前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
如果你处于想学Python或者正在学习Python,Python的教程不少了吧,但是是最新的吗?说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的Python教程。
一、项目背景
- 案例类型:练习
- 案例工具:Python、Qgis
- 案例目的:通过实战进行学习,让大家综合运用基础知识,加深印象巩固记忆。
二 、提出问题
- 通过餐饮数据分析选出最具有竞争力的品类;
- 通过建立综合分数指标的计算公式来挑选出最适合地址。
三、理解数据
读取数据集后,通过info()和describe()方法来查看一下数据的基本情况。
- data.info()
- ——————————————————————————
- <class 'pandas.core.frame.DataFrame'>
- RangeIndex: 96398 entries, 0 to 96397
- Data columns (total 10 columns):
- 类别 96258 non-null object
- 行政区 96255 non-null object
- 点评数 96398 non-null int64
- 口味 96398 non-null float64
- 环境 96398 non-null float64
- 服务 96398 non-null float64
- 人均消费 96398 non-null int64
- 城市 96398 non-null object
- Lng 96398 non-null float64
- Lat 96398 non-null float64
- dtypes: float64(5), int64(2), object(3)
- memory usage: 7.4+ MB
- 数据共计96398个,10个变量/特征,数据类型数量为 float64(5), int64(2), object(3),粗略观察,数据明显有缺失值的情况,需要进行数据的清洗。
四、数据处理
使用data.isnull().values.sum()检查空值数量,检查出283个空值。
由于空值占数据总量比例为283/96398 = 0.0029,删除空值并不影响整体的数据情况,所以这里采用删除的办法来处理空值。
使用data.dropna()对空值进行删除,再使用data.isnull().values.sum()进行检查,结果为0。
数据清洗后的数据共计96255个。根据①通过餐饮数据分析选出最具有竞争力的品类的要求,选择相关的变量,选择['类别', '口味', '环境', '服务', '人均消费’]5个变量。
建立['类别', '口味', '环境', '服务', '人均消费’]的DataFrame,并且筛选出所有评分和消费大于0的情况。因为根据实际情况,评分和消费为0的数据对此没有参考作用。

引入’性价比’这一列,性价比的计算方式将所有的评分相加再除以人均消费金额,计算出 分/元 为单位的数值,表示单位价格获得的分数 来表示其性价比。

这样获得了df如下,筛选出了需要的数据54886个。
- df.info()
- ——————————————————————————
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 54886 entries, 0 to 96395
- Data columns (total 6 columns):
- 类别 54886 non-null object
- 口味 54886 non-null float64
- 环境 54886 non-null float64
- 服务 54886 non-null float64
- 人均消费 54886 non-null int64
- 性价比 54886 non-null float64
- dtypes: float64(4), int64(1), object(1)
- memory usage: 2.9+ MB
五、构建模型
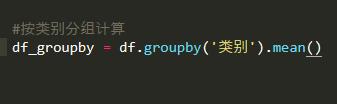
得到数据集df,选择'类别'进行groupby分组再进行mean值等到每个类别的值。
使用箱型图进行异常值的排查。
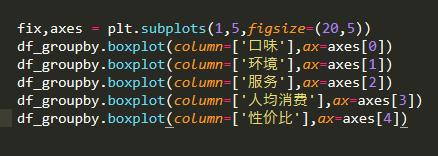
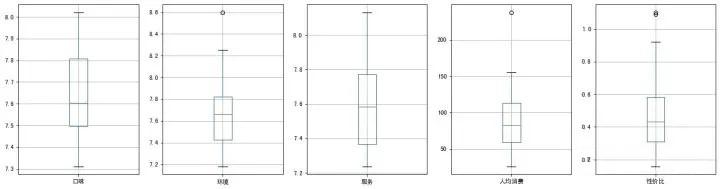
箱型图使用异常值删除的函数,对异常值进行删除。
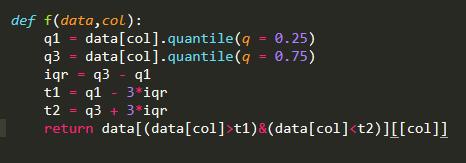
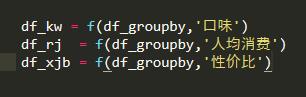
构建一个选择具有竞争力的品类的公式的因素,例如’口味','人均消费’,'性价比’,然后通过异常值删除的函数得出数据集。
将三组数据集放在同一张图上面。
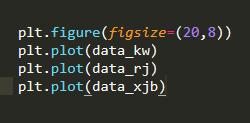
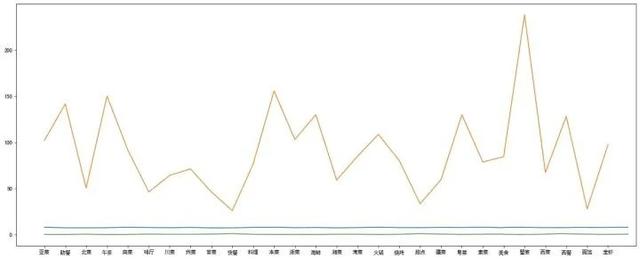
很明显是由于没有做 数据标准化处理。
数据标准化处理之后

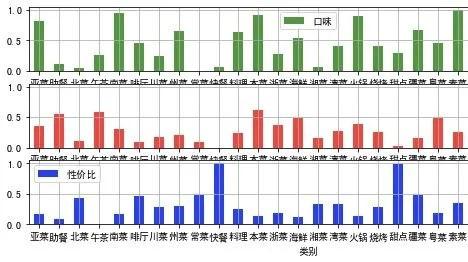
设计了一个计算公式,权重自己设计 分数的计算式 比如按照 口味:人均消费:性价比 = 2:5:3 的比例去计算。
先合并df_kw_max_min、df_rj_max_min、df_xjb_max_min,通过pd.merge合并。

计算最后的得分

得出【甜品】是最佳的品类。
使用Qgis制作出关于'人口密度'、'道路密度'、'餐饮密度'、'竞品密度’、'经度’、’维度'相关的数据集。
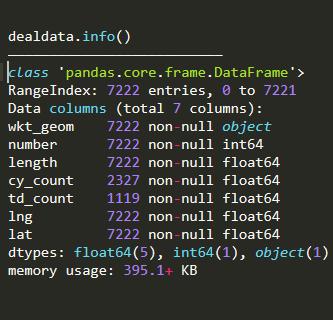
数据集有空值,使用dealdata.fillna(0,inplace=True)进行0的填充。
观察数据得知,'人口密度'、'道路密度'、'餐饮密度'、'竞品密度’不在同一纬度上,所以进行数据标准化处理。再计算['综合指标’]这一新列的数值。按照’人口密度’:'道路密度’:'餐饮密度’:'竞品密度’=4:3:2:1的比例。
六、数据可视化
利用matplotlib进行制图,使用散点图。

补充:使用bokeh绘制空间互动图形。
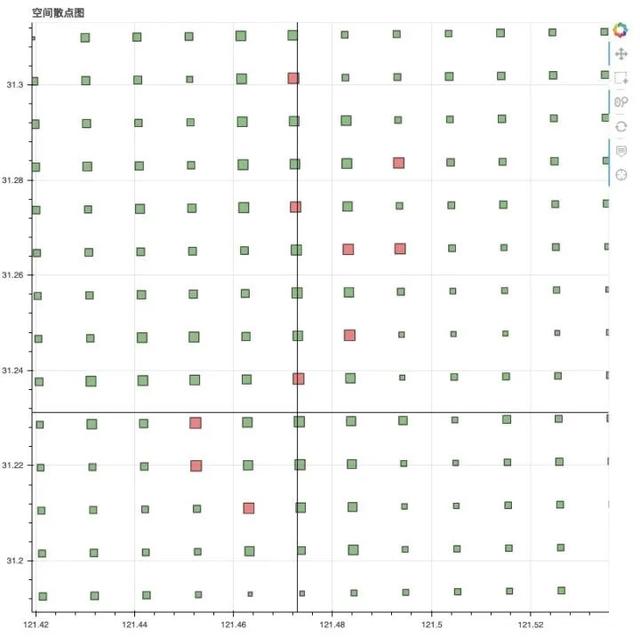
得出结论:
甜品店选址在(121°472′E,31°301′N)、(121°473′E,31°274′N)、(121°493′E,31°244′N)等地方开设最优