01 机器阅读理解任务
学者C. Snow于2002年发表的一篇论文中将阅读理解定义为“通过交互从书面文字中提取与构造文章语义的过程”。而机器阅读理解的目标是利用人工智能技术,使计算机具有和人类一样理解文章的能力。
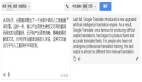
图1所示为机器阅读理解的一个样例。示例中,机器阅读理解模型需要用文章中的一段原文来回答问题。

▲图1 机器阅读理解任务样例
1. 机器阅读理解模型
机器阅读理解模型的输入为文章和问题文本,输出为最终的回答。为了完成任务,模型需要深度分析文章语义以及文章和问题之间的联系,然后根据文章中的内容作出准确回答。
当前,绝大多数机器阅读理解算法均采用深度学习模型,利用深度神经网络进行建模与优化。深度学习的特点是,模型能根据训练集上预测的准确度直接优化参数,不断提高模型性能,从而达到很好的效果。
由于深度学习需要在数值空间处理信息,因此阅读理解模型首先要对文章和问题进行数字化表示,形成文本编码。常见的方法是词向量(word vector):将文本分成若干单词,然后用一串数字(即一个向量)表示一个单词。
- 文本的数字化表示:分词与词向量
- 原文:今天天气真好
- 分词:今天|天气|真|好
- 词向量:
今天:[3.2, -1.5, 6.0]
天气:[-0.2, -5.0, 1.7]
真:[1.4, 2.8, 0.9]
好:[-2.6, 3.8, -5.2]
常用的中英文分词算法我们已经在《为什么中文分词比英文分词更难?有哪些常用算法?(附代码)》介绍。
接下来,机器阅读理解模型会对这些数字化编码进行各种操作,获得上下文信息以及文章和问题之间的语义关联,从而获取有关答案的线索。一般而言,基于深度学习的机器阅读理解模型的架构分为3个部分:
- 编码层对文章和问题进行单词编码,并完成上下文语义分析;
- 交互层处理文章和问题之间的关联信息,找出文章中与问题相关的线索;
- 输出层将之前处理的信息按照任务要求生成答案。
不同的机器阅读理解模型通常是上述3个部分中使用不同的模块与连接方式。但无论哪种阅读理解模型,其训练过程都依赖于人工标注的数据,如大量文章–问题–答案的三元组。
但是,生成这些标注数据需要花费大量的时间和人力。因此,近年来自然语言处理界提出了预训练+微调模式:在大量无标注文本数据上训练大规模模型,然后在少量具体任务的标注数据(如阅读理解)上进行微调。这种模式取得了很好的效果,也有效缓解了标注数据缺乏的问题。
2. 机器阅读理解的应用
随着各行各业文本数据的大量产生,传统的人工处理方式因为处理速度慢、开销巨大等因素成为产业发展的瓶颈。因此,能自动处理分析文本数据并从中抽取语义知识的机器阅读理解技术逐渐受到人们的青睐。
例如,传统的搜索引擎只能返回与用户查询相关的文档,而阅读理解模型可以在文档中精确定位问题的答案,从而提高用户体验。
- 在客户服务中,利用机器阅读理解在产品文档中找到与用户描述问题相关的部分并给出详细解决方案,可以大大提高客服效率。
- 在智能医疗领域,阅读理解模型能根据患者症状描述自动查阅大量病历和医学论文,找到可能的病因并输出诊疗方案。
- 在语言教育方面,可以利用阅读理解模型批改学生的作文并给出改进意见,随时随地帮助学生提高作文水平。
可以看出,凡是需要自动处理和分析大量文本内容的场景下,机器阅读理解都可以帮助节省大量人力和时间。
在很多领域中,如果阅读理解模型的质量没有达到完全替代人类的水平,可采用与人工结合的方式,利用计算机处理简单高频的问题,从而达到降低成本的作用。因此,机器阅读理解成为当前人工智能研究中最前沿、最热门的方向之一。

02 自然语言处理
机器阅读理解属于语言处理的范畴,而自然语言处理是人工智能领域的重要研究方向。它主要分析人类语言的规律和结构,设计计算机模型理解语言并与人类进行交流。自然语言处理的历史可以追溯到人工智能的诞生。
在数十年的发展中,自然语言的处理、理解和生成等领域的研究已经取得了长足的进步。这些都为机器阅读理解研究奠定了坚实的基础。本节主要介绍自然语言处理的研究现状及其对机器阅读理解的影响。
1. 研究现状
经过70余年的发展,自然语言处理相关研究已经细化分类成许多子任务。以下是与机器阅读理解相关的重要研究方向。
- 信息检索(information retrieval)。研究如何在海量文档或网页中寻找与用户查询相关的结果。信息检索方面的研究已经相当成熟,并广泛应用在网页搜索等产品中,为信息的传播和获取提供了极大的便利。当一个阅读理解任务涉及大规模文本库时,信息检索通常作为系统中抽取相关信息的第一个模块。
2. 问答系统(question and answering system)是指可以自动回答用户提出问题的系统。问答系统与信息检索的区别在于,问答系统需要理解复杂问题的语义,并支持多轮有上下文的对话。例如,对话式阅读理解需要模型同时分析文章语义和之前对话轮次的信息,再对当前问题作出回答。
3. 文本分类(text classification)是指对文章、段落、语句进行分类,如将大量网页按照内容和主题进行划分。一些机器阅读理解模型对问题进行分类,如关于时间的问题、关于地点的问题等,以提高答案的准确性。这种问题分类就属于文本分类的范畴。
4. 机器翻译(machine translation)研究如何让计算机自动翻译文本,可以应用在跨语言的阅读理解任务中。例如,当文本来自小语种语言时,我们可以利用机器自动翻译常用语言中的阅读理解数据,从而解决训练数据缺乏的问题。
5. 文本摘要(text summarization)研究如何用简洁的语言概括文章的主旨和重要信息。由于文本摘要需要对文章语义进行分析并生成结果,其中的很多技术被应用到机器阅读理解中,例如序列到序列模型(sequence-to-sequence),拷贝–生成网络(pointer-generator network)等。
2. 仍需解决的问题
随着相关模型的不断发展,自然语言处理在许多任务中取得了令人瞩目的成绩。但是,仍有许多没有很好解决的问题,其中也包括对基本语言结构和语义的理解。这些也是机器阅读理解研究中亟待解决的问题。
1)语言的歧义性
由于语言的一大特性是用较为精练的语句代表复杂的语义,因此一段文本时常会存在多义和歧义等情况,也就是有多种合理的解释方式。来看下面几个例子。
- 示例1:工厂领导对小张的批评意见进行过多次讨论。
这里,既可以理解为领导讨论了小张对工厂提出的批评意见,也可以理解为领导讨论了对小张的批评意见。原因是“对”的对象可以是“小张的批评意见”,也可以是“小张”。
- 示例2:化学所取得的成绩是有目共睹的。
这里,既可以理解为成绩是“化学”取得的,也可以理解为成绩是“化学所”取得的。原因是“所”既可以作为介词,也可以作为“化学所”的一部分。
- 示例3:我要炒青菜。
这里,可以认为“炒青菜”是一道菜,而“我”在点菜,也可以认为“我”要去炒青菜。原因是“炒”可以作为整句话的动词,也可以和“青菜”组成菜名。
这样的歧义性示例还有许多。即使人类在面对这些语句时,也很难判断说话者的真实意图。但是,如果有上下文信息,歧义就会消除。
例如,“我要炒青菜”发生在餐馆点菜语境中,就说明“炒青菜”是一道菜;“化学所取得的成绩是有目共睹的”出现在学校领导对化学所的考评中,就表示成绩是属于“化学所”的。
到目前为止,自然语言处理的模型仍不能很好地理解上下文的语义。研究人员通过分析自然语言处理模型在机器阅读理解模型等任务上的结果,发现现有模型很大程度上是基于单词或关键词进行匹配,这也导致这些模型对于歧义性文本的处理能力很低。
2)推理能力
在人类语言交流中,许多时候可以从语言推理得出结论,而不需要详细说明。例如,下面这个顾客通过客服订票的对话例子:
客服:您好,请问我可以怎样帮助您?
顾客:我想订一张5月初从北京去上海的机票。
客服:好的,那么您想哪天出发?
顾客:嗯,我是去上海开会,这个会从4号开到7号。
客服:好的,下面是5月3日从北京出发到上海的直达航班信息……
上面的对话中,顾客并没有正面回答客服关于哪天出发的问题,而是给出了开会的时间段。
但是,从订机票去开会这个事件可以推理出,顾客一定是想在会议开始前到达目的地,因此客服给出了5月3日出发的航班信息。当然,如果顾客想要订上海回北京的机票,客服就应该给出5月7日晚或5月8日出发的航班信息。
因此,智能客服的模型需要根据之前的谈话内容推断出所需要的信息——出发日期。这种推断需要模型具有一定的常识,即航班必须在开会前到达目的地。
近年来已经出现常识和推理在自然语言处理应用上的研究,但如何让模型包含海量的常识并进行有效的推理仍是一个需要解决的问题。
关于作者:朱晨光,微软公司自然语言处理高级研究员、斯坦福大学计算机系博士。负责自然语言处理研究与开发、对话机器人的语义理解、机器阅读理解研究等,精通人工智能、深度学习与自然语言处理,尤其擅长机器阅读理解、文本总结、对话处理等方向。
本文摘编自《机器阅读理解:算法与实践》,经出版方授权发布。