













本文转自雷锋网,如需转载请至雷锋网官网申请授权。
ICLR 2020 正在进行,但总结笔记却相继出炉。我们曾对 ICLR 2020 上的图机器学习趋势进行介绍,本文考虑的主题为知识图谱。
作者做波恩大学2018级博士生 Michael Galkin,研究方向为知识图和对话人工智能。在AAAI 2020 举办之际,他也曾对发表在AAAI 2020上知识图谱相关的文章做了全方位的分析,具体可见「知识图谱@AAAI2020」。
本文从五个角度,分别介绍了 ICLR 2020上知识图谱相关的 14 篇论文。五个角度分别为:
1)在复杂QA中利用知识图谱进行神经推理(Neural Reasoning for Complex QA with KGs)
2)知识图谱增强的语言模型(KG-augmented Language Models)
3)知识图谱嵌入:循序推理和归纳推理(KG Embeddings: Temporal and Inductive Inference)
4)用GNN做实体匹配(Entity Matching with GNNs)
5)角色扮演游戏中的知识图谱(Bonus: KGs in Text RPGs!)
话不多说,我们来看具体内容。
注:文中涉及论文,可关注「AI科技评论」微信公众号,并后台回复「知识图谱@ICLR2020」打包下载。
一、在复杂QA中利用知识图谱进行神经推理
今年ICLR2020中,在复杂QA和推理任务中看到越来越多的研究和数据集,very good。去年我们只看到一系列关于multi-hop阅读理解数据集的工作,而今年则有大量论文致力于研究语义合成性(compositionality)和逻辑复杂性(logical complexity)——在这些方面,知识图谱能够帮上大忙。
1、Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
文章链接:https://openreview.net/pdf?id=SygcCnNKwr
Keysers等人研究了如何测量QA模型的成分泛化,即训练和测试 split 对同一组实体(广泛地来讲,逻辑原子)进行操作,但是这些原子的成分不同。作者设计了一个新的大型KGQA数据集 CFQ(组合式 Freebase 问题),其中包含约240k 个问题和35K SPARQL查询模式。
Intuition behind the construction process of CFQ. Source: Google blog
这里比较有意思的观点包括:1)用EL Description Logic 来注释问题(在2005年前后,DL的意思是Description Logic,而不是Deep Learning );2)由于数据集指向语义解析,因此所有问题都链接到了Freebase ID(URI),因此您无需插入自己喜欢的实体链接系统(例如ElasticSearch)。于是模型就可以更专注于推断关系及其组成;3)问题可以具有多个级别的复杂性(主要对应于基本图模式的大小和SPARQL查询的过滤器)。
作者将LSTM和Transformers基线应用到该任务,发现它们都没有遵循通用标准(并相应地建立训练/验证/测试拆分):准确性低于20%!对于KGQA爱好者来说,这是一个巨大的挑战,因此我们需要新的想法。
2、Scalable Neural Methods for Reasoning With a Symbolic Knowledge Base
文章链接:https://openreview.net/pdf?id=BJlguT4YPr
Cohen等人延续了神经查询语言(Neural Query Language,NQL)和可微分知识库议程的研究,并提出了一种在大规模知识库中进行神经推理的方法。
作者引入了Reified KB。其中事实以稀疏矩阵(例如COO格式)表示,方式则是对事实进行编码需要六个整数和三个浮点数(比典型的200浮点KG嵌入要少得多)。然后,作者在适用于多跳推理的邻域上定义矩阵运算。
这种有效的表示方式允许将巨大的KG直接存储在GPU内存中,例如,包含1300万实体和4300万事实(facts)的WebQuestionsSP 的 Freebase转储,可以放到三个12-Gb 的 GPU中。而且,在进行QA时可以对整个图谱进行推理,而不是生成候选对象(通常这是外部不可微操作)。
作者在文章中对ReifiedKB进行了一些KGQA任务以及链接预测任务的评估。与这些任务当前的SOTA方法相比,它的执行效果非常好。
事实上,这项工作作为一个案例,也说明SOTA不应该成为一篇论文是否被接收的衡量标准,否则我们就错失了这些新的概念和方法。
3、Differentiable Reasoning over a Virtual Knowledge Base
文章链接:https://openreview.net/pdf?id=SJxstlHFPH
Dhingra等人的工作在概念矿建上与上面Cohen等人的工作类似。他们提出了DrKIT,这是一种能用于在索引文本知识库上进行差分推理的方法。
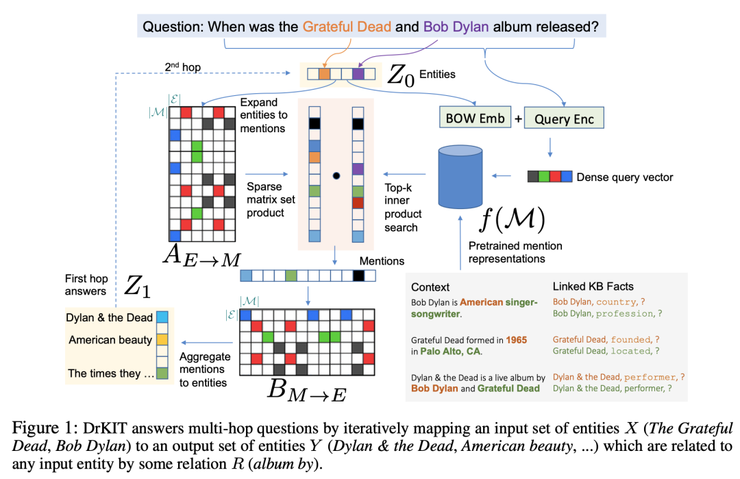
DrKIT intuition. Source: Dhingra et al
这个框架看起来可能会有些复杂,我们接下来将它分成几个步骤来说明。
1)首先,给定一个question(可能需要多跳推理),实体链接器会生成一组 entities(下图中的Z0)。
2)使用预先计算的索引(例如TF-IDF)将一组实体扩展为一组mentions(表示为稀疏矩阵A)。
3)在右侧,question 会通过一个类似BERT的编码器,从而形成一个紧密向量。
4)所有mentions 也通过一个类似BERT的编码器进行编码。
5)使用MIPS(Maximum Inner Product Search)算法计算scoring function(用来衡量mentions, entities 和 question相关分数),从而得到Top-k向量。
6)矩阵A乘以Top-K 选项;
7)结果乘以另一个稀疏的共指矩阵B(映射到一个实体)。
这构成了单跳推理步骤,并且等效于在虚拟KB中沿着其关系跟踪提取的实体。输出可以在下一次迭代中进一步使用,因此对N跳任务会重复N次!
此外,作者介绍了一个基于Wikidata的新的插槽填充数据集(采用SLING解析器构造数据集),并在MetaQA、HotpotQA上评估了 DrKIT,总体来说结果非常棒。
4、Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
文章链接:https://openreview.net/pdf?id=SJgVHkrYDH
Asai等人的工作专注于HotpotQA,他们提出了Recurrent Retriever的结构,这是一种开放域QA的体系结构,能够以可区分的方式学习检索推理路径(段落链)。
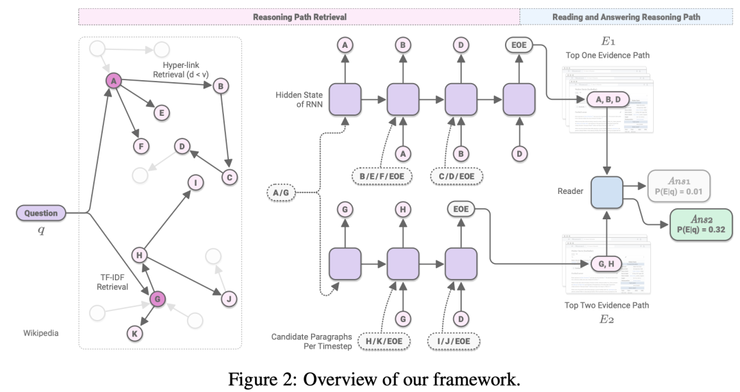
Recurrent Retrieval architecture. Source: Asai et al
传统上,RC模型会采用一些现成的检索模型来获取可能的候选者,然后才执行神经读取pipeline。这篇工作则希望让检索具有差异性,从而将整个系统编程端到端的可训练模型。
1)整个Wikipedia(英语)都以图谱的形式组织,其边表示段落和目标页面之间的超链接。例如对于Natural Questions,大小约为3300万个节点,边有2.05亿个。
2)检索部分采用的RNN,初始化为一个隐状态h0,这是对问题 q 和候选段落p编码后获得的。这些候选段落首先通过TF-IDF生成,然后通过图谱中的链接生成。(上图中最左侧)
3)编码(q,p)对的BERT [CLS]令牌会被送到RNN中,RNN会预测下一个相关的段落。
4)一旦RNN产生一个特殊的[EOE]令牌,读取器模块就会获取路径,对其重新排序并应用典型的提取例程。
作者采用波束搜索和负采样来增强对嘈杂路径的鲁棒性,并很好地突出了路径中的相关段落。重复检索(Recurrent Retrieval )在HotpotQA的 full Wiki测试设置上的F1分数获得了惊人的73分。这篇工作的代码已发布。
5、Neural Symbolic Reader: Scalable Integration of Distributed and Symbolic Representations for Reading Comprehension
文章链接:https://openreview.net/pdf?id=ryxjnREFwH
6、Neural Module Networks for Reasoning over Text
文章链接:https://openreview.net/pdf?id=SygWvAVFPr
我们接下来谈两篇复杂数字推理的工作。
在数字推理中,你需要对给定的段落执行数学运算(例如计数、排序、算术运算等)才能回答问题。例如:
文本:“……美洲虎队的射手乔什·斯科比成功地射入了48码的射门得分……而内特·凯丁的射手得到了23码的射门得分……”问题:“谁踢出最远的射门得分?”
目前为止,关于这个任务只有两个数据集,DROP(SQuAD样式,段落中至少包含20个数字)和MathQA(问题较短,需要较长的计算链、原理和答案选项)。因此,这个任务的知识图谱并不很多。尽管如此,这仍然是一个有趣的语义解析任务。
在ICLR 2020 上,有两篇这方面的工作。一篇是是Chen 等人的工作,提出了一个神经符号读取器NeRd(Neural Symbolic Reader);另一篇是Gupta等人在神经模块网络NMN(Neural Module Networks)上的工作。
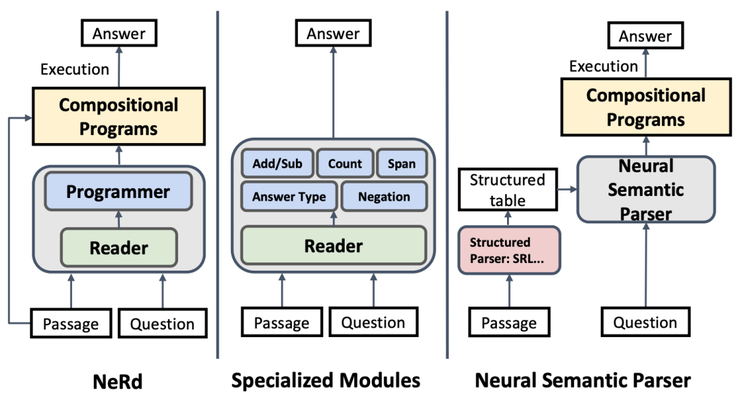
NeRd vs other approaches. Source: Chen et al
两项工作都是由读取器和基于RNN的解码器组成,从预定义的域特定语言(DSL,Domain Specific Language)生成操作(操作符)。从性能上相比,NeRd更胜一筹,原因在于其算符的表达能力更强,解码器在构建组合程序上也更简单。另一方面,NMN使用张量交互对每个运算符进行建模,于是你需要手工制定更多的自定义模块来完成具体任务。
此外,NeRd的作者做了许多努力,为弱监督训练建立了可能的程序集,并采用了带有阈值的Hard EM 算法来过滤掉虚假程序(能够基于错误的程序给出正确答案)。NeRd 在DROP测试集上获得了81.7 的F1 分数,以及78.3 的EM分数。
对NMN进行评估,其中月有25%的DROP数据可通过其模块来回答,在DROP dev测试中获得了77.4 的F1 分数 和74 的EM 分数。
二、知识图谱增强的语言模型
将知识融入语言模型,目前已是大势所趋。
7、Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
文章链接:https://openreview.net/pdf?id=BJlzm64tDH
今年的ICLR上,Xiong等人在预测[MASK] token之外,提出了一个新的训练目标:需要一个模型来预测entity是否已经被置换。
作者对预训练Wikipedia语料库进行处理,基于超链接,将Wiki的entity表面形式(标签)替换为相同类型的另一个entity。基于P31的「instance of」关系,从wikidata中获取类型信息。如下图所示,在有关Spider-Man的段落中,实体 Marvel Comics 可以替换为 DC Comics。
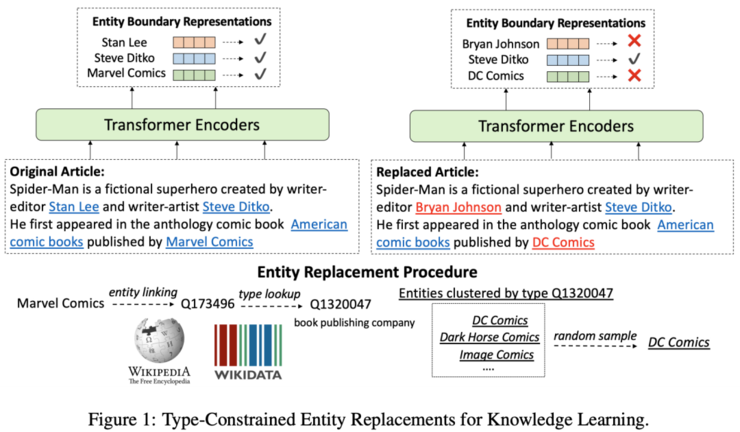
Pre-training objective of WKLM. Source: Xiong et al
模型的任务是预测实体是否被替换掉了。
WKLM(Weakly Supervised Knowledge-Pretrained Languge Model)使用MLM目标(掩蔽率为5%,而不是BERT的15%)进行预训练,每个数据点使用10个负样本,类似于TransE的训练过程。
作者评估了10个Wikidata关系中的WKLM事实完成性能(fact completion performance),发现其达到了约29 Hits@10的速率,而BERT-large和GPT-2约为16。
随后,作者在性能优于基准的WebQuestions,TriviaQA,Quasar-T和Search-QA数据集上对WKLM进行了微调和评估。
总结一句话,这是一个新颖的、简单的,但却有实质性意义的想法,有大量的实验,也有充分的消融分析。
三、知识图谱嵌入:循序推理和归纳推理
像Wikidata这样的大型知识图谱永远不会是静态的,社区每天都会更新数千个事实(facts),或者是有些事实已经过时,或者是新的事实需要创建新实体。
循序推理。说到时间,如果要列出美国总统,显然triple-base的知识图谱,会把亚当斯和特朗普都列出来。如果不考虑时间的话,是否意味着美国同时有45位总统呢?为了避免这种歧义,你必须绕过纯RDF的限制,要么采用具体化的方式(针对每个具体的歧义进行消除),要么采用更具表现力的模型。例如Wikidata状态模型(Wikidata Statement Model)允许在每个statement中添加限定符,以总统为例,可以将在限定符处放上总统任期的开始时间和结束时间,通过这种方式来表示给定断言为真的时间段。循序知识图谱嵌入算法(Temporal KG Embeddings algorithms)的目标就是够条件这样一个时间感知(time-aware)的知识图谱表示。在知识图谱嵌入中时间维度事实上,只是嵌入字(例如身高、长度、年龄以及其他具有数字或字符串值的关系)的一部分。
归纳推理。大多数现有的知识图谱嵌入算法都在已知所有实体的静态图上运行——所谓的转导设置。当你添加新的节点和边时,就需要从头开始重新计算整个嵌入;但对于具有数百万个节点的大型图来说,这显然不是一个明智的方法。在归纳设置(inductive setup)中,先前看不见的节点可以根据他们之间的关系和邻域进行嵌入。针对这个主题的研究现在不断增加,ICLR 2020 上也有几篇有趣的文章。
8、Tensor Decompositions for Temporal Knowledge Base Completion
文章链接:https://openreview.net/pdf?id=rke2P1BFwS
Lacroix等人使用新的正则化组件扩展了ComplEx嵌入模型,这些正则化组件考虑了嵌入模型中的时间维度。
这项工作非常深刻,具体表现在以下几个方面:1)想法是将连续的时间戳(如年,日及其数值属性)注入到正则化器中;2)作者提出TComplEx,其中所有谓词都具有time属性;提出TNTCompEx,其中对诸如「born in」这样“永久”的属性进行区别对待。实验表明,TNTCompEx的性能更好;3)作者介绍了一个新的大型数据集,该数据集基于Wikidata Statements,但带有开始时间和结束时间限定符,该数据集包含约40万个实体和700万个事实。
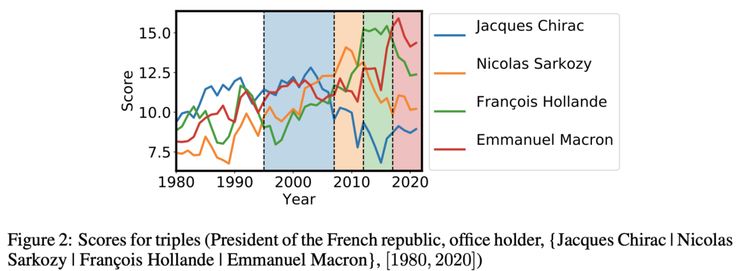
Time-aware ComplEx (TNTComplEx) scores. Source: Lacroix et al
上图中,你可以看到这个模型如何对描述法国总统的事实的可能性进行评分:自2017年以来,伊曼纽尔·马克龙的得分更高,而弗朗索瓦·奥朗德在2012–2017年的得分更高。
9、Inductive representation learning on temporal graphs
文章链接:https://openreview.net/pdf?id=rJeW1yHYwH
再进一步,Xu等人提出了临时图注意力机制TGAT(temporal graph attention),用于建模随时间变化的图,包括可以将新的先前未见的节点与新边添加在一起时的归纳设置。其思想是基于经典和声分析中的Bochner定理,时间维度可以用傅里叶变换的时间核来近似。时间嵌入与标准嵌入(例如节点嵌入)串联在一起,并且全部输入到自注意力模块中。
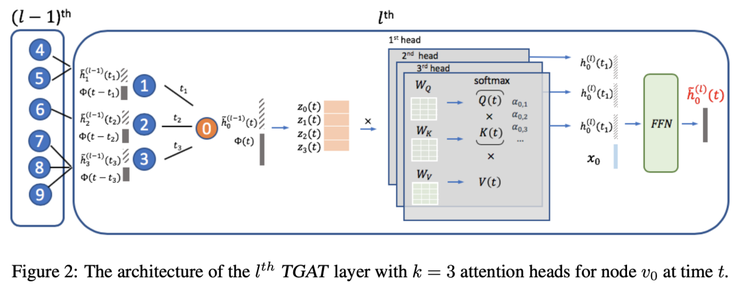
Source: Xu et al
作者将TGAT在具有单关系图(不是KG的多关系图)的标准转导与归纳GNN任务上进行了评估,TGAT显示出了很好的性能提升。个人认为,这个理论应该可以进一步扩展到支持多关系KG。
再回到传统的感应式KG嵌入设置(transductive KG embedding setup):
— GNN?是的!— Multi-多关系?是的!— 建立关系的嵌入?是的!— 适合知识图谱吗?是的!— 适用于节点/图形分类任务吗?是的。
10、Composition-based Multi-Relational Graph Convolutional Networks
文章链接:https://openreview.net/pdf?id=BylA_C4tPr
Vashishth 等人提出的 CompGCN体系结构为你带来了所有这些优点。标准的图卷积网络以及消息传递框架在考虑图时,通常认为边是没有类型的,并且通常不会构建边的嵌入。
知识图谱是多关系图,边的表示对链接预测任务至关重要。对于(Berlin,?,Germany) 的query,你显然是要预测capitalOf,而不是childOf。
在CompGCN中,首先会为输入的 KG 填充反关系(最近已普遍使用)和自循环关系(用来实现GCN的稳定性)。CompGCN采用编码-解码方法,其中图编码器构建节点和边的表示形式,然后解码器生成某些下游任务(如链接预测或节点分类)的分数。
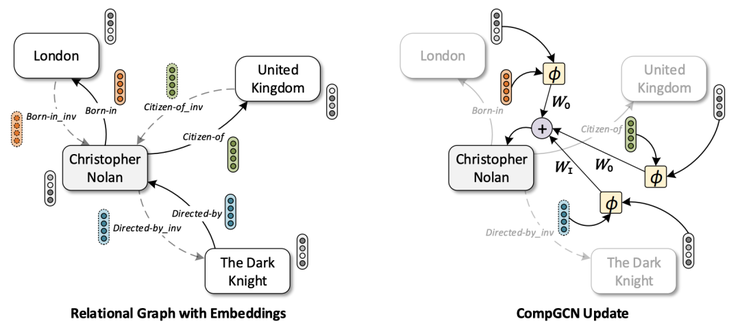
CompGCN intuition. Source: Vashishth et al
节点表示是通过聚集来自相邻节点的消息而获得的,这些消息对传入和传出的边(图中的Wi,Wo以及那些自循环)进行计数,其中交互函数对 (subject, predicate)进行建模。
作者尝试了加法(TransE-style),乘法(DistMult-style)和圆相关(HolE-style)的交互。在汇总节点消息之后,边的表示将通过线性层进行更新。你几乎可以选择任何你喜欢的解码器,作者选择的是 TransE,DistMult 和 ConvE 解码器。CompGCN在链接预测和节点分类任务方面都比R-GCN要好,并且在性能上与其他SOTA模型相当。性能最好的CompGCN是使用带有ConvE解码器的基于循环相关的编码器。
11、Probability Calibration for Knowledge Graph Embedding Models
文章链接:https://openreview.net/pdf?id=S1g8K1BFwS
Last, but not least,Tabacoff和Costabello考虑了KGE模型的概率校准。简单来说,如果你的模型以90%的置信度预测某个事实是正确的,则意味着该模型必须在90%的时间里都是正确的。但是,通常情况并非如此,例如,在下图中,表明TransE倾向于返回较小的概率(有点“悲观”)。
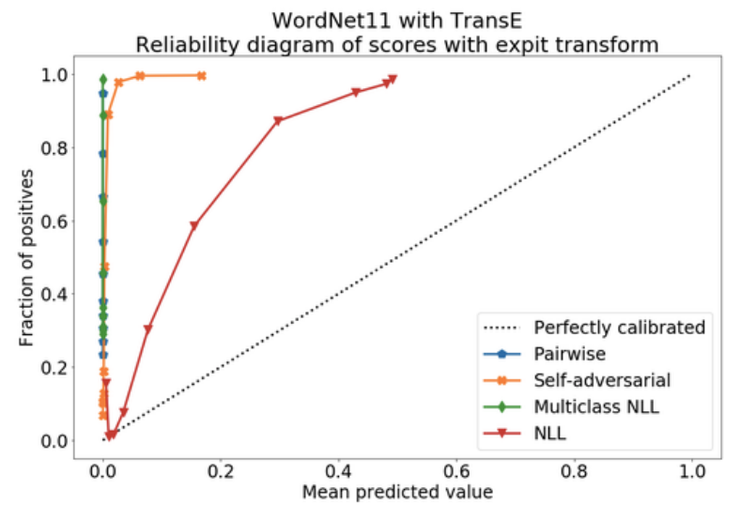
Source: Tabacoff and Costabello
作者采用Brier评分来测量校准,采用Platt缩放和等渗回归来优化校准评分,并提出了在没有给出“hard negatives”的典型链接预测方案中对负样本进行采样的策略。于是,你可以校准KGE模型,并确保它会返回可靠的结果。这是一个非常好的分析,结果表明在一些工业任务上,你可以用KGE模型来提升你对自己算法/产品的信心。
四、用GNN做实体匹配
不同的知识图谱都有他们自己的实体建模的模式,换句话说,不同的属性集合可能只有部分重叠,甚至URLs完全不重叠。例如在Wikidata中Berlin的URL是https://www.wikidata.org/entity/Q64,而DBpedia中Berlin的URL是http://dbpedia.org/resource/Berlin。
如果你有一个由这些异质URL组成的知识图谱,尽管它们两个都是在描述同一个真实的Berlin,但知识图谱中却会将它们视为各自独自的实体;当然你也可以编写/查找自定义映射,以显式的方式将这些URL进行匹配成对,例如开放域知识图谱中经常使用的owl:sameAs谓词。维护大规模知识图谱的映射问题是一个相当繁琐的任务。以前,基于本体的对齐工具主要依赖于这种映射来定义实体之间的相似性。但现在,我们有GNNs来自动学习这样的映射,因此只需要一个小的训练集即可。
我们在「知识图谱@AAAI2020」的文章中简要讨论了实体匹配的问题。而在ICLR 2020 中这方面的研究有了新的进展。
12、Deep Graph Matching Consensus
文章链接:https://openreview.net/pdf?id=HyeJf1HKvS
Fey 等人推出了DGMC框架(深度图匹配共识,Deep Graph Matching Consensus),这个框架包括两大阶段:
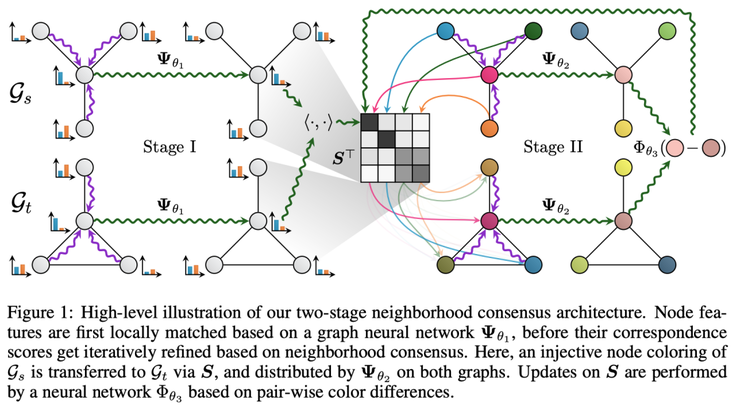
Deep Graph Matching Consensus intuition. Source: Fey et al
1)两个图,源图(Gs)和目标图(Gt),通过相同的GNN(具有相同的参数,表示为ψ_θ1)获得初始节点嵌入。然后通过乘以节点嵌入,并应用Sinkhorn归一化来获得软对应矩阵S(soft correspondences matrix S)。这里可以使用任何最适合任务的GNN编码器。
2)随后将消息传递(也可以看做是图形着色)应用到邻域(标注为ψ_θ2的网络),最后计算出源节点和目标节点之间的距离(ψ_θ3),这个距离表示邻域共识。
作者对DGMC进行了广泛的任务评估——匹配随机图、匹配目标检测任务的图,以及匹配英、汉、日、法版的DBpedia。有意思的是,DGMC在删除关系类型时,却能产生很好的结果,这说明源KG和目标KG之间基本上是单一关系。
于是引入这样一条疑惑:如果在Hits@10我们已经做到90+%了,真的还需要考虑所有属性类型以及限制语义吗?
13、Learning deep graph matching with channel-independent embedding and Hungarian attention
文章链接:https://openreview.net/pdf?id=rJgBd2NYPH
Yu 等人介绍了他们的深度匹配框架,这个框架具有两个比较鲜明的特征:聚焦在聚合边缘嵌入、引入一个新的匈牙利注意力(Hungarian attention)。匈牙利算法是解决分配问题的经典方法,但它不是可微分的。
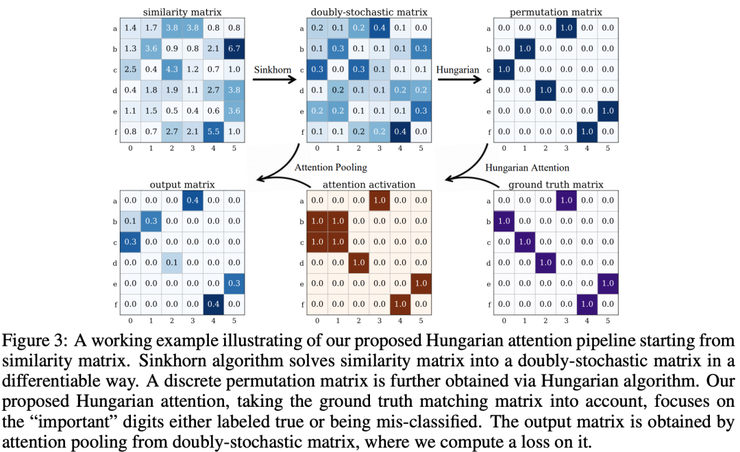
作者利用一个黑箱(带有匈牙利注意力)的输出来生成网络结构,然后把这个流进一步地传播。匈牙利注意力的方法,直观来理解一下:
1)初始步骤类似于DGMC,一些图编码器生成节点和边嵌入,且相似矩阵通过Sinkhorn规范化来传递;
2)不同的是,生成矩阵被返回到匈牙利黑箱(而不是像DGMC中那样传递迭代消息),从而生成离散矩阵;
3)通过注意力机制与基准进行比较,获得激活图,然后对其进行处理,从而获得loss。
作者仅在CV基准上进行了评估,但由于匈牙利算法的时间复杂度是O(n³),所以如果能把runtime 也放出来,可能会更有趣。
五、角色扮演游戏中的知识图谱
互动小说游戏(Interactive Fiction games,例如RPG Zork文字游戏)非常有趣,尤其是你探索完世界,然后输入一段话,等待游戏反馈的时候。
14、Graph Constrained Reinforcement Learning for Natural Language Action Spaces
文章链接:https://openreview.net/pdf?id=B1x6w0EtwH
Ammanabrolu 和 Hausknecht 提出了一项有关 IF 游戏中强化学习的新工作。这个工作中使用了 知识图谱来建模状态空间和用户交互。
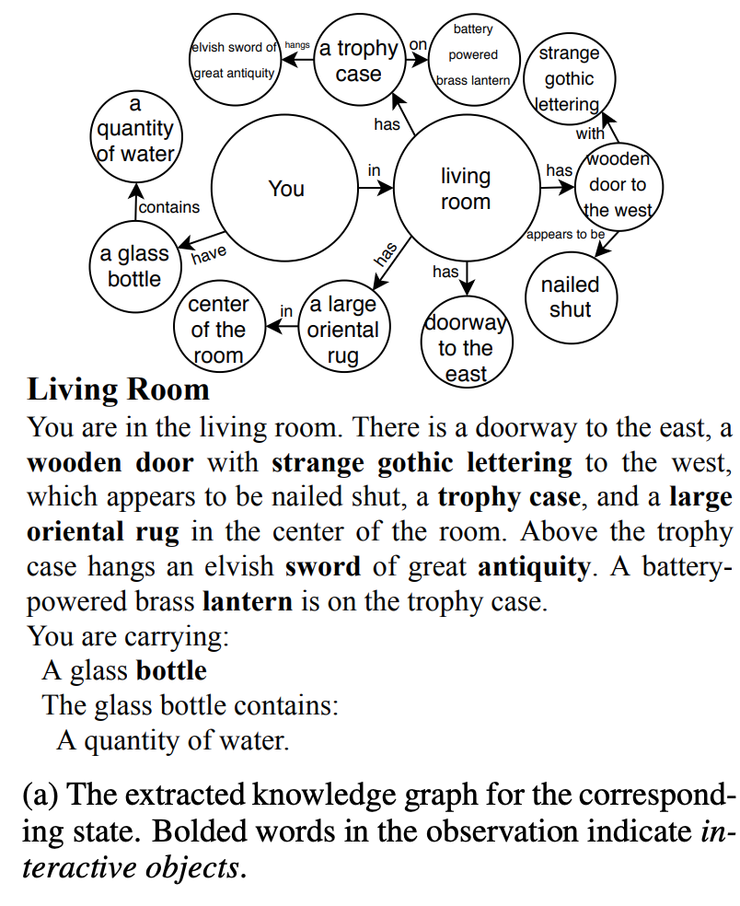
Source: Ammanabrolu and Hausknecht
例如,词汇表中有数十个模板和数百个单词。尝试所有可能的排列是不可行的。但当你维护一个可见实体的知识图谱时,agent的可选项就会大幅度减少,于是便可以更快地推进游戏。
在他们提出的编码-解码模型 KG-A2C(Knowledge Graph Advantage Actor Critic)中,编码器采用GRU进行文本输入,并使用图注意力网络构建图嵌入。此外,在解码器阶段使用可见对象的图遮掩(graph mask)。在基准测试中,KG-A2C可以玩28个游戏!
Soon they will play computer games better than us meatbags.
很快,电子游戏上,他们将比我们这些菜包子们打的更好了。
6、Conclusion
目前我们看到,知识图谱已经越来越多地应用到 AI的各个领域,特别是NLP领域。
ICML 和ACL 随后也将到来,届时我们再见。























