如果您曾经参与过数据科学项目,那么您可能会意识到数据挖掘的第一步和主要步骤是数据预处理。在现实生活问题中,我们得到的原始数据往往非常混乱,机器学习模型无法识别模式并从中提取信息。
1.处理空值:
空值是数据中任何行或列中缺失的值。空值出现的原因可能是没有记录或数据损坏。在python中,它们被标记为“Nan”。您可以通过运行以下代码来检查它
- data.isnull().sum()
我们可以用该列的平均值或该列中最频繁出现的项来填充这些空值。或者我们可以用-999这样的随机值替换Nan。我们可以使用panda库中的fillna()函数来填充Nan的值。如果一列有大量的空值(假设超过50%),那么将该列从dataframe中删除会更好。您还可以使用来自同一列中不为空的k近邻的值来填充空值。Sklearn的KNNImputer()可以帮助您完成这项任务。
2. 处理离群值:
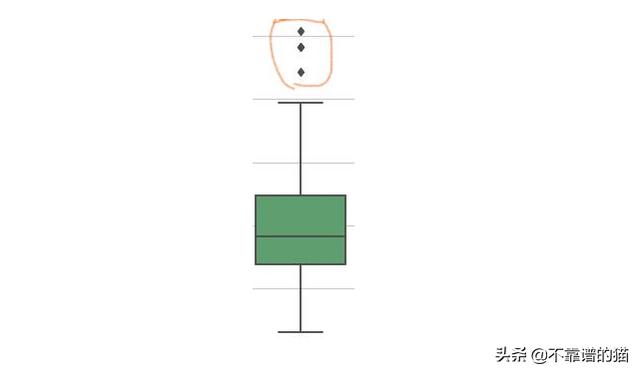
离群值是与数据中的其他值保持一定距离的数据点。我们可以使用可视化工具(例如Boxplots)来检测离群值:
通过绘制两个特征向量之间的散点图:
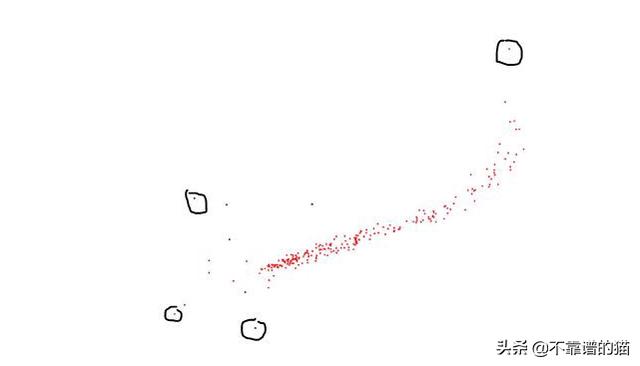
散点图中的离群值
如果您了解数据背后的科学事实(例如这些数据点必须位于的范围),则可以将离群值排除在外。例如,如果年龄是您数据的特征,那么您就知道它必须介于0到100之间(或在某些情况下介于0到130岁之间)。但是,如果数据中的年龄值有些荒谬,例如300,那么必须将其删除。如果机器学习模型的预测很关键,即微小的变化都很重要,那么您就不应该放弃这些离群值。同样,如果离群值大量存在(例如25%或更多),那么它们很有可能代表有用的东西。在这种情况下,您必须仔细检查离群值。
3. 归一化或数据缩放:
如果您使用的是基于距离的机器学习算法,例如K近邻,线性回归,K均值聚类或神经网络,那么在将数据输入机器学习模型之前,对数据进行归一化是一个好习惯。归一化是指修改数值特征的值以使其达到共同的标度而不改变它们之间的相关性。不同数值特征中的值位于不同的范围内,这可能会降低模型的性能,因此归一化可以确保在进行预测时为特征分配适当的权重。一些常用的归一化技术是:
a)Min-Max归一化 -将特征缩放到最小和最大值之间的给定范围。公式为:
X(scaled)=a+ (b-a)(X - Xmin)/(Xmax - Xmin)
其中a是最小值,b是最大值。
b)Z-score归一化 -我们从每个特征中减去均值,然后除以其标准差,以使得到的缩放特征具有零均值和单位方差。公式为:
X(scaled)=(X - mean(X)) /σ
这样,您可以将数据的分布更改为正态分布。
4. 编码分类特征
分类特征是包含离散数据值的特征。如果一个分类特征有字符、单词、符号或日期作为数据值,那么这些数据必须被编码成数字,以便机器学习模型能够理解,因为它们只处理数字数据。有三种方法来编码你的数据:
a)标签编码:在 这种类型的编码中,分类特征中的每个离散值都根据字母顺序分配一个唯一的整数。在下面的示例中,您可以看到为每个水果分配了一个相应的整数标签:
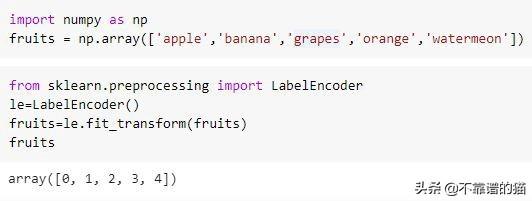
标签编码通常适用于线性模型,如线性回归,Logistic回归以及神经网络。
b)One-hot:在这种编码类型中,分类特征中的每个离散值都分配有唯一的one-hot向量或由1和0组成的二进制向量。在one-hot向量中,仅离散值的索引标记为1,其余所有值标记为0。在下面的示例中,您可以看到为每个水果分配了对应的长度为5的one-hot向量:
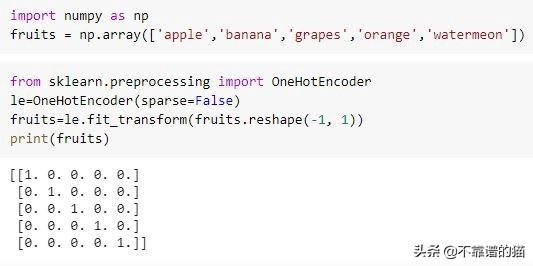
one-hot编码通常可与基于树的模型(例如随机森林和梯度提升机)配合使用。
c)均值编码-在 这种类型的编码中,分类特征中的每个离散值都使用相应的均值目标标签进行编码。为了更好地理解,让我们看下面的示例:
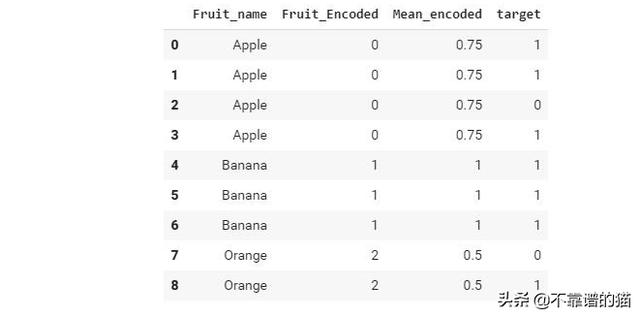
我们有三个水果标签['Apple','Banana','Orange']。每个水果标签的平均编码公式如下:
Encoded feature = True targets/Total targets
对于Apple来说,true targets是3,total targets是4,因此Apple的均值编码是3/4 =0.75。类似地,Orange的编码是1/2=0.5,banana的编码是3/3 =1。均值编码是标签编码的扩展版本,由于它考虑了目标标签,因此与之相比更符合逻辑。
5. 离散化:
这也是一种很好的预处理技术,有时可以通过减小数据大小来提高模型的性能。它主要用于数值特征。在离散化中,数字特征分为bin / intervals。每个bin都包含一定范围内的数值。一个bin中的值数量可以相同,也可以不同,然后将每个bin视为分类值。我们可以使用离散化将数值特征转换为分类特征。
这些是实现机器学习模型时可以用来预处理数据的不同方法。希望本文对您有所帮助。