集 Tabular 显示实验结果、自定义备忘、前端操作删除/隐藏记录、自动 git commit 等诸多功能于一体,这个调参神器助你高效「炼出金丹」。
「有没有什么可以节省大量时间的 Deep Learning 效率神器?」有人在知乎上问出了这样一个问题。在回答区,复旦大学计算机科学技术学院副教授邱锡鹏介绍了他们实验室内部使用的调参利器——fitlog。

fitlog 是一款集成了自动版本管理和自动日志记录两种功能的 Python 包,由复旦大学计算机科学技术学院自然语言处理与深度学习组的 fastNLP 团队开发的。它可以帮助你在进行实验时方便地保存当前的代码、参数和结果。
根据邱锡鹏老师的介绍,fitlog 有很多非常实用的功能,如用 Tabular 显示实验结果;在后台自动 git commit 代码;超参数可视化;架构无关,TensorFlow、Pytorch 都支持……
如果实验效果不理想,fitlog 还支持前端操作删除、隐藏记录,让网友高呼「优秀」。
而且,figlog 的安装非常简单,使用 pip install fitlog 即可完成安装。
- GitHub 地址:https://github.com/fastnlp/fitlog
- 中文文档:https://fitlog.readthedocs.io/zh/latest/
fitlog 到底有多好用
想必机器之心的读者都不会对 TensorBoard 感到陌生,它为我们提供了一个高效调参的途径。虽然 TensorBoard 功能强大、界面美观,但仍无法满足我们日常所有的「炼丹」需求。使用 fitlog 或许能够解决一些深度学习中调参的痛点,下面我们来看一看它都有些什么功能。
用 Tabular 显示实验结果
fitlog 支持利用 Tabular 显示实验结果,方便不同超参数之间的对比。如下图所示,表中的每一行代表一次实验:
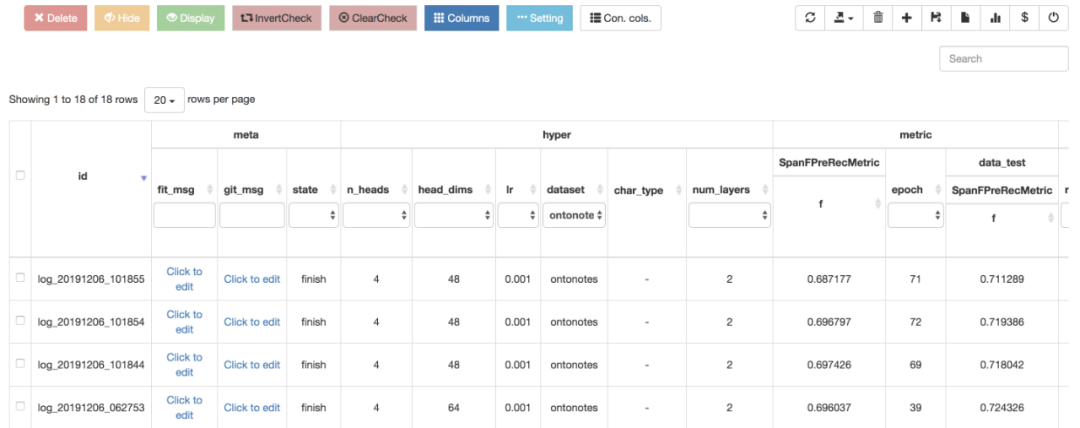
具体来说,fitlog 可以:
- 支持 group 操作,方便查看某种特定数据集或参数的性能;
- 支持排序,最强超参数一目了然;
- 支持 column 顺序、显示自定义,拯救强迫症;
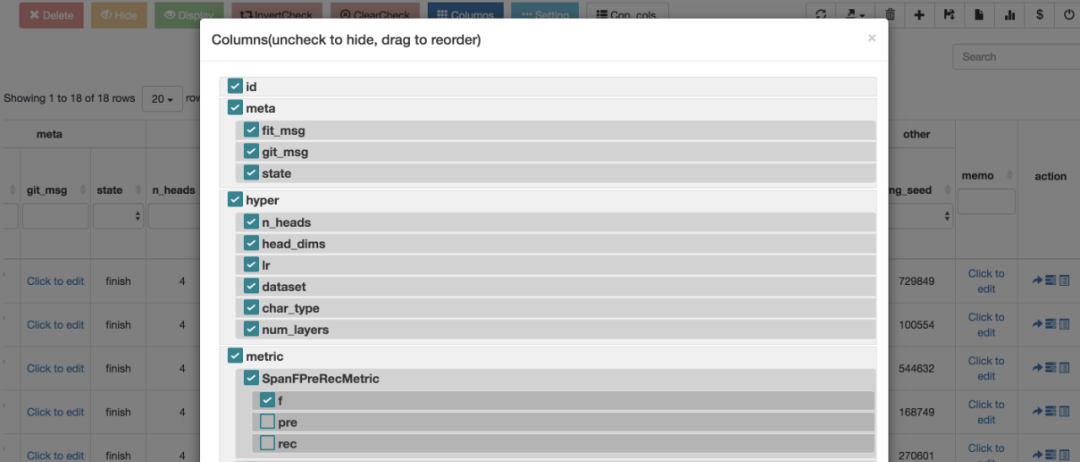
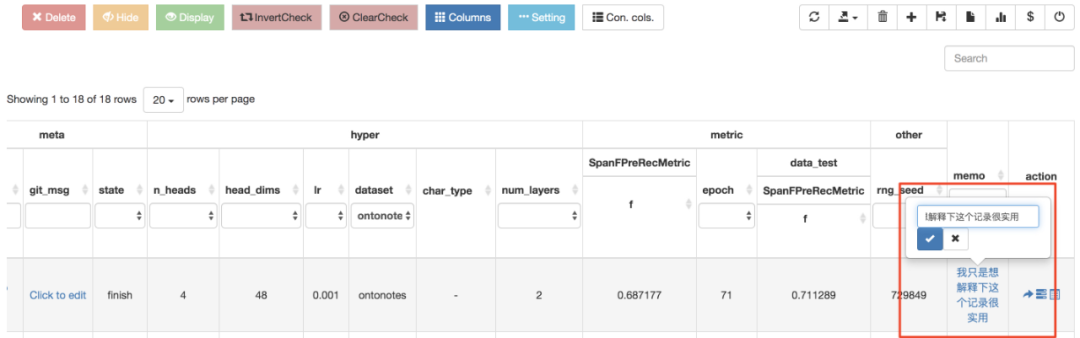
4. 支持针对某条实验自定义备忘;
5. 支持前端加入别人实验的性能数据,方便与 SOTA 结果对比;
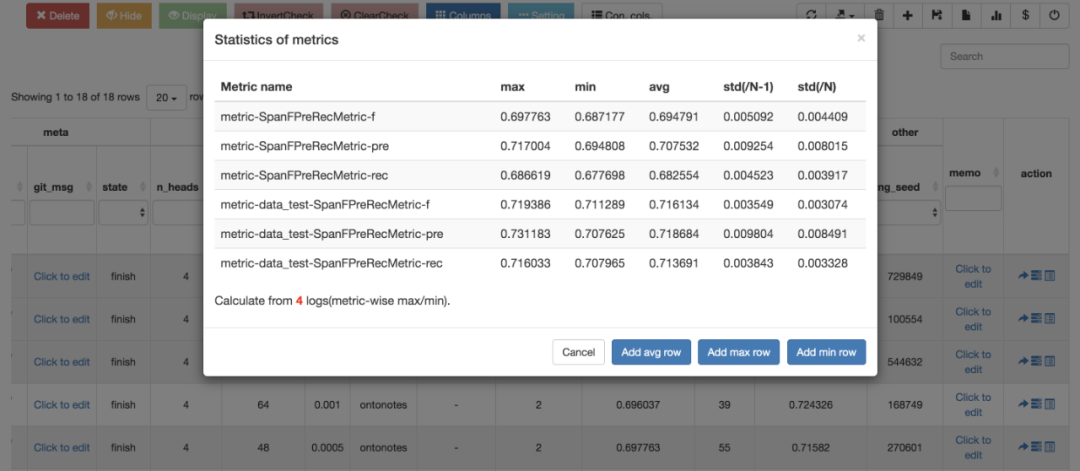
6. 支持计算平均值、标准差;
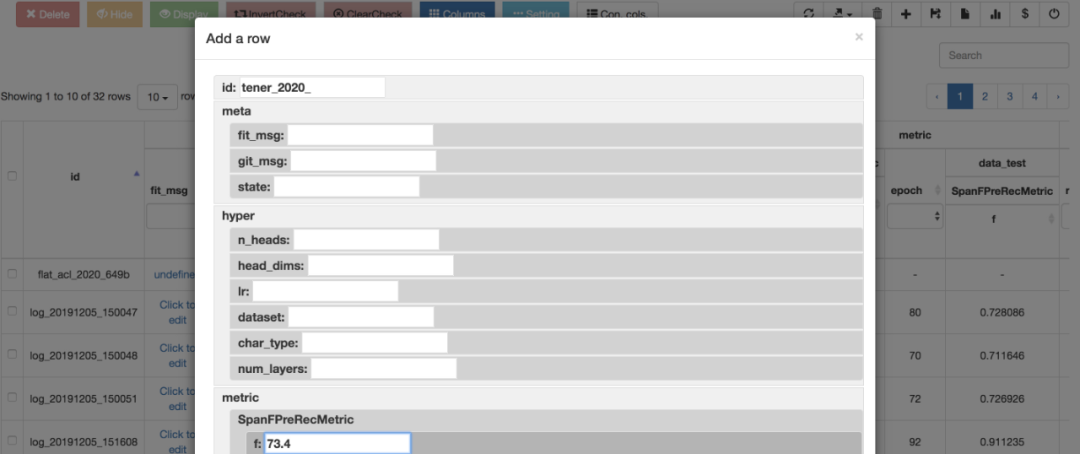
7. 如果实验结果不理想,fitlog 支持前端操作删除、隐藏记录;
8. 支持导出 excel、csv、txt、json 等格式,满足分析需求;
9. 记录 metric
机器学习不可避免地需要使用一些如 loss 之类的关键 metric,以便让我们了解训练过程是如何进行的。这些 metric 能够帮助我们判断模型是否已经过拟合或仍存在可提升的空间。并且,通过比较这些 metric 能够帮助我们进行超参数的调整、提高模型性能。
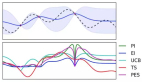
下图为使用 fitlog 记录的 metric:
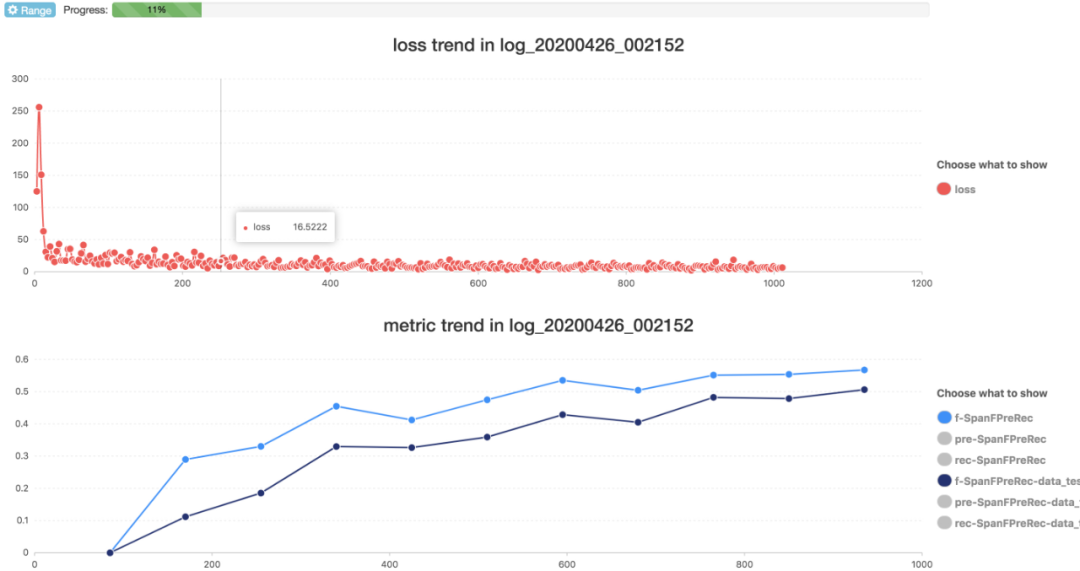
下图为使用 TensorBoard 的 scalars 记录示意图:
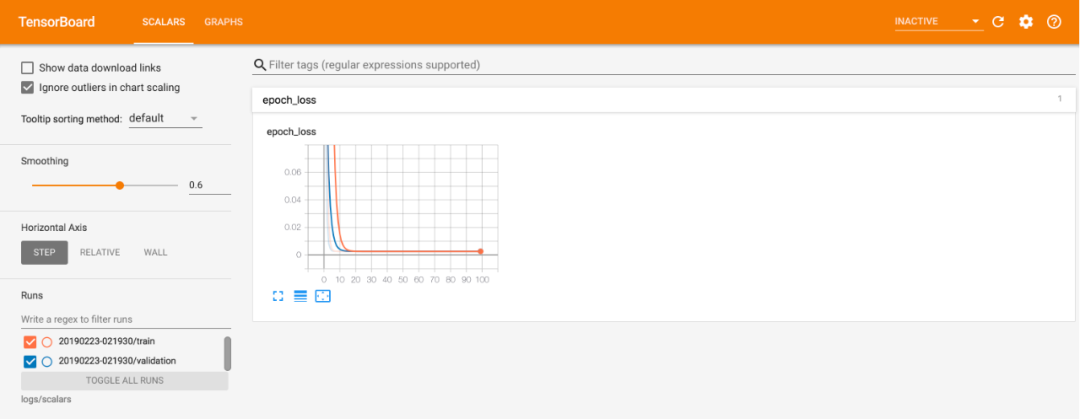
从以上两幅图中可以看到,在记录 metric 方面来说,fitlog 与 TensorBoard 的体验是比较接近的。
支持在后台自动 git commit 代码
要想复现实验结果,只有超参数是不够的,所以 fitlog 支持在后台为用户自动 git commit 代码(fitlog 借助 git 进行代码管理,但与开发者自己管理的 git 不冲突,是并行的)。如果需要回退到某次实验的代码,直接前端点击「回退」就可以搞定。fitlog 甚至可以帮用户管理随机数种子,但 pytorch 等深度学习框架本身的随机性无法解决。
超参数可视化
深度学习涉及大量的超参数调整。有时候,一组好的超参数组合带来的性能提升,甚至要超过部分算法的改进。因此,记录下这些超参数对于模型性能的影响显得至关重要。选定一个 metric,可视化地展示出在不同超参数组合下,这个 metric 的变化趋势,能够极大地提高我们进行超参数搜索的效率。而 fitlog 正好可以提供你需要的可视化(下图中的每条线代表一次实验,最左侧是 dev 上的性能)。
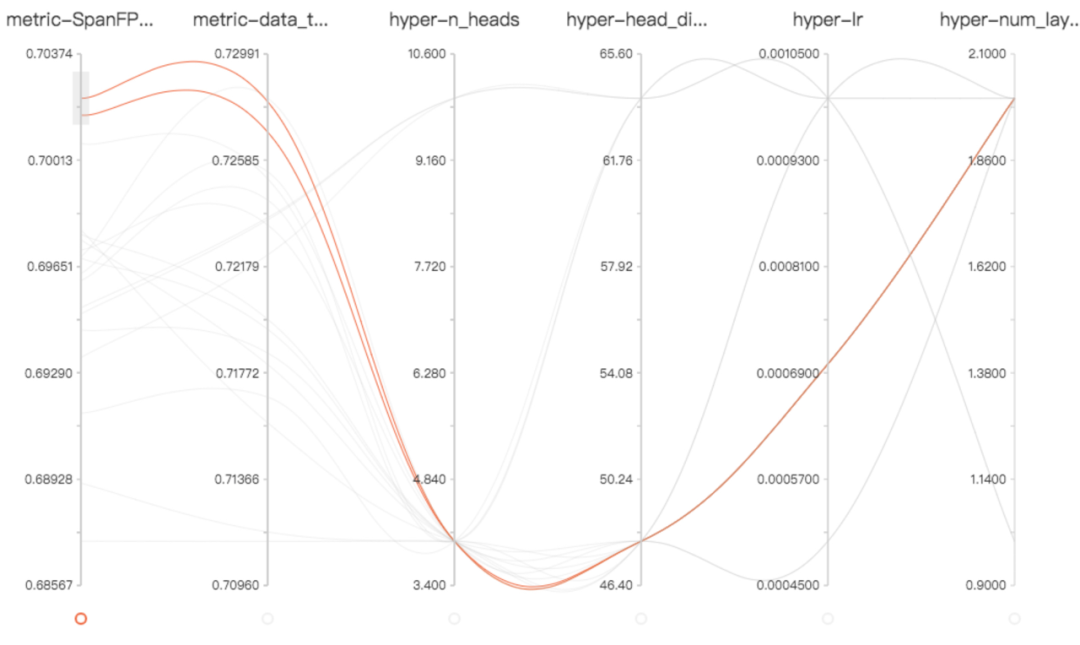
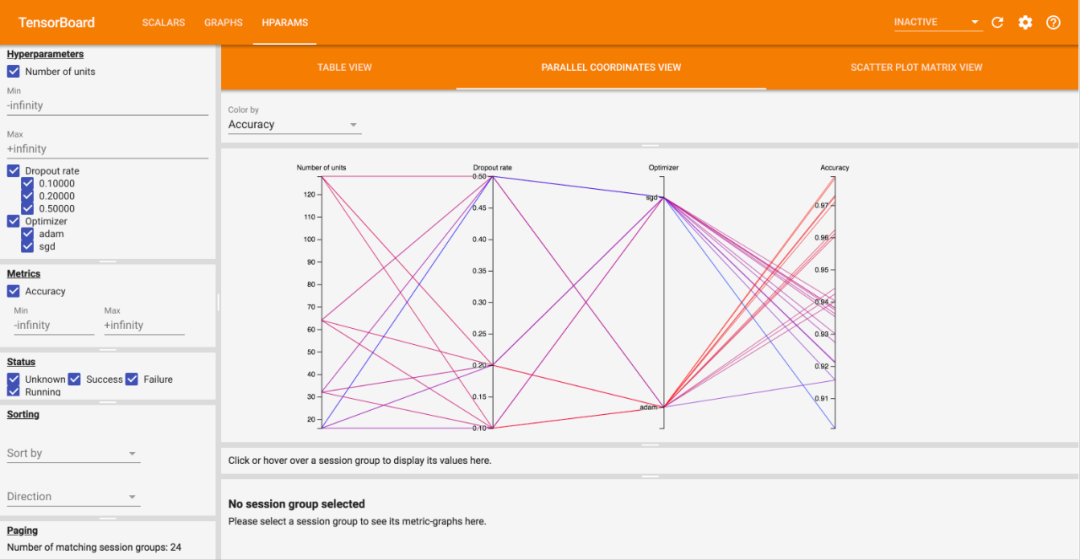
该功能类似于 TensorBoard 中的 HParams,如下图所示:
架构无关,TensorFlow、PyTorch 都能用
fitlog 是架构无关的,tensorflow 和 pytorch 都能使用。除了自然语言处理,它还能用于计算机视觉任务。如果是自然语言处理任务,可以配合 fastNLP 框架一起使用,只需要增加三五行代码便可以实现 metric、loss 的自动记录。
有待提升的地方
作为一个轻量级的工具,fitlog 也有自身的缺点,如:
- 不支持保存 model 输出的图片,但是支持查看训练过程中的文本输出;
- 不支持除了 loss 与 metric 以外的曲线的展示。
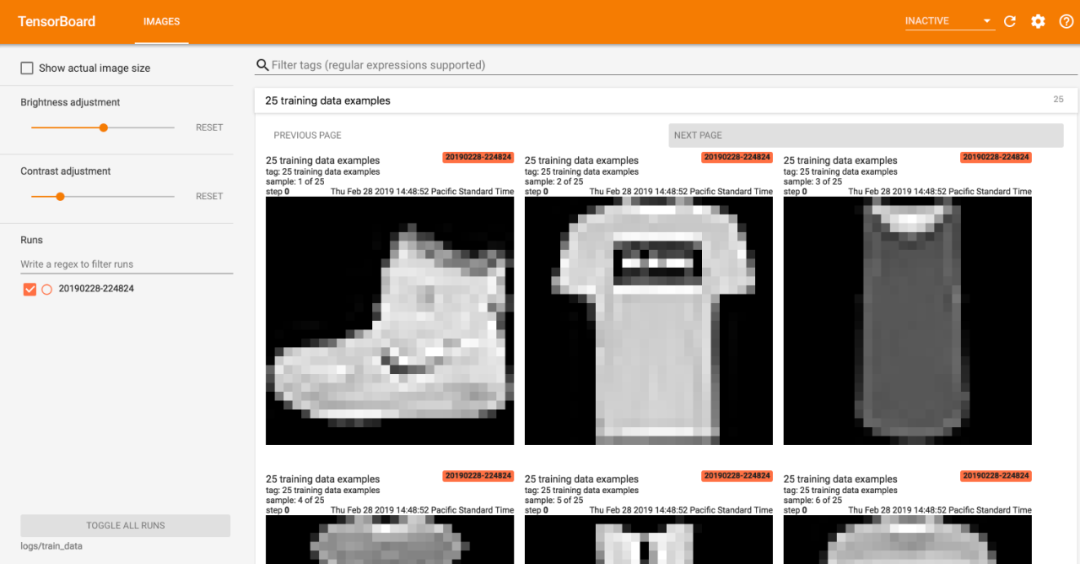
例如,当我们需要查看输入数据、可视化网络层权重时,图像的记录与显示会非常有帮助。下图展示了在 TensorBoard 中显示 Fashion-MNIST 数据集里的部分图片:
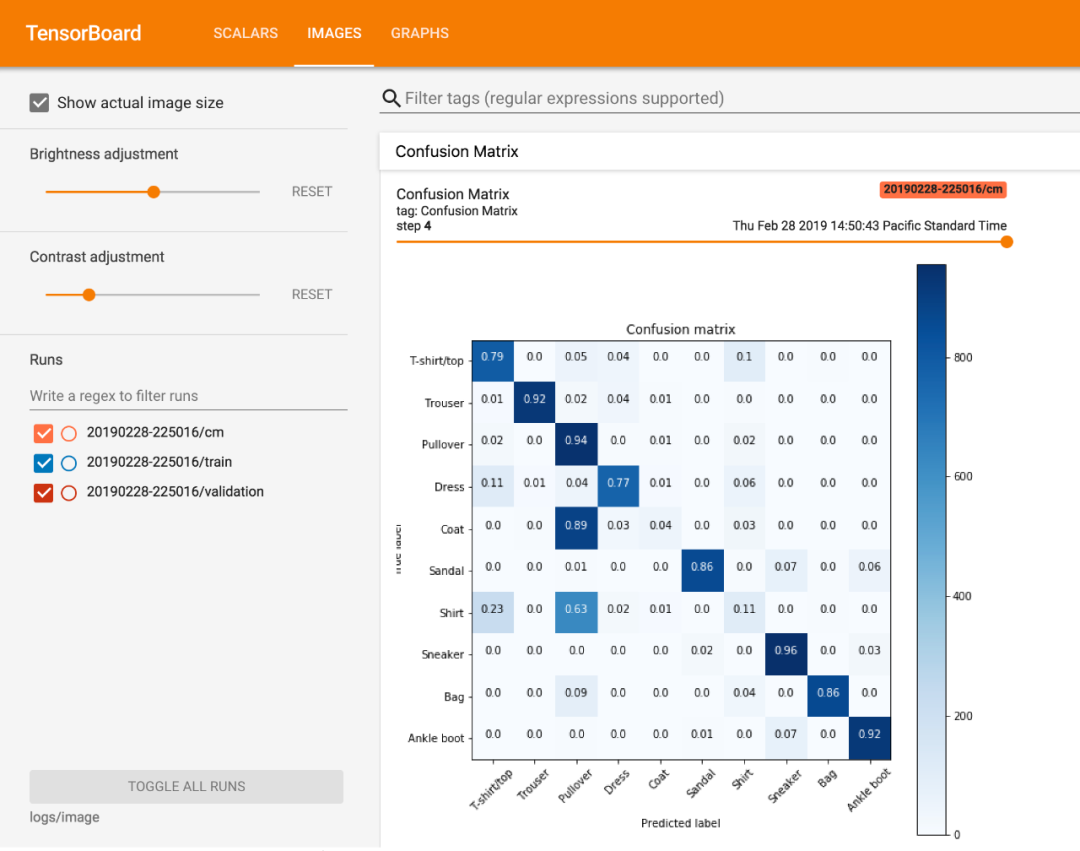
此外,可视化展示混淆矩阵(confusion matrix)对于分类模型的调参也很有帮助。混淆矩阵是机器学习中用来总结分类模型预测结果的分析手段之一,其使用矩阵的形式将真实类别与模型预测的类别进行汇总,让我们能够较为直观地了解模型在哪些样本的预测上表现不是很好。从下图中可以较明显地看出,该分类模型将 Shirts、T-Shirts 和 Pullovers 弄混了,模型的预测性能有待改进。
以上功能是 fitlog 所不具备的,如果这对于你来说是必不可少的功能的话,目前来说可能还是得选择 TensorBoard。