本文转载自公众号“读芯术”(ID:AI_Discovery)
数据科学领域如此之广,鲜少有人能精通所有语言、数据库,笔者尽管已经从事了该行业数年之久,但仍然所知不多。学无止境,变得优秀的方法就是不停下学习的脚步。
在Pandas中,一些函数意义纯粹,但也有一些函数指的是使用Pandas的方式,以及为什么一种方法比另一种更好。这儿有一些节省大量的时间和精力Pandas函数和使用方法,这些效率惊人的神器千万不要错过。
itertuples()
确实,它并不是纯粹的函数,而是指使用Pandas的更有效方法,是循环访问数据集的快捷方法。在花时间理解注释部分之前,可以用更有效的方法计算总列值,在此笔者仅提出一些要点。
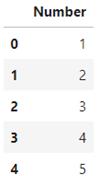
下面是一列简单数据集,数字范围为1到1百万。
- df =pd.DataFrame(data={
- 'Number': range(1, 1000000)
- })
这是前几行的示例:
现在列举一个错误的方式。输入一个总计变量并将其设置为0. 然后,通过使用iterrows()循环访问数据集,并在total的基础上增加当前行的值,与此同时统计操作时间。以下是代码:
- %%timetotal= 0for _, row in df.iterrows():
- total += row['Number']
- total>>> Wall time: 18.7 s
这项小小的操作历时将近19秒,而现在有一个更快捷的方法,与上述操作大致相同,但要加iteruples 而不是 iterrows:
- %%timetotal= 0for row in df.itertuples(index=False):
- total += row.Number
- total>>> Wall time: 82.1 ms
笔者没有计算时间,但可以看到操作速度提高非常明显。下次执行循环时请记住这一点。
nlargest()和nsmallest()
笔者计算了两个纬度/经度对之间的距离(以公里为单位)。那是第一步操作,第二步是选择距离最小的前N条记录。
输入-nsmallest()。nlargest()将返回N个最大值,而nsmallest()将恰好相反。
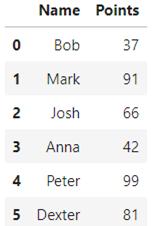
看看它的实际结果。在实际操作中,笔者准备了一个小的数据集:
- df =pd.DataFrame(data={
- 'Name': ['Bob', 'Mark', 'Josh','Anna', 'Peter', 'Dexter'],
- 'Points': [37, 91, 66, 42, 99, 81]
- })
结果如下:
现在该数据集不是仅仅6行,而是包含了6000行,为了找到表现最好的学生,即分数最高,一种方法是这样的:
- df['Points'].nlargest(3)
但这不是最佳解决方案,它会导致以下结果,没有清楚显示真实姓名:
改善方法如下:
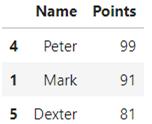
- df.nlargest(3,columns='Points')
怎么样,是不是看起来更棒了:
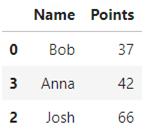
以几乎相同的操作来找到3个表现最差的学生-使用nsmallest()功能:
- df.nsmallest(3,columns='Points')
输出结果如下:
cut()
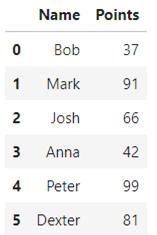
这一部分将继续使用上一部分中的数据集,来回顾一下:
- df =pd.DataFrame(data={
- 'Name': ['Bob', 'Mark', 'Josh','Anna', 'Peter', 'Dexter'],
- 'Points': [37, 91, 66, 42, 99, 81]
- })
cut()函数的基本原理是将值分为不同的区间。下面是最简单的示例,将从Points属性创建两个容器:
- pd.cut(df['Points'],bins=2)
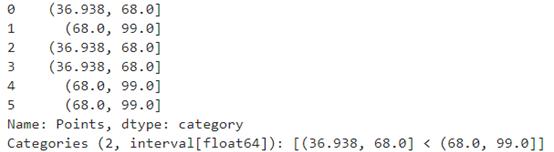
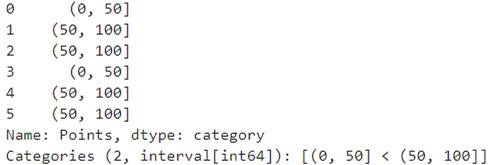
现在还看不出效果。但是如何输入从0到50的区间,以及第二个从50到100的区间呢?听起来有点麻烦。以下为代码:
- pd.cut(df['Points'],bins=[0, 50, 100])
但是需要注意的是,您要显示的是Fail而不是(0,50],要显示Pass而不是(50,100]。你需要这样做:
- pd.cut(df['Points'],bins=[0, 50, 100], labels=['Fail', 'Pass'])

对于刚入门的程序员,这些功能将有助于节省时间和精力;如果你是资深程序员,本文或许能帮你加强对这些函数的了解,避免每次都得从头开始捋,因为这样毫无意义。