本文转载自公众号“读芯术”(ID:AI_Discovery)
Python出圈了,似乎现在人人都在学Python,朋友圈的课程广告遍地跑,小学生都看起了编程入门。的确,Python是目前公认的最通用的编程语言,以其易理解易操作的优势攻占了每一个职场人大学生必备技能榜单。
学会Python确实能协助你高效工作。但学了是一回事儿,会了是另一回事儿,不是每个人学过Python的人都能玩得转它。以下几个小技巧,能让你离玩转Python更进一步。
把不常用的类别整合成一个
有时你会得到元素分布不均的栏,少有的类别也是仅仅存在而已。通常会希望能将这些类别合并为一个。
df.artists.value_counts()
- 1.
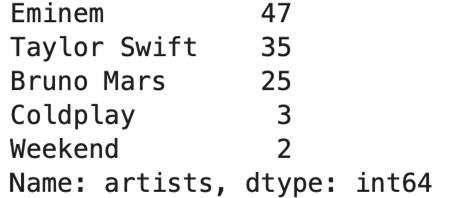
要将Coldplay和Weekend合并到一个类别中,因为它们对数据集的影响微乎其微。该怎么做?
首先,找到不想改变的元素,比如Eminem,TaylorSwift和BrunoMars:
myList =df.artists.value_counts().nlargest(3).index
- 1.
使用where()函数替换其他元素
dfdf_new = df.where(df.artists.isin(myList),other='otherartists')
df_new.artists.value_counts()
- 1.
- 2.

这便是按要求修改后的更新列。
查找列表的新元素
给定两个不同的列表,要求找到一个列表中有但另一个列表中没有的元素时,参照这两个列表:
A = [ 1, 3, 5, 7, 9 ]
B = [ 4, 5, 6, 7, 8 ]
- 1.
- 2.
为了找到列表A中的新元素,我们取列表A与列表B的集合差:
set(A) - set(B)
- 1.
![]()
值1、3和9只出现在列表A而不出现在列表B中。
摆脱警告
运行代码时,经常会收到很多警告。没过多久它就开始使人恼火。例如每当导入朝代时,可能会收到警告(FutureWarning)消息

可以用下述代码隐藏所有警告。请确保其写在代码顶部。
import warnings
warnings.filterwarnings(action='ignore')
import keras
- 1.
- 2.
- 3.
这将有助于在整个代码中隐藏所有警告。
Map() 函数
map()函数接受函数(function)和序列(iterable)两个参数,返回包含结果的映射:
map(func,itr)
- 1.
func 是指接收来自映射传递的给定序列元素的函数。
itr是指可以被映射的序列。
def product(n1,n2):
return n1 *n2 list1 = (1, 2, 3, 4)
list2 = (10,20,30,40)result = map(product, list1,list2)
list(result)
- 1.
- 2.
- 3.
- 4.
![]()
开始解码。
Product函数接受两个列表,并反馈两个列表的乘积。列表1和列表2是充当map函数序列的两个列表。map()集product函数和序列于一身→列表1和列表2,以及反馈两个列表的乘积作为结果。
Map + Lambda组合
可以使用lambda表达式修改上述代码,以替换product函数:
list1 = (1, 2, 3, 4)
list2 = (10,20,30,40)
result = map(lambda x,y: x * y, list1,list2)
print(list(result))
- 1.
- 2.
- 3.
- 4.
Lambda表达式有助于降低单独编写函数的成本。
启动、停止和设置
Slice(start:stop[:step])是通常包含部分序列的对象。
- 如果只提供停止,则从索引0开始生成部分序列直到停止。
- 如果只提供开始,则在索引开始之后生成部分序列直到最后一个元素。
- 如果同时提供开始和停止,则在索引开始之后生成部分序列直到停止。
- 如果起始、停止和步骤三者同时提供,则在索引开始之后生成部分序列直到停止,并增加索引步骤。
x = [ 1, 2, 3, 4, 5, 6, 7, 8 ]
x[ 1: 6: 2]
- 1.
- 2.
![]()
上面的代码中,1是开始索引,6是停止索引,2是步骤索引。这意味着从指数1开始到指数6停止,步长为2。
还可以使用[::-1]操作翻转列表:
x[::-1]
- 1.
![]()
没错,通过开始、停止和步骤操作,很容易就可以将整个列表进行逆转。
组合Zip和Enumerate
zip和enumerate函数常用于for循环,两个一起用就更精彩了。它不仅可以在单个循环中迭代多个值,而且可以同时获得索引。
NAME = ['Sid','John','David']
BIRD = ['Eagle','Sparrow','Vulture']
CITY =['Mumbai','US','London']for i,(name,bird,city) inenumerate(zip(NAME,BIRD,CITY)):
print(i,' represents ',name,' ,',bird,' and ',city)
- 1.
- 2.
- 3.
- 4.

Zip函数可以将所有列表合并为一个,以便同时访问每个列表,而Enumerate函数协助获得索引以及附加到该索引的元素。
随机抽样
有时会遇到非常大的数据集,因而决定处理数据的随机子集。pandas数据框的sample函数可以实现更多的功能。不妨看看在上面已经创建过的歌星数据模型。
df.sample(n=10)
- 1.
这有助于获取数据集里随机的10行。
df.sample(frac=0.5).reset_index(drop=True)
- 1.
分解上面的代码,frac参数取值在0到1之间,包括1。它占用分配给它的数据流的一部分。在上面的代码片段中指定了0.5,因此它将返回size→0.5*的随机子集
你能看到前面的reset_index函数。它有助于适当地重排索引,因为获取随机子集时,索引也会被重新排列。
保留内存
随着编程的深入,你将意识到记住内存高效代码的重要性。生成器是返回我们可以遍历的对象的函数。这有助于有效利用内存,因此它主要用于当在无限长的序列上迭代。
def SampleGenerator(n):
yield n
nn = n+1
yield n
nn = n+1
yield ngen = SampleGenerator(1)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
Yield 语句暂停函数,保存其所有状态,并在以后的连续调用中继续执行。
print(next(gen))
print(next(gen))
print(next(gen))
- 1.
- 2.
- 3.
如你所见,yield保存了前一个状态,而每当我们调用下一个函数时,它都会继续到下一个返回其新输出的yield。
通过添加在generator函数内无限运行的while循环,可以迭代单个yield。
def updatedGenerator(n):
while(1):
yield n
nn = n + 1
a = updatedGenerator(1)for i in range(5):
print(next(a))
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
While语句可以反复迭代相同的yield语句。
救世主Skiprows
重头戏压轴出场!要读取的csv文件过大,以至于内存不够用?Skiprows可以轻松解决。
图源:unsplash
它可以指定需要在数据框中跳过的行数。
假设有个100万行的数据集,不适合你的内存。如果分配skiprows=0.5 million(跳读50万行),在读取数据集的时候就会跳过50万行,这样就可以轻松地读取数据集的子集。
df = pd.read_csv('artist.csv')
df_new = pd.read_csv('artist.csv',skiprows=50)df.shape,
df_new.shape
- 1.
- 2.
- 3.
![]()
在上面的代码片段中,df表示包含112行的数据集。在添加了skiprows=50(跳读50行)之后,它跳过了数据集中的50行,从而读取了62行作为新数据集。
破案啦!编码效率提升一大截的秘密就在于此。