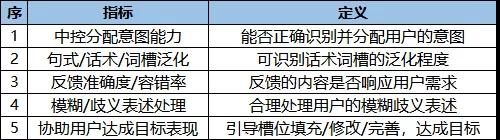
文末总结
其实很多的公司都在做数据分析,但是分析的范围、颗粒度、效率都不一样。
有了诸多业务后台,数据分析才能够得以开展。
有些后台能直接呈现问题(看趋势,看分布,看漏斗),有些问题则需要跟剥洋葱一样,一层层的做抽样、对比和验证。
这中间最难的就是,虽然AI助手帮助用户完成了任务,但是用户完成任务的整个过程是黑盒的,你不知道用户爽或者不爽,而针对用户的对话log进行抽样分析,就能够快速找到用户使用过程中的那些不爽点,使用习惯等等等等。
还是那句老话,只要问题能够暴露出来,解决方案就是在有限条件下做业务权衡取舍。
出于公司业务隐私保护,本文不适合展示太多的实际业务图表,希望各位理解。但是方法论都是共通的,我可以随便换任何业务的任何案例,其实这一块也不难,做互联网的时候数据分析技能过关,切换到AI领域也是一样的,技能可以应用于很多行业。
而做数据分析和做工具是两件事,后者可能是诸多AI公司需要考量的事情。
欢迎各位同学与作者进行讨论,一起精进专业。
【本文来自51CTO专栏作者“老曹”的原创文章,作者微信公众号:喔家ArchiSelf,id:wrieless-com】
















