













引言
随着大数据时代的来临,大数据产品层出不穷。我们最近也对一款业内非常火的大数据产品 - Apache Flink做了调研,今天与大家分享一下。Apache Flink(以下简称flink) 是一个旨在提供‘一站式’ 的分布式开源数据处理框架。是不是听起来很像spark?没错,两者都希望提供一个统一功能的计算平台给用户。虽然目标非常类似,但是flink在实现上和spark存在着很大的区别,flink是一个面向流的处理框架,输入在flink中是无界的,流数据是flink中的头等公民。说到这里,大家一定觉得flink和storm有几分相似,确实是这样。那么有spark和storm这样成熟的计算框架存在,为什么flink还能占有一席之地呢?今天我们就从流处理的角度将flink和这两个框架进行一些分析和比较。
一:本文的流框架基于的实现方式
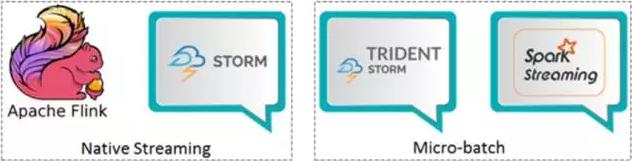
本文涉及的流框架基于的实现方式分为两大类。第一类是Native Streaming,这类引擎中所有的data在到来的时候就会被立即处理,一条接着一条(HINT: 狭隘的来说是一条接着一条,但流引擎有时会为提高性能缓存一小部分data然后一次性处理),其中的代表就是storm和flink。第二种则是基于Micro-batch,数据流被切分为一个一个小的批次, 然后再逐个被引擎处理。这些batch一般是以时间为单位进行切分,单位一般是‘秒‘,其中的典型代表则是spark了,不论是老的spark DStream还是2.0以后推出的spark structured streaming都是这样的处理机制;另外一个基于Micro-batch实现的就是storm trident,它是对storm的更高层的抽象,因为以batch为单位,所以storm trident的一些处理变的简单且高效。
二: 流框架比较的关键指标
从流处理的角度将flink与spark和storm这两个框架进行比较,会主要关注以下几点,后续的对比也主要基于这几点展开:
- 功能性(Functionality)- 是否能很好解决流处理功能上的痛点 , 比如event time和out of order data。
- 容错性(Fault Tolerance) - 在failure之后能否恢复到故障之前的状态,并输出一致的结果;此外容错的代价也是越低越好,因为其直接影响性能。 • 吞吐量(throughputs)& 延时(latency) - 性能相关的指标,高吞吐和低延迟某种意义上是不可兼得的,但好的流引擎应能兼顾高吞吐&低延时。
功能性(Functionality)
1 Event time&Window Operation
1.1Event time• event time - 指数据或者事件真正发生时间 , 比如用户点击网页时产生一条点击事件的数据,点击时间就是这条数据固有的event time。 • processing time - 指计算框架处理这条数据的时间。 (具体关于时间的定义可以参看flink文档 http://t.cn/RaTnsdy。)
spark DStream和storm 1.0以前版本往往都折中地使用processing time来近似地实现event time相关的业务。显然,使用processing time模拟event time必然会产生一些误差, 特别是在产生数据堆积的时候,误差则更明显,甚至导致计算结果不可用。
在使用event time时,自然而然需要解决由网络延迟等因素导致的迟到或者乱序数据的问题。为了解决这个问题, spark、storm及flink都参考streaming 102 (http://t.cn/RbQCUmJ)引入了watermark和lateness的概念。
watermark: 是引擎处理事件的时间进度,代表一种状态,一般随着数据中的event time的增长而增长。比如 watermark(t)代表整个流的event time处理进度已经到达t, 时间是有序的,那么streaming不应该会再收到timestamp t’ < t的数据,而只会接受到timestamp t’ >= t的数据。 如果收到一条timestamp t’ < t的数据, 那么就说明这条数据是迟到的。
lateness: 表示可以容忍迟到的程度,在lateness可容忍范围内的数据还会参与计算,超过的会被丢弃。
1.2Window Operation
下面主要比较在使用window的操作中,spark structured streaming 和flink对event time处理机制的不同。
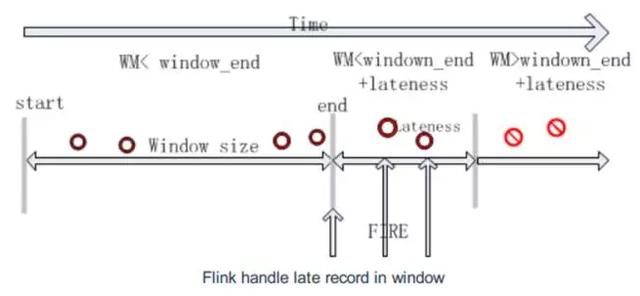
flink 首先,我们结合图来看flink, 时间轴从左往右增大。当watermark WM处于时 间窗口区间内时,即WM ∈ [start, end] , event time落在窗口范围内的任何乱序数据都会被接受;随着WM的增长并超过了窗口的结束时间,但还未超过可容忍的lateness时间范围,即WM ∈ (window_end,window_end+ lateness], 这时乱序数据仍然可以被接受; 只有当WM超过 window_end+lateness, 即WM ∈ (window_end+ lateness, ∞), 迟到的数据将会被丢弃。
fiink中watermark的计算也比较灵活,可以选择build-in的(如最大时间戳),也可以通过集成接口自定义实现。此外,用户可以选择周期性更新或者事件触发更新watermark。
spark 首先,spark中watermark是通过上一个batch最大的timestamp再减去lateness得到的,即watermark = Max(last batch timestamps) - lateness。当数据的event time大于watermark时,数据会被接受,否则不论这条数据属于哪个窗口都会被丢弃。细节请参考spark文档 (http://t.cn/RaTnvVQ)。
下面来比较一下两者实现细节上的不同:
- lateness定义: 在spark中,迟到被定义为data的event time和watermark的比较结果,当data的event time < watermark时,data被丢弃;flink中只有在watermark > window_end + lateness的时候,data才会被丢弃。
- watermark更新: spark中watermark是上个batch中的max event time,存在延迟;而在flink中是可以做到每条数据同步更新watermark。
- window触发: flink中window计算会触发一次或多次,第一次在watermark >= window_end后立刻触发(main fire),接着会在迟到数据到来后进行增量触发。spark只会在watermark(包含lateness)过了window_end之后才会触发,虽然计算结果一次性正确,但触发比flink起码多了一个lateness的延迟。
上面三点可见flink在设计event time处理模型还是较优的:watermark的计算实时性高,输出延迟低,而且接受迟到数据没有spark那么受限。不光如此,flink提供的window programming模型非常的灵活,不但支持spark、storm没有的session window,而且只要实现其提供的WindowAssigner、Trigger、Evictor就能创造出符合自身业务逻辑的window,功能非常强大。
2 SQL API
目前flink相比spark,对streaming sql的支持还是比较初级的。在当前最新1.2版本中,仅支持Selection、Projection、Union、Tumble,不支持Aggregation、 Join、Top N、 Sort。计划中1.3版本将支持 Window Aggregation(sum、max、 min、avg), 但依然不支持Distinct。相比flink,当前最新版本的spark structured streaming仅仅不支持Top N、Distinct。
3 Kafka Source Integration
flink对于kafka的兼容性非常好,支持kafka 0.8、0.9、0.10;相反,spark structured streaming只支持kafka0.10或更高版本。
4 Interoperation with Static Data
spark底层对static batch data和streaming data有共同的rdd抽象,完美兼容互操作。而flink中DataSet 和 DataStream是完全独立的,不可以直接交互。
此外,flink还可以运行storm的topology,带来较强的移植性。另外一个有趣的功能是可以自由调整job latency and throughputs的取舍关系,比如需要high throughputs的程序可以牺牲latency来获得更大的throughputs。
容错性(Fault Tolerance)
spark依赖checkpoint机制来进行容错,只要batch执行到doCheckpoint操作前挂了,那么该batch就会被完整的重新计算。spark可以保证计算过程的exactly once(不包含sink的exactly once)。
storm的容错通过ack机制实现,每个bolt或spout处理完成一条data后会发送一条ack消息给acker bolt。当该条data被所有节点都处理过后,它会收到来自所有节点ack, 这样一条data处理就是成功的。storm可以保证数据不丢失,但是只能达到at least once语义。此外,因为需要每条data都做ack,所以容错的开销很大。storm trident是基于micro¬batched实现了exactly once语义。
flink使用Chandy-Chandy-Lamport Algorithm 来做Asynchronous Distributed Snapshots(异步分布式快照),其本质也是checkpoint。如下图,flink定时往流里插入一个barrier(隔栏),这些barriers把数据分割成若干个小的部分,当barrier流到某个operator时,operator立即会对barrier对应的一小部分数据做checkpoint并且把barrier传给下游(checkpoint操作是异步的,并不会打断数据的处理),直到所有的sink operator做完自己checkpoint后,一个完整的checkpoint才算完成。当出现failure时,flink会从最新完整的checkpoint点开始恢复。
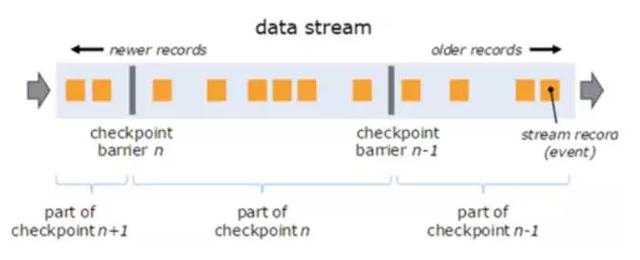
flink的checkpoint机制非常轻量,barrier不会打断streaming的流动,而且做checkpoint操作也是异步的。其次,相比storm需要ack每条data,flink做的是small batch的checkpoint,容错的代价相对要低很多。最重要的是flink的checkpoint机制能保证exactly once。
吞吐量和延迟(Throughputs& Latency)
1 .1吞吐量(throughputs)
spark是mirco-batch级别的计算,各种优化做的也很好,它的throughputs是最大的。但是需要提一下,有状态计算(如updateStateByKey算子)需要通过额外的rdd来维护状态,导致开销较大,对吞吐量影响也较大。
storm的容错机制需要对每条data进行ack,因此容错开销对throughputs影响巨大,throughputs下降甚至可以达到70%。storm trident是基于micro-batch实现的,throughput中等。
flink的容错机制较为轻量,对throughputs影响较小,而且拥有图和调度上的一些优化机制,使得flink可以达到很高 throughputs。
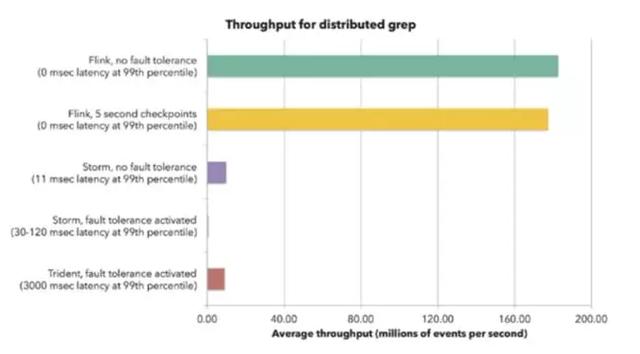
下图是flink官网给出的storm和flink的benchmark,我们可以看出storm在打开ack容错机制后,throughputs下降非常明显。而flink在开启checkpoint和关闭的情况下throughputs变化不大,说明flink的容错机制确实代价不高。对比官网的benchmark,我们也进行了throughputs的测试,实测结果是flink throughputs是storm的3.5倍,而且在解除了kafka集群和flink集群的带宽瓶颈后,flink自身又提高了1.6倍。
1.2延迟(latency)
- spark基于micro-batch实现,提高了throughputs,但是付出了latency的代价。一般spark的latency是秒级别的。
- storm是native streaming实现,可以轻松的达到几十毫秒级别的latency,在几款框架中它的latency是最低的。storm trident是基于micro-batch实现的,latency较高。
- flink也是native streaming实现,也可以达到百毫秒级别的latency。
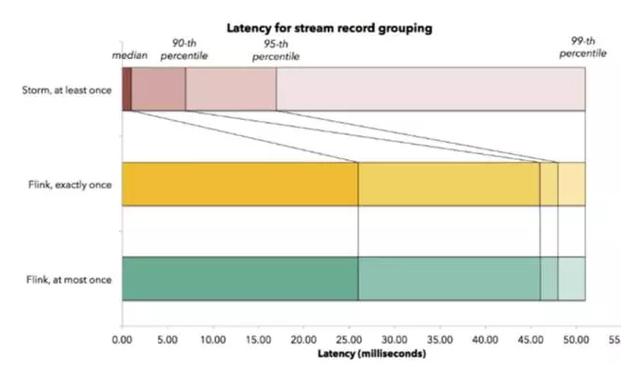
下图是flink官网给出的和storm的latency对比benchmark。storm可以达到平均5毫秒以内的latency,而flink的平均latency也在30毫秒以内。两者的99%的data都在55毫秒latency内处理完成,表现都很优秀。
三:总 结
综合对比spark、storm和flink的功能、容错和性能(总结如下图)
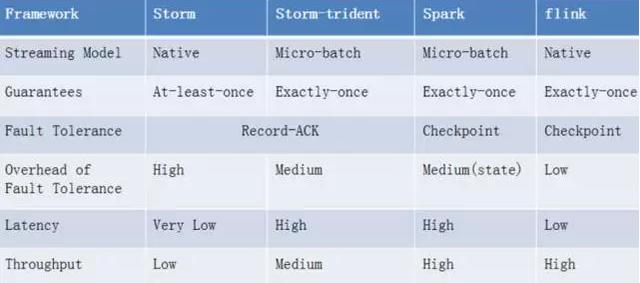
不难发现, flink是一个设计良好的框架,它不但功能强大,而且性能出色。此外它还有一些比较好设计,比如优秀的内存管理和流控。但是,flink目前成熟度较低,还存在着不少问题,比如 SQL支持比较初级;无法像storm一样在不停止任务的情况下动态调整资源;不能像spark一样提供很好的streaming和static data的交互操作等。对于这些问题,flink社区还在积极的跟进,相信在更多公司和贡献者的共同努力下,flink会发展的越来越好。





















