













好看请赞,养成习惯
- 你有一个思想,我有一个思想,我们交换后,一个人就有两个思想
- If you can NOT explain it simply, you do NOT understand it well enough
上一篇文章 面试问我,创建多少个线程合适?我该怎么说 从定性到定量的分析了如何创建正确个数的线程来最大化利用系统资源(其实就是几道小学数学题)。通常来讲,有了个这个知识点傍身,按需手动创建相应个数的线程就好
但是现实中,你也许听过或者被要求:
尽量避免手动创建线程,应使用线程池统一管理线程
为什么会有这样的要求?背后的道理又是怎样的呢?顺着这个经验理论来推断,那肯定是手动创建线程有缺点
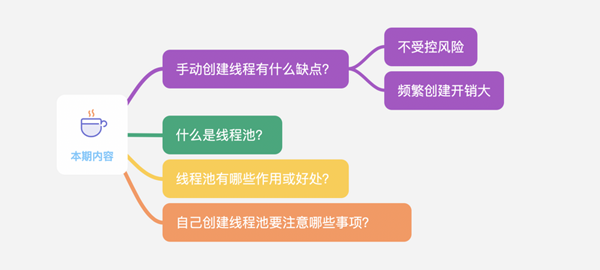
手动创建线程有什么缺点?
- 不受控风险
- 频繁创建开销大
不受控风险
这个缺点,相信你也可以说出一二
系统资源有限,每个人针对不同业务都可以手动创建线程,并且创建标准不一样(比如线程没有名字)。当系统运行起来,所有线程都在疯狂抢占资源,无组织无纪律,混乱场面可想而知(出现问题,自然也就不可能轻易的发现和解决)
如果有位神奇的小伙伴,为每个请求都创建一个线程,当大量请求铺面而来的时候,这好比一个正规木马程序,内存被无情榨干耗尽(你无情,你冷酷,你无理取闹)
另外,过多的线程自然也会引起上下文切换的开销
总的来说,不受控风险很大
频繁创建开销大
面试问: 频繁手动创建线程有什么问题?
答: 开销大
这貌似是一个不假思索就可以回答出来的正确答案。那我要继续问了
面试官: 创建一个线程干了什么就开销大了?和我们创建一个普通 Java 对象有什么差别?
答: ... 嗯...啊
按照常规理解 new Thread() 创建一个线程和 new Object() 没有什么差别。Java中万物接对象,因为 Thread 的老祖宗也是 Object
如果你真是这么理解的,说明你对线程的生命周期还不是很理解,请回看之前的 Java线程生命周期这样理解挺简单的
在这篇文章中我们明确说明,new Thread() 在操作系统层面并没有创建新的线程,这是编程语言特有的。真正转换为操作系统层面创建一个线程,还要调用操作系统内核的API,然后操作系统要为该线程分配一系列的资源
废话不多说,我们将二者做个对比:

new Object() 过程
Object obj = new Object();
- 1.
当我需要【对象】时,我就会给自己 new 一个(不知你是否和我一样),这个过程你应该很熟悉了:
- 分配一块内存 M
- 在内存 M 上初始化该对象
- 将内存 M 的地址赋值给引用变量 obj
就是这么简单
创建一个线程的过程
上面已经提到了,创建一个线程还要调用操作系统内核API。为了更好的理解创建并启动一个线程的开销,我们需要看看 JVM 在背后帮我们做了哪些事情:
- 它为一个线程栈分配内存,该栈为每个线程方法调用保存一个栈帧
- 每一栈帧由一个局部变量数组、返回值、操作数堆栈和常量池组成
- 一些支持本机方法的 jvm 也会分配一个本机堆栈
- 每个线程获得一个程序计数器,告诉它当前处理器执行的指令是什么
- 系统创建一个与Java线程对应的本机线程
- 将与线程相关的描述符添加到JVM内部数据结构中
- 线程共享堆和方法区域
这段描述稍稍有点抽象,用数据来说明创建一个线程(即便不干什么)需要多大空间呢?答案是大约 1M 左右
java -XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary -XX:+PrintNMTStatistics -version
- 1.
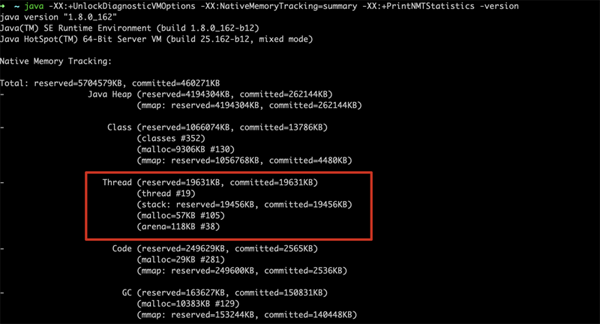
上图是我用 Java8 的测试结果,19个线程,预留和提交的大概都是19000+KB,平均每个线程大概需要 1M 左右的大小(Java11的结果完全不同,这个大家自行测试吧)
相信到这里你已经明白了,对于性能要求严苛的现在,频繁手动创建/销毁线程的代价是非常巨大的,解决方案自然也是你知道的线程池了
什么是线程池?
你常见的数据库连接池,实例池,还有XX池,OO池,各种池,都是一种池化(pooling)思想,简而言之就是为了最大化收益,并最小化风险,将资源统一在一起管理的思想
Java 也提供了它自己实现的线程池模型—— ThreadPoolExecutor。套用上面池化的想象来说,Java线程池就是为了最大化高并发带来的性能提升,并最小化手动创建线程的风险,将多个线程统一在一起管理的思想
为了了解这个管理思想,我们当前只需要关注 ThreadPoolExecutor 构造方法就可以了
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
这么复杂的构造方法在JDK中还真是不多见,为了个更形象化的让大家理解这几个核心参数,我们以多数人都经历过的春运(北京——上海)来说明
| 序号 | 参数名称 | 参数解释 | 春运形象说明 |
|---|---|---|---|
| 1 | corePoolSize | 表示常驻核心线程数,如果大于0,即使本地任务执行完也不会被销毁 | 日常固定的列车数辆(不管是不是春运,都要有固定这些车次运行) |
| 2 | maximumPoolSize | 表示线程池能够容纳可同时执行的最大线程数 | 春运客流量大,临时加车,加车后,总列车次数不能超过这个最大值,否则就会出现调度不开等问题 (结合workqueue) |
| 3 | keepAliveTime | 表示线程池中线程空闲的时间,当空闲时间达到该值时,线程会被销毁,只剩下 corePoolSize 个线程位置 |
春运压力过后,临时的加车(如果空闲时间超过keepAliveTime)就会被撤掉,只保留日常固定的列车车次数量用于日常运营 |
| 4 | unit | keepAliveTime 的时间单位,最终都会转换成【纳秒】,因为CPU的执行速度杠杠滴 |
keepAliveTime 的单位,春运以【天】为计算单位 |
| 5 | workQueue | 当请求的线程数大于 corePoolSize 时,线程进入该阻塞队列 |
春运压力异常大,(达到corePoolSize)也不能满足要求,所有乘坐请求都会进入该阻塞队列中排队, 队列满,还有额外请求,就需要加车了 |
| 6 | threadFactory | 顾名思义,线程工厂,用来生产一组相同任务的线程,同时也可以通过它增加前缀名,虚拟机栈分析时更清晰 | 比如(北京——上海)就属于该段列车所有前缀,表明列车运输职责 |
| 7 | handler | 执行拒绝策略,当 workQueue 达到上限,同时也达到 maximumPoolSize 就要通过这个来处理,比如拒绝,丢弃等,这是一种限流的保护措施 |
当workQueue排队也达到队列最大上线,maximumPoolSize 就要提示无票等拒绝策略了,因为我们不能加车了,当前所有车次已经满负载 |
整体来看就是这样:
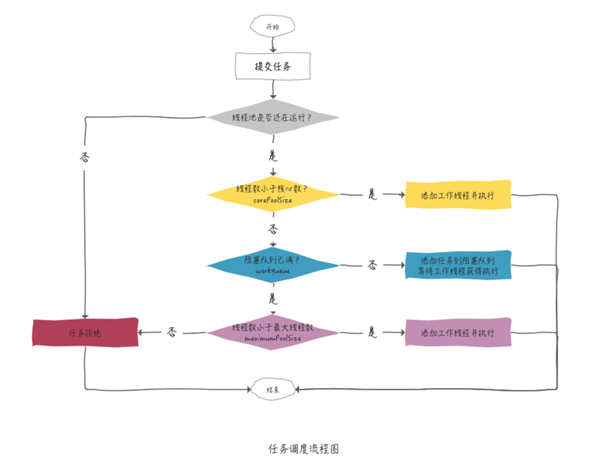
试想,如果有请求就新建一趟列车,请求结束就“销毁”这趟列车,频繁往复这样操作,这样的代价肯定是不能接受的。
可以看到,使用线程池不但能完成手动创建线程可以做到的工作,同时也填补了手动线程不能做到的空白。归纳起来说,线程池的作用包括:
- 利用线程池管理并服用线程,控制最大并发数(手动创建线程很难得到保证)
- 实现任务线程队列缓存策略和拒绝机制
- 实现某些与实践相关的功能,如定时执行,周期执行等(比如列车指定时间运行)
- 隔离线程环境,比如,交易服务和搜索服务在同一台服务器上,分别开启两个线程池,交易线程的资源消耗明显要大。因此,通过配置独立的线程池,将较慢的交易服务与搜索服务个离开,避免个服务线程互相影响
相信到这里,你已经了解线程池的基本思想了,在使用过程中还是有几个注意事项要说明一下的
线程池使用思想/注意事项
不能忽略的线程池拒绝策略
我们很难准确的预测未来的最大并发量,所以定制合理的拒绝策略是必不可少的步骤。默认情况, ThreadPoolExecutor 提供了四种拒绝策略:

- AbortPolicy:默认的拒绝策略,会 throw RejectedExecutionException 拒绝
- CallerRunsPolicy:提交任务的线程自己去执行该任务
- DiscardOldestPolicy:丢弃最老的任务,其实就是把最早进入工作队列的任务丢弃,然后把新任务加入到工作队列
- DiscardPolicy:相当大胆的策略,直接丢弃任务,没有任何异常抛出
不同的框架(Netty,Dubbo)都有不同的拒绝策略,我们也可以通过实现 RejectedExecutionHandler 自定义的拒绝策略
对于采用何种策略,具体要看执行的任务重要程度。如果是一些不重要任务,可以选择直接丢弃;如果是重要任务,可以采用降级(所谓降级就是在服务无法正常提供功能的情况下,采取的补救措施。具体采用何种降级手段,这也是要看具体场景)处理,例如将任务信息插入数据库或者消息队列,启用一个专门用作补偿的线程池去进行补偿
没有绝对的拒绝策略,只有适合那一个,但在设计过程中千万不要忽略掉拒绝策略就可以
禁止使用Executors创建线程池
相信很多人都看到过这个问题(阿里巴巴Java开发手册说明禁止使用 Executors 创建线程池),我把出处(P247)截图在此:

Executors 大大的简化了我们创建各种类型线程池的方式,为什么还不让使用呢?
其实,只要你打开看看它的静态方法参数就会明白了
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- 1.
- 2.
- 3.
- 4.
- 5.
传入的workQueue 是一个边界为 Integer.MAX_VALUE 队列,我们也可以变相的称之为无界队列了,因为边界太大了,这么大的等待队列也是非常消耗内存的
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
另外该 ThreadPoolExecutor方法使用的是默认拒绝策略(直接拒绝),但并不是所有业务场景都适合使用这个策略,当很重要的请求过来直接选择拒绝显然是不合适的
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
总的来说,使用 Executors 创建的线程池太过于理想化,并不能满足很多现实中的业务场景,所以要求我们通过 ThreadPoolExecutor来创建,并传入合适的参数
总结
当我们需要频繁的创建线程时,我们要考虑到通过线程池统一管理线程资源,避免不可控风险以及额外的开销
了解了线程池的几个核心参数概念后,我们也需要经过调优的过程来设置最佳线程参数值(这个过程时必不可少的)
线程池虽然弥补了手动创建线程的缺陷和空白,同时,合理的降级策略能大大增加系统的稳定性
阿里巴巴手册都是前辈们无数填坑后总结的精华,你也应该遵守相应的指示,结合自己的实际业务场景,设定合适的参数来创建线程池

























