












阿里妹导读:随着最近几年数据计算力与机器智能算法的兴起,基于大数据 AI 算法的应用愈来愈热,大数据应用在各个行业也不断涌现。测试技术作为工程技术的一部分,也随着时代的不断变化在同步演进,在当下 DT 时代,如何测试和保障一个基于大数据的应用的软件质量,成为测试界的一个难题。
本文通过系统性地介绍阿里巴巴 AI 中台的技术质量体系——搜索推荐广告应用的质量是如何测试的,来尝试回答一下这个问题,希望能给大家带来一些借鉴,欢迎斧正,以便改进。
一 前言
最近十年来,随着移动互联网和智能设备的兴起,越来越多的数据被沉淀到各大公司的应用平台之上,这些包含大量用户特征和行为日志的数据被海量地存储起来,先经过统计分析与特征样本提取,然后再经过训练就会产出相应的业务算法模型,这些模型就像智能的机器人,它可以精准地识别和预测用户的行为和意图。
如果把数据作为一种资源的话,互联网公司与传统公司有着本质的不同,它不是资源的消耗者,而是资源的生产者,在平台运营的过程中不停地在创造新的数据资源,并且随着平台的使用时长和频率的增加,这些资源也在指数级地增长。平台通过使用这些数据和模型,又反过来带来更好的用户体验和商业价值。2016 年,AlphaGo,一个基于深度神经网络的围棋人工智能程序,第一次战胜围棋世界冠军李世石。这个由谷歌(Google)旗下 DeepMind 公司开发的算法模型,背后使用的数据正是人类棋手所有的历史棋谱数据。
阿里的搜索、推荐和广告也是非常典型的大数据应用的场景(高维稀疏业务场景),在谈如何测试之前我们需要先了解一下平台处理数据的工程技术背景。搜索、推荐、广告系统在工程架构和数据处理流程上比较相近,一般分为离线系统和在线系统两部分,见下图 1(在线广告系统一般性架构,刘鹏《计算广告》)。离线系统负责数据处理与算法模型的建模与训练,而在线系统主要用以处理用户的实时请求。在线系统会使用离线系统训练产出的模型,用以实时的在线预测,例如预估点击率。
用户在访问手机淘宝或者其他 app 的时候会产生大量的行为数据,包括用户的浏览、搜索、点击、购买、评价、停留时长等,加上商家商品维度的各类数据(广告还需要增加广告主维度的数据),这些数据经过采集过滤处理之后再经过特征提取之后生成了模型所需的样本数据,样本数据在机器学习训练平台上经过离线训练之后就可以产生用以在线服务的各类算法模型(例如深度兴趣演化网络 DIEN、Tree-based Deep Model、大规模图表示学习、基于分类兴趣的动态相似用户向量召回模型、等等)。在线系统中最主要的功能是数据的检索和在线预测服务,一般使用信息检索的相关技术,例如数据的正倒排索引、时序存储等。
搜索推荐广告系统在使用了上述维度的大数据,经过深度学习之后,成为一个千人千面的个性化系统。对于不同的用户请求,每次展现的商品和推荐的自然结果和商业结果都不尽相同,即便是同一个用户在不同的时刻得到的结果也会随着用户的实时行为的不同而改变,这些背后都是数据和算法模型的魔力。
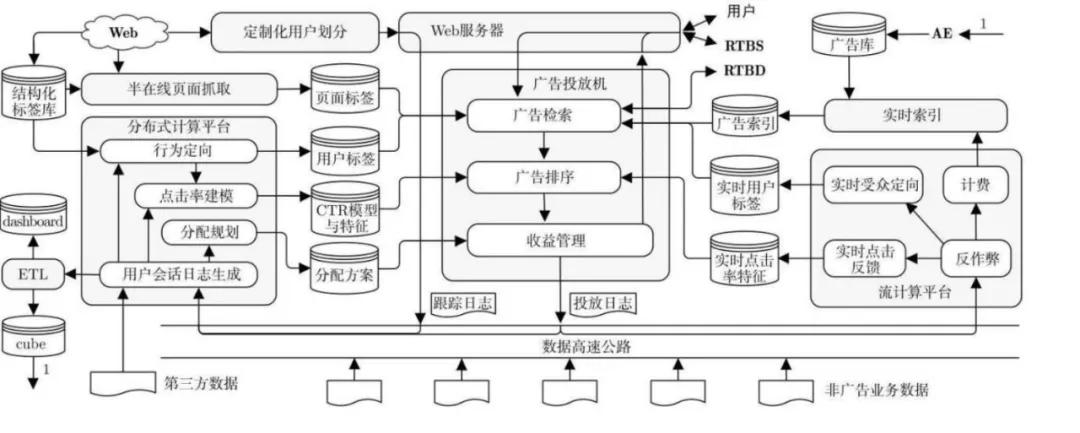
图1 在线广告系统一般性架构图
二 大数据应用测试质量域的六大挑战
在思考搜索推荐广告系统是如何测试的之前,我们首先要定义问题域,即要解决的测试问题是什么,我们的思路从以下几个方向展开。
1 功能性测试与验证
除了正常的请求与响应的检查之外,大数据的“大”主要体现在数据的完整性和丰富性。一个搜索推荐引擎的好坏很大程度上取决于其内容是否足够丰富,召回是否足够多样。另外,算法带来搜索推荐结果的不确性,但也给我们的测试验证工作造成了麻烦。所以,数据的完整性和不确定性校验也是功能测试的要点。
2 数据更新的实时性如何测试
总所周知,对于一个搜索或者广告的在线计算引擎,其内部的数据在不停地发生更新,或者出于商家在商品信息上的变更,也可能是因为广告主在创意甚至投放计划上的变化,这些更新需要实时反馈在投放引擎,否则会出现信息不一致甚至错误。如何测试和验证这些变更的及时性,即保证一定的并发带宽又保证更新链路的响应时间,这是需要测试重点关注的一个问题。
3 数据请求响应的及时性如何测试
在线服务都要求低延迟,每次 query 服务端需要在几十毫秒内给出响应结果,而整个服务端的拓扑会有大概 30 多个不同模块构成。如何测试后端服务的性能和容量就变得至关重要。
4 算法的效果如何验证
搜索推荐甚至广告的返回结果需要与用户的需求和兴趣匹配,这样才会保证更高的点击率与成交转化,但如何验证这种需求与结果的相关性,或者如何测试一个算法的效果,这是一个非常有趣且有挑战的话题。
5 AI 算法系统的线上稳定性如何保证
线下发布之前的测试是对代码的测试验收,并随着缺陷的发现与修复,提升的是代码质量。而线上的稳定性运营是为了提升系统运行的稳定性,解决的问题是:即便是一个代码质量一般的系统,如何通过技术运维的方法来提升系统的高可用性与鲁棒性,并降低线上故障的频次与影响,这一部分也被称为线上技术风险领域。
6 工程效率方向
这是对以上几个部分的补充,甚至是对整个工程研发体系在效率上的补充。质量与效率是一对孪生兄弟,也是同一个硬币的两面,如何平衡好两者之间的关系是一个难题,质量优先还是效率优先,不同的产品发展阶段有不同的侧重点。我们的工程效率,力在解决 DevOps 研发工具链路,用以提升研发的工程生产力。
自此,我们基本定义完毕大数据应用的测试问题的六大领域,有些领域已经超过了传统的测试与质量的范畴,但这也正是大数据应用给我们带来的独特质量挑战,下面我们围绕这六个问题展开讲一讲。
三 大数据应用测试六个问题的解法
1 AI 应用的功能性测试验证
功能测试主要分三块:端到端的用户交互测试、在线工程的功能测试、离线算法系统的功能测试。
1) 端到端的用户交互测试
这是涉及到搜索推荐广告系统的用户交互部分的测试验证,既包括买家端(手机淘宝、天猫 app 和优酷 app 等)的用户体验和逻辑功能的验证,也包括针对广告主和商家的客户管理平台(Business Platform)上业务流程逻辑的校验,涉及广告主在广告创意创作、投放计划设定、计费结算等方面的测试。端到端的测试保证了我们最终交付给用户和客户使用的产品质量。端上的测试技术和工具,主要涉及端到端(native/h5)app/web 上的 UI 自动化、安全、性能稳定性(monkey test/crash 率)、流量(弱网络)、耗电量、兼容性和适配,在集团其他团队的测试技术和开源技术体系的基础上我们做了一些改进和创新,例如将富媒体智能化验证引入客户端自动化测试,完成图像对比、文字 OCR、局部特征匹配、边缘检测、基于关键帧的视频验证(组件动画、贴片视频)等,解决了广告推荐在客户端上所有展现形式的验证问题。另外,针对 Java 接口和客户端 SDK 的测试,除了常规的 API Service 级别测试之外,在数据流量回放的基础上使用对比测试的方法,在接口对比、DB 对比、文件对比、流量对比的使用上有一些不错的质量效果。端到端的测试验证,由于 UI 的改版速度非常快,测试策略上我们把自动化的重点放在接口层面,UI 的 automation 只是简单的逻辑验证,全量的 UI 验证回归(功能逻辑和样式体验)还是通过手动测试,这里我们使用了不少的外包测试服务作为补充。
2) 在线工程系统的测试
这一部分是整个系统的功能测试的重点。搜索推荐广告系统,本质上是数据管理的系统,数据包括商品维度、用户维度、商家和广告主维度的数据。把大量的数据按照一定的数据结构存储在机器内存之中,提供召回、预估、融合等服务,这些都是在线工程要去解决的问题。这部分的功能测试,基本原理是通过发送 Request/Query 请求串、验证 Response 结果的模式,在此基础上使用了比较多提升测试用例生成效率和执行效率的技术。基于可视化、智能化等技术(智能用例生成、智能回归、失败智能归因、精准测试覆盖、功能 A/B 测试),把测试方法论融入其中,解决了大规模异构的在线工程功能测试 case 编写成本高、debug 难、回归效率低的问题。搜索推荐广告的在线服务工程基本上由 20 - 30 个不同的在线模块组成,测试这些在线服务模块极其消耗时间,用例的编写效率和回归运行效率是优化的主要目标,在这个方向上,我们在用例生成方面通过用例膨胀和推荐技术、基于遗传算法动态生成有效测试用例、在用例执行阶段使用动态编排的回归技术,通过这些技术极大地提升了在线模块的功能测试的覆盖率。
此外,我们比较多地使用线上的 Query 做对比测试的方法,用以验证功能变更的差异,分析即将发布的系统与实际线上系统之间的结果一致率和数据分布可以很好地找到系统的功能性问题。在线上测试领域,除了对比测试,我们把近期 Top-N 的 Query 在线上定时做巡检监察,一方面起到功能监控的作用,另一方面 Query 量级到一定程度(例如最近一周 80% 的长尾 Query),可以很轻松地验证引擎数据的完整性和多样性。最后,这一部分的测试策略也需要强调一下,由于算法的逻辑(例如召回和排序的业务逻辑)非常复杂,涉及不同的业务和分层模型,这些逻辑是算法工程师直接设计实现的,所以算法逻辑的测试用例的设计和执行也是由算法工程师来做,只有他们最清楚模型的功能逻辑和如何变化。结合着线上 debug 系统的使用,算法工程师可以很清楚目前线上运行的算法和线下即将上线的算法之间的逻辑差异,测试用例也就比较容易编写。测试工程师在其中主要负责整个测试框架和工具环境的搭建,以及基本测试用例的编写与运行。这个测试策略的调整,在本文最后关于测试未来的预判部分也有介绍。
3) 离线系统的测试,或者算法工程测试
从数据流程的角度看,算法工程包括算法模型的建模流程和模型训练上线两部分,从特征提取、样本生成、模型训练、在线预测,整个pipeline离线流程到在线的过程中如何验证特征样本的质量和模型的质量。所以算法测试的关键在于三个地方:
a.样本特征质量的评估
b.模型质量的评估
c.模型在线预估服务的质量保障
a 和 b 涉及数据质量与特征功效放在一起在第四部分介绍,主要使用数据质量的各种指标来评估质量。
这里重点说一下 c,算法在线预估服务上线前的测试,因为其涉及到模型最终服务的质量,比较重要。我们这里使用了一种小样本离线在线打分对比的方法,可以最终比较全面地验证模型上线质量的问题。详细过程是:在模型上线正式服务之前,需要对模型做测试验证,除了准备常规的 test 数据集,我们单独分离出一部分样本集,称之为小样本数据集,通过小样本数据集在线系统的得分与离线分数的对比的差异,验证模型的在线服务质量,这种小样本打分实际上也提供了类似于灰度验证的能力。流程见下图 2。
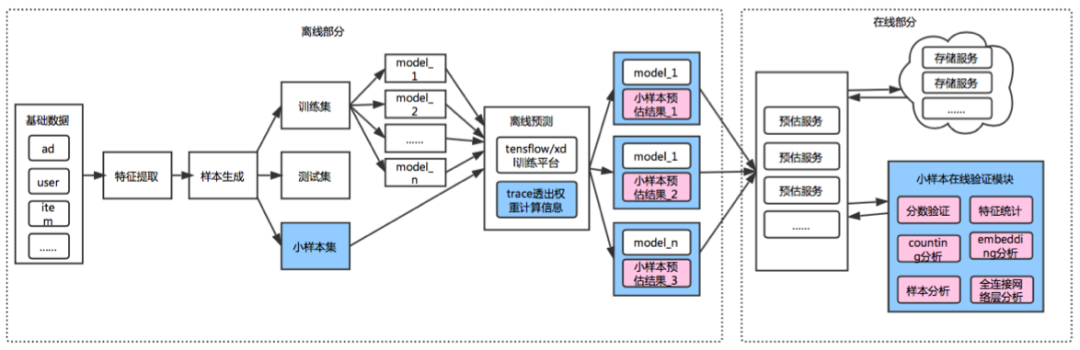
图2 小样本测试
关于离线系统的测试,我们同时在深度学习训练平台的质量保障上也做了一些探索,目前深度学习平台质量主要面临三大难点:
- 由于种种复杂状况,在集群上训练的模型存在训练失败的风险,如何提前预警深度学习平台当前存在的潜在风险。
- 由于神经网络天然局部最优解基因和 Tensorflow Batch 的设计思路,每次训练的模型,如何保障它是否满足上线的质量要求。
- 如何验证在大规模数据集和分布式系统下深度学习平台提供的各种深度学习功能的准确性。
针对这三大问题,我们尝试了三个解法:
- 实验预跑法,设计特别的模型和训练数据,15 分钟内训练完毕。可以快速发现和定位训练平台的问题,在大规模的生产模型正式训练之前就发现问题。
- Model on Model 的模型验证法,把模型生产的中间数据指标(除 auc 之外,还包括神经元激活率、梯度在各层传到均方差等)透传加工建模,监控生产模型的质量。
- Model Based 功能校验法,针对性地设计样本格式和测试模型网络,使模型 variable 的理论值能够精确计算出,根据训练模型的结果验证平台的质量。
2 数据更新的实时性如何测试的问题
这一部分主要包含两个子问题:
1) 引擎数据的实时更新链路的测试
对于一个实时更新链路,从上游的数据源/数据表(TT/MetaQ/ODPS,阿里的消息中间件与离线数据表)读取数据,经过 Streaming 计算平台(Bayes 引擎、Blink 等,阿里的实时计算平台)的实时计算任务处理产出引擎可以接受的更新消息,引擎在收到此类消息之后再做数据的更新操作。这个链路主要验证的点在于:
- 数据的正确性验证
- 数据的一致性验证
- 数据的时效性验证
- 数据的并发性能测试
在这几个问题的解决上,我们使用了流式数据实时对比、全量对比可以解决数据的正确性和一致性验证的问题;数据的时效性更多地依赖计算平台底层的资源来保证毫秒级别的更新速度,我们这里通过记录更新时间戳来验证更新的时效性;性能测试通过伪造上游数据和流量复制来验证整个链路的响应时间和并发处理能力。
2) 模型的实时更新(Online Deep Learning)链路如何测试
为了拿到实时行为带来的算法收益,Online Deep Learning(ODL)最近两年兴起,用户实时行为特征数据也需要实时地训练到模型之中,在 10-15 分钟的时间间隔里,在线服务的模型会被更新替代,留给模型验证的时间最多只有 10 分钟的时间,这是 ODL 带来的质量挑战。解这个问题,我们有两个方法同时工作。
(1)最主要的方法是建立 ODL 全链路质量指标监控体系,这里的链路是指从样本构建到在线预测的全链路,包括样本域的指标校验和训练域指标校验。
指标选取上主要看是否跟效果相关联,例如对于 ctr 预估方向,可以计算测试集上的 auc、gauc(Group auc,分组后的 auc)、score_avg(模型打分均值)等指标,甚至计算train_auc & test_auc,pctr & actual_ctr 之间的差值(前者看是否过拟合,后者看打分准度)是不是在一个合理的范围内。这里也有一个关键的点在于测试集的选取,我们建议测试集除了取下一个时间窗口的数据(用未见的数据测试模型的泛化性能),还可以包含从过去一段时间(比如一周)的数据里面随机抽样的一部分数据(用已见但全面的数据测试模型是否跑偏)。同时,这也降低了局部的异常测试样本对评估指标带来的扰动影响。
(2)除了指标体系之外,我们设计了一个离线仿真的系统,在模型正式上线之前在仿真环境模拟打分校验。
简单来说就是把需要上线的模型,在线下测试环境利用线上流量通过在线服务的组件打分模块进行一个提前的预打分,在这个打分过程中出现任何错误都算校验不通过,打分正常的模型再对分数进行均值和分布的校验,打分校验不通过会直接拒绝上线。通过以上两种方案,结合样本与模型的监控与拦截,可以极大概率低降低 ODL 的质量风险。
3 性能压测
对于由离线、在线两部分构成的AI系统,在线是响应的是用户实时访问请求,对响应时间要求更高,在线系统的性能是这一部分的重点。离线的性能很大程度上取决于训练平台在计算资源方面的调度使用,我们一般通过简单的源头数据复制来做验证。对于在线系统,分为读场景和写场景的性能测试,写场景的性能在第二部分实时更新链路的时效性部分已有介绍,这里主要讲一下在线场景的读场景的性能容量测试。
在线系统一般由二三十个不同的引擎模块组成,引擎里的数据 Data 与测试 Query 的不同都会极大的影响性能测试结果,同时也由于维护线下的性能测试环境与线上环境的数据同步工作需要极大的代价,我们目前的策略都是选择在线上的某个生产集群里做性能容量测试。对于可以处理几十万 QPS(Query Per Second)的在线系统,难点在于如何精准控制产生如此量级的并发 Query,使用简单的多线程或多进程的控制已经无法解决,我们在这里使用了一个爬山算法(梯度多伦迭代爬山法)来做流量的精准控制,背后是上百台的压力测试机器递增式地探测系统性能水位。
另外一个建设的方向是整个压测流程的自动化以及执行上的无人值守,从基于场景的线上 Query 的自动选取、到压力生成、再到均值漂移算法的系统自动化校验工作,整个压测流程会如行云流水一般的按照预设自动完成。配合着集群之间的切流,可以做到白+黑(白天夜间)的日常压测,对线上水位和性能瓶颈的分析带来了极大的便利。
4 效果的测试与评估
这是大数据应用算法的重头戏,由于算法的效果涉及到搜索广告业务的直接受益(Revenue & GMV),我们在这个方向上也有比较大的投入,分为以下几个子方向。
1) 特征与样本的质量与功效评估
通过对特征质量(有无数据及分布问题),以及特征效用(对算法有无价值)两个角度出发,在特征指标计算上找到一些比较重要的指标:缺失率占比、高频取值、分布变化、取值相关性等。同时,在训练和评估过程中大量中间指标与模型效果能产生因果关系,通过系统的分析建模张量、梯度、权重和更新量,能够对算法调优、问题定位起到辅助决策作用。
而且,通过改进 AUC 算法,分析 ROC、PR、预估分布等更多评估指标,能够更全面的评估模型效果。随着数据量级的增加,最近两年我们在建模和训练过程中使用了千亿参数、万亿样本,Graph Deep Learning 也进入百亿点千亿边的阶段,在如此浩瀚的数据海洋里,如何可视化特征样本以及上述的各种指标成为一个难点,我们在 Google 开源的 Tensorboard 的基础上做了大量的优化与改进,帮助算法工程师在数据指标的可视化、训练过程的调试、深度模型的可解释性上给与了较好的支持。
2) 在线流量实验
算法项目在正式上线之前,模型需要在实验环境中引入真实的线上流量进行效果测试和调优,在第一代基于Google分层实验架构的在线分层实验(原理 Google 论文“Overlapping Experiment Infrastructure More, Better, Faster Experimentation”)的基础上,我们在并发实验、参数管理、参数间相互覆盖、实验质量缺乏保障、实验调试能力缺失、实验扩展能力不足等方面做了很多的改进,极大地提升了流量的并发复用与安全机制,达到真正的生产实验的目的。在效果上,通过在线实验平台引入的真实流量的验证,使得模型的效果质量得到极大的保障。
3) 数据效果评测
这里分两块:相关性评测与效果评测。相关性是相关性模型的一个很重要的评估指标,我们主要通过数据评测来解决,通过对搜索展示结果的指标评测,可以得到每次搜索结果的相关性分数,细分指标包括:经典衡量指标 CSAT (Customer Satisfaction,包括非常满意、满意、一般、不满意、非常不满意)、净推荐值 NPS (Net Promoter Score,由贝恩咨询企业客户忠诚度业务的创始人 Fred Reichheld 在 2003 年提出,它通过测量用户的推荐意愿,从而了解用户的忠诚度)、CES (Customer Effort Score,“客户费力度”是让用户评价使用某产品/服务来解决问题的困难程度)、HEART 框架(来源于 Google,从愉悦度 Happiness、Engagement 参与度、Adoption 接受度、Retention 留存率、Task success 任务完成度)。
效果评估方面,我们采用了数据统计与分析的方法。在一个算法模型真正全量投入服务之前,我们需要准确地验证这个模型的服务效果。除了第一部分介绍的离在线对比之外,我们需要更加客观的数据指标来加以佐证。这里我们采用了真实流量的 A/B 实验测试的方法,给即将发布的模型导入线上 5% 的流量,评估这 5% 流量和基准桶的效果对比,从用户体验(相关性)、平台收益、客户价值三个维度做各自实际指标的分析,根据用户的相关性评测结果、平台的收入或者 GMV、客户的 ROI 等几个方面来观测一个新模型对于买家、平台、卖家的潜在影响到底是什么,并给最终的业务决策提供必要的数据支撑。流量从 5% 到 10%,再到 20% 以及 50%,在这个灰度逐渐加大至全量的过程中,无论是功能问题、还是性能的问题,甚至效果的问题都会被探测到,这种方法进一步降低了重大风险的发生。这是一个数据统计分析与技术的融合的方案,与本文所介绍的其他技术方法不同,比较独特,但效果甚佳。
5 线上稳定性
与其他业务的稳定性建设类似,通过发布三板斧(灰度、监控、回滚)来解决发布过程的质量,通过线上的容灾演练、故障注入与演练(我们也是集团开源的混沌工程 Monkey King 的 C++ 版本的提供者)、安全红蓝对抗攻防来提升系统线上的稳定性和可用性。另外在 AI Ops 和 Service Mesh 为基础的运维管控方向上,我们正在向着智能运维、数据透视分析、自动切流、自动扩缩容等方向努力。我们预测结合 Service Mesh 技术理念在 C++ 在线服务的演进,系统会具备对业务应用无侵入的流量标定及变更标定的能力,也就能够实现流量调度能力和隔离的能力。另外,红蓝攻防也将进一步发展,自动化、流程化将逐步成为混沌工程实施的标准形式。由于这一部分尚处于起步阶段,这里不再过多介绍还没有实现的内容,但我们判定这个方向大有可为,与传统运维工作不同,更接近 Google 的 SRE(Site Reliability Engineering)理念。
6 AI 应用的工程效能
主要解决在测试阶段和研发阶段提升效率的问题,这个方向上我们以 DevOps 工具链建设为主,在开发、测试、工程发布、模型发布(模型 debug 定位)、客户反馈(体感评估、众测、客户问题 debug)整个研发闭环所使用到的工具方面的建设。在我们设想的 DevOps 的场景下,开发同学通过使用这些工具可以独立完成需求的开发测试发布及客户反馈的处理。鉴于这个方向与测试本身关系不大,篇幅原因,这里也略过。
四 大数据应用测试的未来
至此,关于大数据应用测试的几个主要问题的解法已经介绍完毕。关于大数据应用测试的未来,我也有一些自己初步的判断。
1 后端服务测试的工具化
这涉及到服务端的测试转型问题,我们的判断是后端服务类型的测试不再需要专职的测试人员,开发工程师在使用合理的测试工具的情况下可以更加高效地完成测试任务。专职的测试团队,未来会更多地专注于偏前端与用户交互方面产品质量的把控,跟产品经理一样,需要从用户的角度思考产品质量的问题,产品的交付与交互的验证是这个方向的重点。多数的服务端的测试工作都是可以自动化的,且很多 service 级别的验证也只有通过自动化这种方式才能验证。相比较测试同学,开发同学在 API 级别的自动化代码开发方面能力会更强,更重要的是开发同学自己做测试会减少测试同学与开发同学之间的大量往返沟通的成本,而这个成本是整个发布环节中占比较大的部分。再者,第一部分介绍过,算法工程师在业务逻辑的理解上更加清晰。
所以,我们更希望后端的测试工作由工程或者算法工程师独立完成,在这种新的生产关系模式下,测试同学更加专注于测试工具的研发,包括自动化测试框架、测试环境部署工具、测试数据构造与生成、发布冒烟测试工具、持续集成与部署等。这种模式也是目前 Google 一直在使用的测试模式,我们今年在这个方向下尝试了转型,在质量变化和效率提升方面这两方面效果还不错。作为国内互联网公司的率先进行的测试转型之路,相信可以给到各位同行一些借鉴。这里需要强调一点的是,虽然测试团队在这个方向上做了转型,但后端测试这个事情还是需要继续做,只是测试任务的执行主体变成了开发工程师,本文介绍的大量后端测试的技术和方向还会继续存在。后端服务类测试团队转型,除了效能工具之外,第五部分的线上稳定性的建设是一个非常好的方向。
2 测试的线上化,既 TIP(Test In Production)
这个概念大概十年前由微软的工程师提出。TIP 是未来测试方法上的一个方向,主要的考虑是以下三点。
1)一方面由于线下测试环境与真实线上环境总是存在一些差异,或者消除这种差异需要较大的持续成本,导致测试结论不够置信。使用最多的就是性能测试或容量测试,后端服务的拓扑非常复杂,且许多模块都有可扩展性,带有不同的数据对性能测试的结果也有很大的影响,测试环境与生产环境的这种不同会带来测试结果的巨大差异。另外,目前的生产集群都是异地多活,在夜里或者流量低谷的时候,单个集群就可以承担起所有流量请求,剩下的集群可以很方便地用来压测,这也给我们在线上做性能测试带来了可能性。最具典型的代表就是阿里的双十一全链路压测,今年基本上都是在白加黑的模式下完成的。
2)另外,许多真实的演练测试也只能在线上系统进行,例如安全攻防和故障注入与演练,在线下测试环境是无法做到的。
3)最后,从质量的最终结果上看,不管是发布前的线下测试,还是发布后的线上稳定性建设,其目的都是为了减少系统故障的发生,把这两部分融合在一起,针对最终的线上故障的减少去做目标优化工作,可以最大程度地节约和利用人力资源。我们判断,线下测试与线上稳定性的融合必将是一个历史趋势,这一领域统称为技术风险的防控。
3 测试技术的智能化
见图 3。类似对自动驾驶的分级,智能化测试也有不同的成熟度模型,从人工测试、自动化、辅助智能测试、高度智能测试。机器智能是一个工具,在测试的不同阶段都有其应用的场景,测试数据和用例设计阶段、测试用例回归执行阶段、测试结果的检验阶段、线上的指标异常检测诸多技术风险领域都可以用到不同的算法和模型。智能化测试是发展到一定阶段的产物,前提条件就是数字化,自动化测试是比较简单一种数字化。没有做到数字化或者自动化,其实是没有智能分析与优化的诉求的。
另外,在算法的使用上,一些简单算法的使用可能会有不错的效果,比较复杂的深度学习甚至强化学习算法的效果反而一般,原因或者难点在两个地方,一个是特征提取和建模比较困难,第二个原因是测试运行的样本与反馈的缺失。但无论如何,运用最新的算法技术去优化不同的测试阶段的效率问题,是未来的一个方向。但我们同时判断,完全的高度智能测试与无人驾驶一样,目前还不成熟,主要不在算法与模型,而是测试数据的不足。
图3 测试技术的智能化
阿里的搜索推荐与广告系统的质量建设之路,经过近 10 年的不断发展,在许多前辈的不断努力付出之下,才能在如此众多的细分领域方向上开花结果,本文所介绍的方法也都浓缩在内部的工具兵器之中,后面我们的想法还是逐渐开源,回馈社区。限于篇幅,内容又较杂多,很多技术细节这里并没有办法细细展开。如果想了解更多,后继可以关注即将由阿里经济体技术质量小组主导出版的测试书籍《阿里巴巴测试之道》(电子工业出版社,暂定书名),本文所介绍的大数据AI算法应用测试被收录在第六章。如果还是需要更加详尽的了解,也欢迎大家加入我们的团队或者开源社区,一起在以上的几个方向做更加深入的研究与建设。
















