本文转载自公众号“读芯术”(ID:AI_Discovery)
很多面试官都喜欢问这个问题:“假设我是个5岁的小孩儿,请向我解释[某项技术]。”给幼儿园的小朋友讲清楚机器学习可能有点夸张,实际上这一问题的要求就是,尽可能简单地解释某一技术。
这就是笔者在本文中尝试做到的事。笔者将解释什么是机器学习以及不同类型的机器学习,再介绍常见的模型。本文里,笔者不会介绍任何数学运算,小白请放心食用。
对于没有或几乎没有数据科学背景的成年人来说,它应该是容易弄懂的(如果不能,请在评论区告诉我)。
机器学习的定义
机器学习图
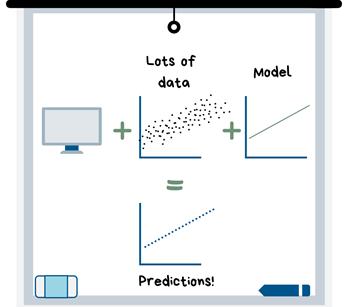
机器学习是指将大量数据加载到计算机程序中并选择一种模型“拟合”数据,使得计算机(在无需你帮助的情况下)得出预测。计算机创建模型的方式是通过算法进行的,算法既包括简单的方程式(如直线方程式),又包括非常复杂的逻辑/数学系统,使计算机得出最佳预测。
机器学习恰如其名,一旦选择要使用的模型并对其进行调整(也就是通过调整来改进模型),机器就会使用该模型来学习数据中的模式。然后,输入新的条件(观测值),它就能预测结果!
有监督机器学习的定义
监督学习是一种机器学习,其中放入模型中的数据被“标记”。简单来说,标记也就意味着观察结果(也就是数据行)是已知的。
例如,如果你的模型正尝试预测你的朋友是否会去打高尔夫球,那么可能会有温度、星期几等变量。如果你的数据被标记,那么当你的朋友真的去打高尔夫了,你也会有一个值为1的变量,当他们没有去打高尔夫,变量的值则为0。
无监督机器学习的定义
在标记数据时,无监督学习与有监督学习恰好相反。在无监督学习的情况下,你不知道朋友是否会去打高尔夫球——这都由计算机通过模型找到模式来猜测已经发生了什么或预测将会发生什么。
有监督机器学习模型
1. 逻辑回归
在遇到分类问题时,可使用逻辑回归。这意味着目标变量(也就是需要预测的变量)由不同类别组成。这些类别可以是“是/否”,也可以是代表客户满意度的1到10之间的数字。
逻辑回归模型用方程式创建包含数据的曲线,然后用该曲线预测新观测的结果。
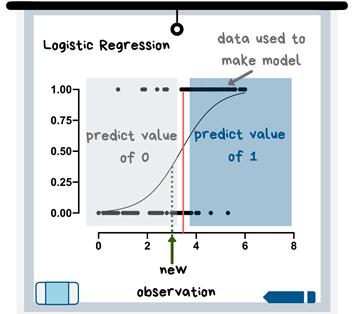
逻辑回归图
上图中,新观测值的预测值为0,因为它位于曲线的左侧。如果查看此曲线上的数据,就能解释清楚了,因为图中“预测值为0”的区域里,大多数数据点的y值都为0。
2. 线性回归
线性回归是人们通常知道的最早的机器学习模型之一。这是因为仅使用一个x变量时,它的算法(即幕后方程式)相对容易理解——画出一条最适合的直线,这是小学阶段教授的内容。然后,这条最佳拟合线可以预测出新的数据点(参见下图)。
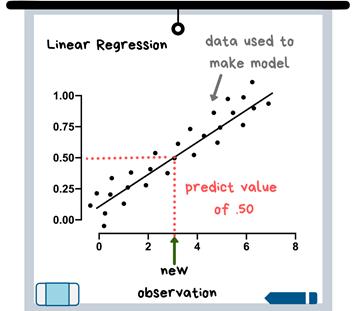
线性回归图
线性回归与逻辑回归类似,但是当目标变量连续时,才能使用线性回归,这意味着线性回归可以用任何数值。实际上,任何具有连续目标变量的模型都可以归类为“回归”。连续变量的一个例子是房屋的售价。
线性回归也很容易解释。模型方程式包含每个变量的系数,并且这些系数指示目标变量随着自变量(x变量)中的每个变化而变化的量。
以房价为例,这意味着你可以查看回归方程式,并可能这样说道:“哦,这告诉我,房屋面积(x变量)每增加1平方英尺,售价(目标变量)就增加25美元。”
3. K近邻算法(KNN)
该模型可用于分类或回归!“K近邻算法”这个名字并不会造成混淆。该模型首先要绘制出所有数据。其中,“ K”部分是指模型为了确定预测值应使用的最邻近数据点的数量(如下图)。你可以选择K,然后可以使用这些值来查看哪个值提供最佳预测。
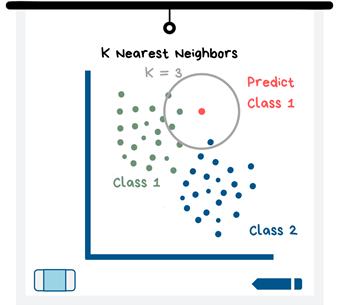
K近邻算法图
K = __圈中的所有数据点都可以对这个新数据点的目标变量值进行“投票”。得票最多的那个值是KNN为新数据点预测的值。
上图中,最近的点中有2个是1类,而1个是2类。因此,模型将为此数据点预测为1类。如果模型试图预测数值而非类别,则所有“投票”都是取平均值的数值,从而获得预测值。
4. 支持向量机
支持向量机在数据点之间建立边界来运行,其中一类中的大多数落在边界的一侧(在2D情况下又称为线),而另一类中的大多数落在另一侧。
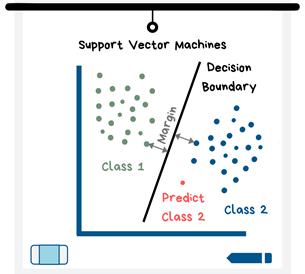
支持向量机图
其工作方式是机器力求找出具有最大边距的边界。边距是指每个类的最近点与边界之间的距离。然后绘制新的数据点,并根据它们落在边界的哪一侧将其分类。
笔者对此模型的解释是根据分类情况来的,不过你也可以用SVM进行回归。
5. 决策树和随机森林
图源:unsplash
无监督机器学习模型
接着到了“深水区”,我们来看看无监督学习。提醒一下,这意味着数据集未标记,因此不知道观察结果。
1. k均值聚类
在用K表示聚类时,必须首先假设数据集中有K个聚类。由于不知道数据中实际上有多少个组,因此必须尝试不同的K值,并使用可视化和度量标准来查看哪个K值行得通。K表示最适合圆形和相似大小的聚类。
k均值聚类算法首先选择最佳的K个数据点,以形成K个聚类中每个聚类的中心。然后,它对每个点重复以下两个步骤:
- 将数据点分配到最近的聚类中心
- 通过获取此聚类中所有数据点的平均值来创建一个新中心
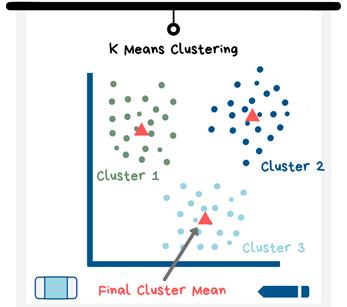
K均值聚类图
2. DBSCAN聚类
DBSCAN聚类模型与K均值聚类的不同之处在于,它不需要输入K的值,并且它还可以找到任何形状的聚类。你无需指定聚类数,而是输入聚类中所需的最小数据点数,并在数据点周围半径之内搜索聚类。
DBSCAN将为您找到聚类,然后,你可以更改用于创建模型的值,直到获得对数据集有意义的聚类为止。
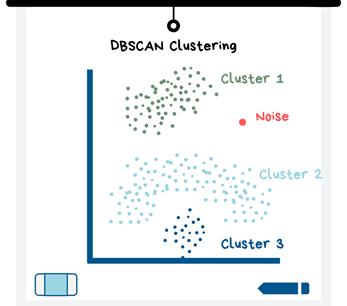
此外,DBSCAN模型会分类“噪声”点(即,远离所有其他观测值的点)。数据点非常靠近时,此模型比K均值的效果更好。
3. 神经网络
在笔者看来,神经网络是最酷、最神秘的模型。它们之所以被称为“神经网络”,是因为它们是根据我们大脑中神经元的工作方式进行建模的。这些模型在数据集中寻找模式;有时它们会发现人类可能永远无法识别的模式。
神经网络可以很好地处理图像和音频等复杂数据。从面部识别到文本分类,这些都是我们现在经常看到的软件背后的逻辑原理。
图源:unsplash
有时你可能会有困惑的地方,即使专家也无法完全理解为什么计算机得出这个结论。在某些情况下,我们在乎的只是它擅长预测!
不过有时我们会关心计算机如何得出其预测结果的,比如是否正在用模型来确定哪些求职者会获得第一轮面试的机会。
希望本文能让你加深对这些模型的理解,还能使你意识到它们是多么酷炫!