本文转载自公众号“读芯术”(ID:AI_Discovery)
问题来源于生活。上周在做业余项目时,我遇到了一个非常有趣的设计问题:“如果用户输入错误了怎么办?”如果输入错误,就会发生以下这种情况:
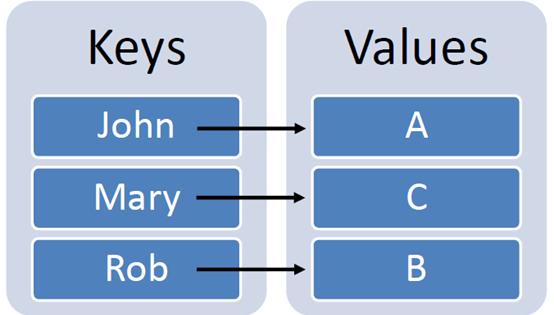
Python中的字典表示 键(keys)和值(values)。例如:
- student_grades = {'John': 'A','Mary': 'C', 'Rob': 'B'}# To check grade of John, we call
- print(student_grades['John'])
- # Output: A
当您试图访问不存在的密钥时会遇到什么情况?
- print(student_grades['Maple'])
- # Output:
- KeyError Traceback(most recent call last)
- <ipython-input-6-51fec14f477a> in <module>
- ----> print(student_grades['Maple'])
- KeyError: 'Maple'
您会收到密匙错误(KeyError)提示。
每当dict()请求对象为字典中不存在的键(key)时,就会发生KeyError。接收用户输入时,此错误十分常见。例如:
- student_name =input("Please enter student name: ")
- print(student_grades[student_name])
本文将为你提供几种处理Python字典 keyerror的方法。去努力构建一个python智能字典,它能帮你处理用户的输入错误问题。
设置默认值
一个非常简便的方法便是在请求的key不存在时返回默认值。可以使用get()方法完成此操作:
- default_grade = 'Not Available'
- print(student_grades.get('Maple',default_grade))# Output:
- # Not Available
解决大小写问题
假设您构建了Python字典,其中包含特定国家的人口数据。代码将要求用户输入一个国家名并输出显示其人口数。
- # population in millions. (Source: https://www.worldometers.info/world-population/population-by-country/)
- population_dict= {'China':1439, 'India':1380, 'USA':331, 'France':65,'Germany':83, 'Spain':46}
- # getting userinput
- Country_Name=input('Please enterCountry Name: ')
- # access populationusing country name from dict
- print(population_dict[Country_Name])
- # Output
- Please enter Country Name: France
- 65
然而,假设用户输入的是‘france’。目前,在我们的字典里,所有的键的首字母均是大写形式。那么输出内容会是什么?
- Please enter Country Name:france-----------------------------------------------------------------KeyError Traceback (most recentcall last)
- <ipython-input-6-51fec14f477a> in <module>
- 2 Country_Name = input('Pleaseenter Country Name: ')
- 3
- ----> 4 print(population_dict[Country_Name])
- KeyError: 'france'
由于‘france’不是字典中的键,因此会收到错误提示。
一个简单的解决方法:用小写字母存储所有国家/地区名称。另外,将用户输入的所有内容转换为小写形式。
- # keys (Country Names) are now alllowercase
- population_dict = {'china':1439, 'india':1380, 'usa':331, 'france':65,'germany':83, 'spain':46}
- Country_Name=input('Please enterCountry Name: ').lower() # lowercase input
- print(population_dict[Country_Name])
- Please enter Country Name:france
- 65
处理拼写错误
然而,假设用户输入的是 ‘Frrance’而不是 ‘France’。我们该如何解决此问题?
一种方法是使用条件语句。
我们会检查给定的用户输入是否可用作键(key)。如不可用,则输出显示一条消息。最好将其放入一个循环语句中,并在某特殊的标志输入上中断(如exit)。
- population_dict = {'china':1439, 'india':1380, 'usa':331, 'france':65,'germany':83, 'spain':46}
- while(True):
- Country_Name=input('Please enterCountry Name(type exit to close): ').lower()
- # break from code if user enters exit
- ifCountry_Name=='exit':
- break
- ifCountry_Nameinpopulation_dict.keys():
- print(population_dict[Country_Name])
- else:
- print("Pleasecheck for any typos. Data not Available for ",Country_Name)
循环将继续运行,直到用户进入exit。
优化方法
虽然上述方法“有效”,但不够“智能”。我们希望程序功能变强大,并能够检测到简单的拼写错误,例如frrance和chhina(类似于Google搜索)。
我找到了几个适合解决key error的库,其中我最喜欢的是标准的python库:difflib。
difflib可用于比较文件、字符串、列表等,并生成各种形式的不同信息。该模块提供了用于比较序列的各种类和函数。我们将使用difflib的两个功能:SequenceMatcher 和 get_close_matches。让我们简单地浏览下这两种功能。
1. # SequenceMatcher
SequenceMatcher是difflib中的类,用于比较两个序列。我们定义它的对象如下:
- difflib.SequenceMatcher(isjunk=None,a='', b='', autojunk=True)
- isjunk :在比较两个文本块时用于标明不需要的垃圾元素(空白,换行符等)。从而禁止通过有问题的文本。
- a and b: 比较字符串。
- autojunk :一种自动将某些序列项视为垃圾项的启发式方法。
让我们使用SequenceMatcher比较chinna和china这两个字符串:
- from difflib importSequenceMatcher# import
- # creating aSequenceMatcher object comparing two strings
- check =SequenceMatcher(None, 'chinna', 'china')
- # printing asimilarity ratio on a scale of 0(lowest) to 1(highest)
- print(check.ratio())
- # Output
- #0.9090909090909091
在以上代码中,使用了ratio()方法。ratio返回序列相似度的度量,作为范围[0,1]中的浮点值。
2. # get_close_matches
现提供一种基于相似性比较两个字符串的方法。
如果我们希望找到与特定字符串相似的所有字符串(存储于数据库),会发生什么情况?
get_close_matches() 返回一个列表,其中包含可能性列表中的最佳匹配项。
- difflib.get_close_matches(word,possibilities, n=3, cutoff=0.6)
- word:需要匹配的字符串。
- possibilities: 匹配单词的字符串列表。
- Optional n: 要返回的最大匹配数。默认情况下是3;且必须大于0。
- Optional cutoff:相似度必须高于此值。默认为0.6。
潜在的最佳n个匹配项将返回到一个列表中,并按相似度得分排序,最相似者优先。

来看以下示例:
- from difflib importget_close_matches
- print(get_close_matches("chinna", ['china','france','india','usa']))
- # Output
- # ['china']
汇总
既然可以使用difflib了,那么让我们把所有内容进行组合,构建一个防误的python字典。
当用户提供的国家名不在population_dic.keys()中时,需要格外注意。我们应尝试找到一个名称与用户输入相似的国家,然后输出其人口数。
- # pass country_name in word anddict keys in possibilities
- maybe_country = get_close_matches(Country_Name, population_dict.keys())# Thenwe pick the first(most similar) string from the returned list
- print(population_dict[maybe_country[0]])
最终代码还需考虑其他一些情况。例如,如果没有相似的字符串,或者未向用户确认这是否是所需字符串。如下:
- from difflib importget_close_matches
- population_dict = {'china':1439, 'india':1380, 'usa':331, 'france':65,'germany':83, 'spain':46}
- while(True):
- Country_Name=input('Please enterCountry Name(type exit to close): ').lower()
- # break from code if user enters exit
- ifCountry_Name=='exit':
- break
- ifCountry_Nameinpopulation_dict.keys():
- print(population_dict[Country_Name])
- else:
- # look for similarstrings
- maybe_country =get_close_matches(Country_Name,population_dict.keys())
- if maybe_country == []: # no similar string
- print("Pleasecheck for any typos. Data not Available for ",Country_Name)
- else:
- # user confirmation
- ans =input("Do youmean %s? Type y or n."% maybe_country[0])
- if ans =='y':
- # if y, returnpopulation
- print(population_dict[maybe_country[0]])
- else:
- # if n, start again
- print("Bad input.Try again.")
输出:
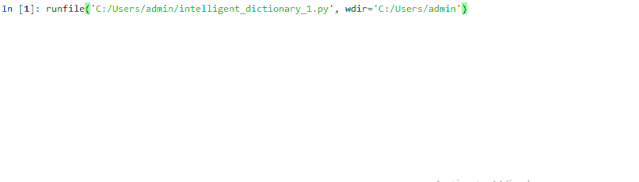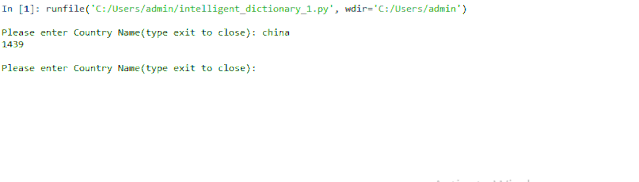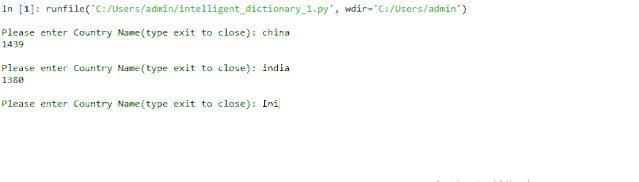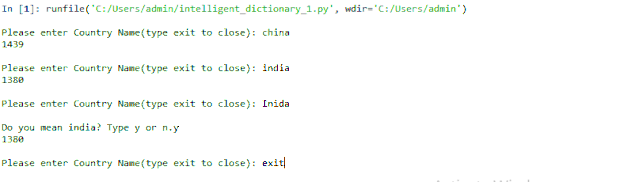
Inida 其实是India.
这样一来,用户的大小写混淆或是输入错误的处理就不在话下了。你还可以进一步研究其他各种应用程序,比如使用NLPs 更好地理解用户输入,并在搜索引擎中显示相似结果。Python智能字典的构建方法,你学会了吗?